 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT-NeRF: Constancy-Aware Tx$^2$Former for Dynamic Body Modeling
Paper and Code
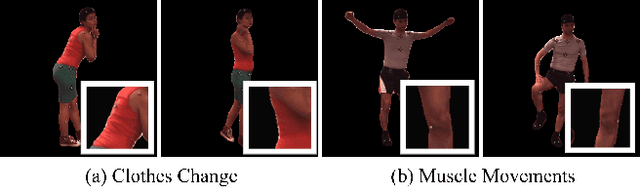
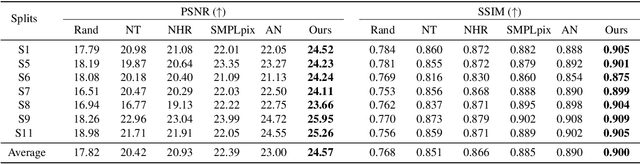
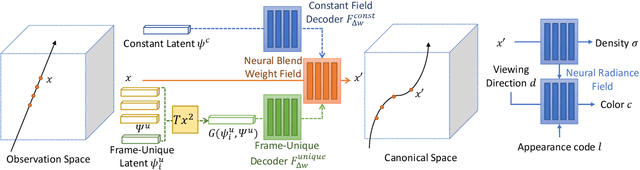
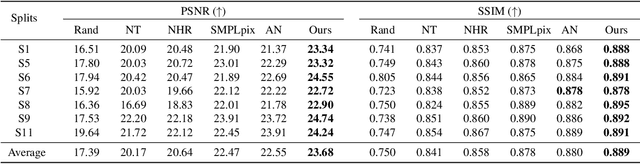
This paper addresses the problem of human rendering in the video with temporal appearance constancy. Reconstructing dynamic body shapes with volumetric neural rendering methods, such as NeRF, requires finding the correspondence of the points in the canonical and observation space, which demands understanding human body shape and motion. Some methods use rigid transformation, such as SE(3), which cannot precisely model each frame's unique motion and muscle movements. Others generate the transformation for each frame with a trainable network, such as neural blend weight field or translation vector field, which does not consider the appearance constancy of general body shape. In this paper, we propose CAT-NeRF for self-awareness of appearance constancy with Tx$^2$Former, a novel way to combine two Transformer layers, to separate appearance constancy and uniqueness. Appearance constancy models the general shape across the video, and uniqueness models the unique patterns for each frame. We further introduce a novel Covariance Loss to limit the correlation between each pair of appearance uniquenesses to ensure the frame-unique pattern is maximally captured in appearance uniqueness. We assess our method on H36M and ZJU-MoCap and show state-of-the-art performance.