 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSANet: Dynamic Segment Aggregation Network for Video-Level Representation Learning
Paper and Code
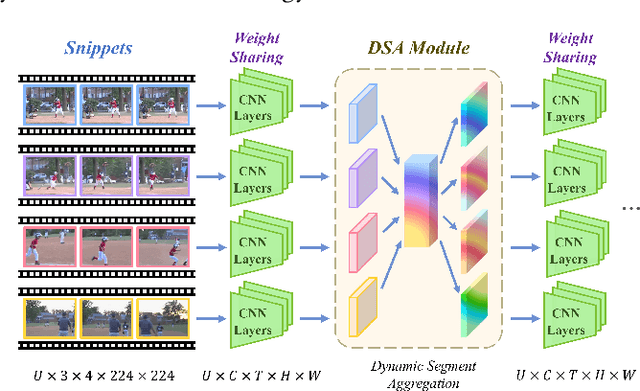
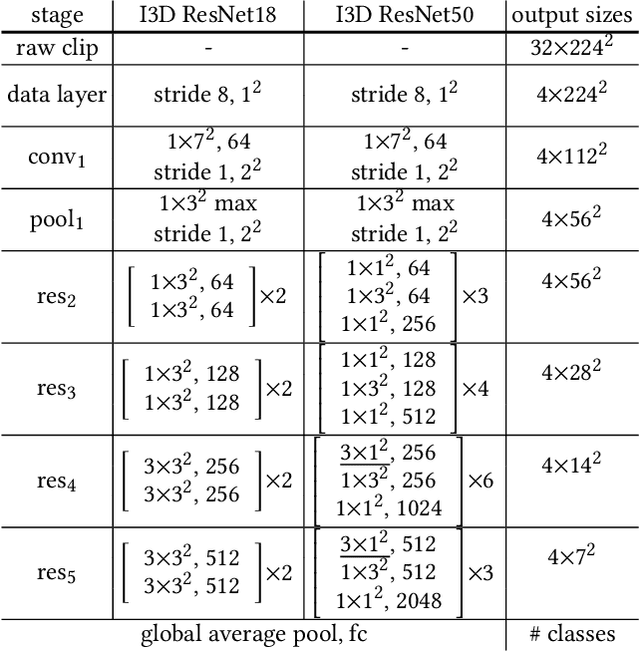
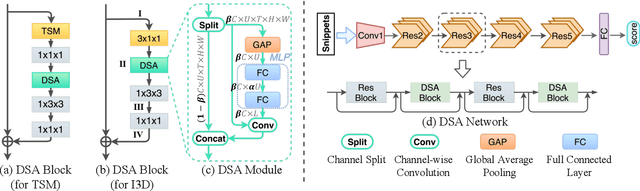
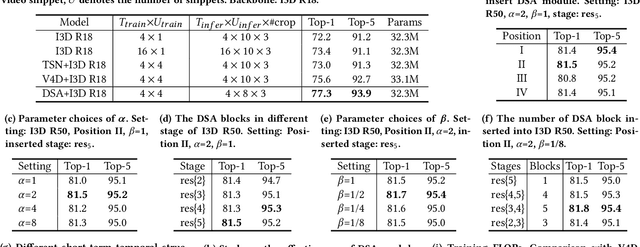
Long-range and short-range temporal modeling are two complementary and crucial aspects of video recognition. Most of the state-of-the-arts focus on short-range spatio-temporal modeling and then average multiple snippet-level predictions to yield the final video-level prediction. Thus, their video-level prediction does not consider spatio-temporal features of how video evolves along the temporal dimension. In this paper, we introduce a novel Dynamic Segment Aggregation (DSA) module to capture relationship among snippets. To be more specific, we attempt to generate a dynamic kernel for a convolutional operation to aggregate long-range temporal information among adjacent snippets adaptively. The DSA module is an efficient plug-and-play module and can be combined with the off-the-shelf clip-based models (i.e., TSM, I3D) to perform powerful long-range modeling with minimal overhead. The final video architecture, coined as DSANet. We conduct extensive experiments on several video recognition benchmarks (i.e., Mini-Kinetics-200, Kinetics-400, Something-Something V1 and ActivityNet) to show its superiority. Our proposed DSA module is shown to benefit various video recognition models significantly. For example, equipped with DSA modules, the top-1 accuracy of I3D ResNet-50 is improved from 74.9% to 78.2% on Kinetics-400. Codes will be available.