 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift-AR: Single-Step Visual Autoregressive Generation via Anti-Symmetric Drifting
Mar 30, 2026Autoregressive (AR)-Diffusion hybrid paradigms combine AR's structured semantic modeling with diffusion's high-fidelity synthesis, yet suffer from a dual speed bottleneck: the sequential AR stage and the iterative multi-step denoising of the diffusion vision decode stage. Existing methods address each in isolation without a unified principle design. We observe that the per-position \emph{prediction entropy} of continuous-space AR models naturally encodes spatially varying generation uncertainty, which simultaneously governing draft prediction quality in the AR stage and reflecting the corrective effort required by vision decoding stage, which is not fully explored before. Since entropy is inherently tied to both bottlenecks, it serves as a natural unifying signal for joint acceleration. In this work, we propose \textbf{Drift-AR}, which leverages entropy signal to accelerate both stages: 1) for AR acceleration, we introduce Entropy-Informed Speculative Decoding that align draft--target entropy distributions via a causal-normalized entropy loss, resolving the entropy mismatch that causes excessive draft rejection; 2) for visual decoder acceleration, we reinterpret entropy as the \emph{physical variance} of the initial state for an anti-symmetric drifting field -- high-entropy positions activate stronger drift toward the data manifold while low-entropy positions yield vanishing drift -- enabling single-step (1-NFE) decoding without iterative denoising or distillation. Moreover, both stages share the same entropy signal, which is computed once with no extra cost. Experiments on MAR, TransDiff, and NextStep-1 demonstrate 3.8--5.5$\times$ speedup with genuine 1-NFE decoding, matching or surpassing original quality. Code will be available at https://github.com/aSleepyTree/Drift-AR.
PhotoAgent: Agentic Photo Editing with Exploratory Visual Aesthetic Planning
Feb 26, 2026With the recent fast development of generative models, instruction-based image editing has shown great potential in generating high-quality images. However, the quality of editing highly depends on carefully designed instructions, placing the burden of task decomposition and sequencing entirely on the user. To achieve autonomous image editing, we present PhotoAgent, a system that advances image editing through explicit aesthetic planning. Specifically, PhotoAgent formulates autonomous image editing as a long-horizon decision-making problem. It reasons over user aesthetic intent, plans multi-step editing actions via tree search, and iteratively refines results through closed-loop execution with memory and visual feedback, without requiring step-by-step user prompts. To support reliable evaluation in real-world scenarios, we introduce UGC-Edit, an aesthetic evaluation benchmark consisting of 7,000 photos and a learned aesthetic reward model. We also construct a test set containing 1,017 photos to systematically assess autonomous photo editing performance. Extensive experiments demonstrate that PhotoAgent consistently improves both instruction adherence and visual quality compared with baseline methods. The project page is https://github.com/mdyao/PhotoAgent.
Group Critical-token Policy Optimization for Autoregressive Image Generation
Sep 26, 2025Recent studies have extended Reinforcement Learning with Verifiable Rewards (RLVR) to autoregressive (AR) visual generation and achieved promising progress. However, existing methods typically apply uniform optimization across all image tokens, while the varying contributions of different image tokens for RLVR's training remain unexplored. In fact, the key obstacle lies in how to identify more critical image tokens during AR generation and implement effective token-wise optimization for them. To tackle this challenge, we propose $\textbf{G}$roup $\textbf{C}$ritical-token $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{GCPO}$), which facilitates effective policy optimization on critical tokens. We identify the critical tokens in RLVR-based AR generation from three perspectives, specifically: $\textbf{(1)}$ Causal dependency: early tokens fundamentally determine the later tokens and final image effect due to unidirectional dependency; $\textbf{(2)}$ Entropy-induced spatial structure: tokens with high entropy gradients correspond to image structure and bridges distinct visual regions; $\textbf{(3)}$ RLVR-focused token diversity: tokens with low visual similarity across a group of sampled images contribute to richer token-level diversity. For these identified critical tokens, we further introduce a dynamic token-wise advantage weight to encourage exploration, based on confidence divergence between the policy model and reference model. By leveraging 30\% of the image tokens, GCPO achieves better performance than GRPO with full tokens. Extensive experiments on multiple text-to-image benchmarks for both AR models and unified multimodal models demonstrate the effectiveness of GCPO for AR visual generation.
Diffusion-Promoted HDR Video Reconstruction
Jun 12, 2024



High dynamic range (HDR) video reconstruction aims to generate HDR videos from low dynamic range (LDR) frames captured with alternating exposures. Most existing works solely rely on the regression-based paradigm, leading to adverse effects such as ghosting artifacts and missing details in saturated regions. In this paper, we propose a diffusion-promoted method for HDR video reconstruction, termed HDR-V-Diff, which incorporates a diffusion model to capture the HDR distribution. As such, HDR-V-Diff can reconstruct HDR videos with realistic details while alleviating ghosting artifacts. However, the direct introduction of video diffusion models would impose massive computational burden. Instead, to alleviate this burden, we first propose an HDR Latent Diffusion Model (HDR-LDM) to learn the distribution prior of single HDR frames. Specifically, HDR-LDM incorporates a tonemapping strategy to compress HDR frames into the latent space and a novel exposure embedding to aggregate the exposure information into the diffusion process. We then propose a Temporal-Consistent Alignment Module (TCAM) to learn the temporal information as a complement for HDR-LDM, which conducts coarse-to-fine feature alignment at different scales among video frames. Finally, we design a Zero-Init Cross-Attention (ZiCA) mechanism to effectively integrate the learned distribution prior and temporal information for generating HDR frames. Extensive experiments validate that HDR-V-Diff achieves state-of-the-art results on several representative datasets.
Uni-ISP: Unifying the Learning of ISPs from Multiple Cameras
Jun 03, 2024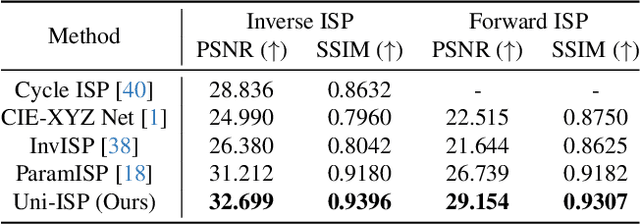
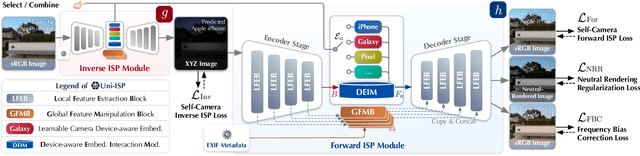
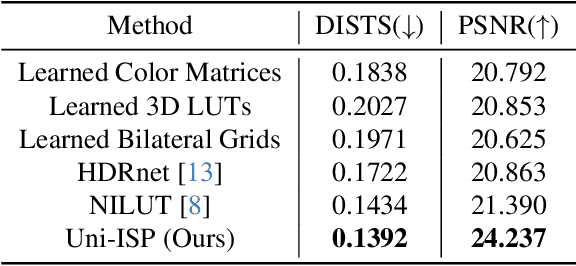

Modern end-to-end image signal processors (ISPs) can learn complex mappings from RAW/XYZ data to sRGB (or inverse), opening new possibilities in image processing. However, as the diversity of camera models continues to expand, developing and maintaining individual ISPs is not sustainable in the long term, which inherently lacks versatility, hindering the adaptability to multiple camera models. In this paper, we propose a novel pipeline, Uni-ISP, which unifies the learning of ISPs from multiple cameras, offering an accurate and versatile processor to multiple camera models. The core of Uni-ISP is leveraging device-aware embeddings through learning inverse/forward ISPs and its special training scheme. By doing so, Uni-ISP not only improves the performance of inverse/forward ISPs but also unlocks a variety of new applications inaccessible to existing learned ISPs. Moreover, since there is no dataset synchronously captured by multiple cameras for training, we construct a real-world 4K dataset, FiveCam, comprising more than 2,400 pairs of sRGB-RAW images synchronously captured by five smartphones. We conducted extensive experiments demonstrating Uni-ISP's accuracy in inverse/forward ISPs (with improvements of +1.5dB/2.4dB PSNR), its versatility in enabling new applications, and its adaptability to new camera models.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024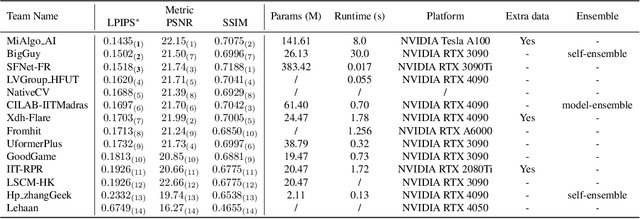
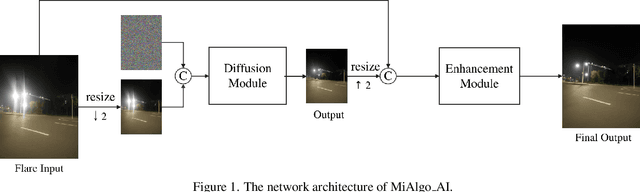
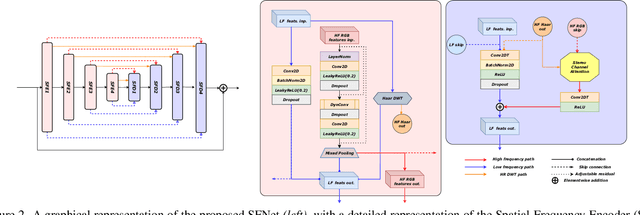
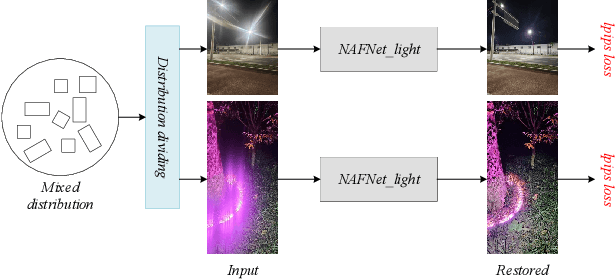
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Neural Degradation Representation Learning for All-In-One Image Restoration
Oct 19, 2023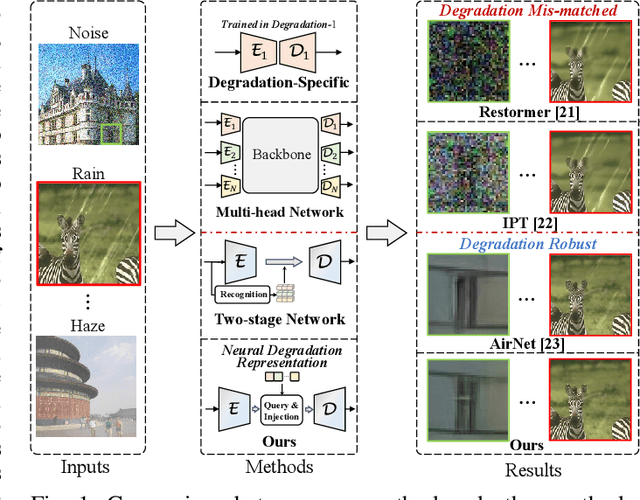
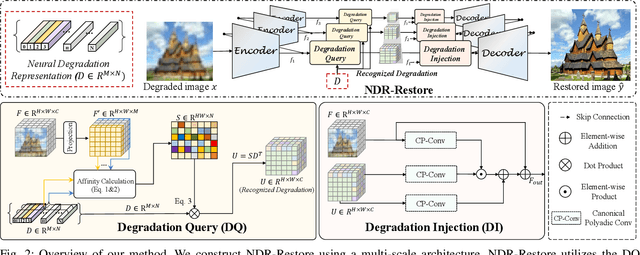
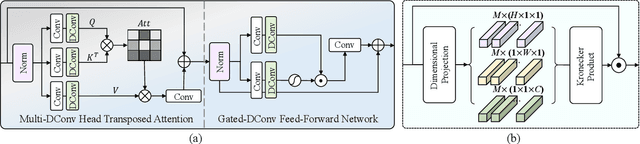
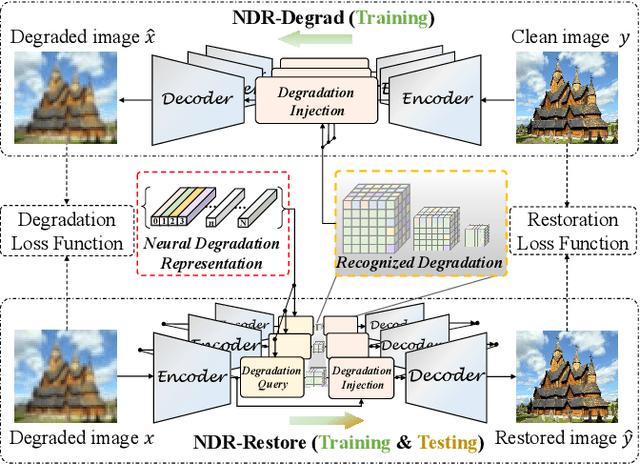
Existing methods have demonstrated effective performance on a single degradation type. In practical applications, however, the degradation is often unknown, and the mismatch between the model and the degradation will result in a severe performance drop. In this paper, we propose an all-in-one image restoration network that tackles multiple degradations. Due to the heterogeneous nature of different types of degradations, it is difficult to process multiple degradations in a single network. To this end, we propose to learn a neural degradation representation (NDR) that captures the underlying characteristics of various degradations. The learned NDR decomposes different types of degradations adaptively, similar to a neural dictionary that represents basic degradation components. Subsequently, we develop a degradation query module and a degradation injection module to effectively recognize and utilize the specific degradation based on NDR, enabling the all-in-one restoration ability for multiple degradations. Moreover, we propose a bidirectional optimization strategy to effectively drive NDR to learn the degradation representation by optimizing the degradation and restoration processes alternately. Comprehensive experiments on representative types of degradations (including noise, haze, rain, and downsampling) demonstrate the effectiveness and generalization capability of our method.
Mutual-Guided Dynamic Network for Image Fusion
Sep 01, 2023



Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
Generalized Lightness Adaptation with Channel Selective Normalization
Aug 26, 2023



Lightness adaptation is vital to the success of image processing to avoid unexpected visual deterioration, which covers multiple aspects, e.g., low-light image enhancement, image retouching, and inverse tone mapping. Existing methods typically work well on their trained lightness conditions but perform poorly in unknown ones due to their limited generalization ability. To address this limitation, we propose a novel generalized lightness adaptation algorithm that extends conventional normalization techniques through a channel filtering design, dubbed Channel Selective Normalization (CSNorm). The proposed CSNorm purposely normalizes the statistics of lightness-relevant channels and keeps other channels unchanged, so as to improve feature generalization and discrimination. To optimize CSNorm, we propose an alternating training strategy that effectively identifies lightness-relevant channels. The model equipped with our CSNorm only needs to be trained on one lightness condition and can be well generalized to unknown lightness conditions. Experimental results on multiple benchmark datasets demonstrate the effectiveness of CSNorm in enhancing the generalization ability for the existing lightness adaptation methods. Code is available at https://github.com/mdyao/CSNorm.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
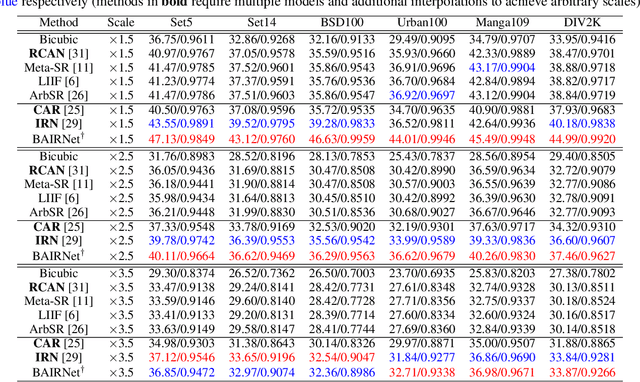
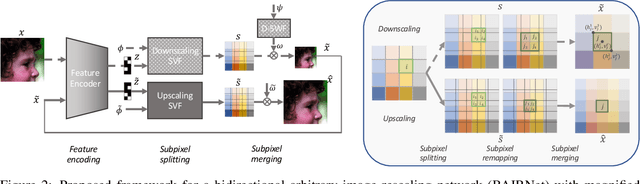

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.