 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-based Light Field Super-Resolution with Efficient Subspace Scanning
Jun 23, 2024



Transformer-based methods have demonstrated impressive performance in 4D light field (LF) super-resolution by effectively modeling long-range spatial-angular correlations, but their quadratic complexity hinders the efficient processing of high resolution 4D inputs, resulting in slow inference speed and high memory cost. As a compromise, most prior work adopts a patch-based strategy, which fails to leverage the full information from the entire input LFs. The recently proposed selective state-space model, Mamba, has gained popularity for its efficient long-range sequence modeling. In this paper, we propose a Mamba-based Light Field Super-Resolution method, named MLFSR, by designing an efficient subspace scanning strategy. Specifically, we tokenize 4D LFs into subspace sequences and conduct bi-directional scanning on each subspace. Based on our scanning strategy, we then design the Mamba-based Global Interaction (MGI) module to capture global information and the local Spatial- Angular Modulator (SAM) to complement local details. Additionally, we introduce a Transformer-to-Mamba (T2M) loss to further enhance overall performance. Extensive experiments on public benchmarks demonstrate that MLFSR surpasses CNN-based models and rivals Transformer-based methods in performance while maintaining higher efficiency. With quicker inference speed and reduced memory demand, MLFSR facilitates full-image processing of high-resolution 4D LFs with enhanced performance.
Diffusion-Promoted HDR Video Reconstruction
Jun 12, 2024



High dynamic range (HDR) video reconstruction aims to generate HDR videos from low dynamic range (LDR) frames captured with alternating exposures. Most existing works solely rely on the regression-based paradigm, leading to adverse effects such as ghosting artifacts and missing details in saturated regions. In this paper, we propose a diffusion-promoted method for HDR video reconstruction, termed HDR-V-Diff, which incorporates a diffusion model to capture the HDR distribution. As such, HDR-V-Diff can reconstruct HDR videos with realistic details while alleviating ghosting artifacts. However, the direct introduction of video diffusion models would impose massive computational burden. Instead, to alleviate this burden, we first propose an HDR Latent Diffusion Model (HDR-LDM) to learn the distribution prior of single HDR frames. Specifically, HDR-LDM incorporates a tonemapping strategy to compress HDR frames into the latent space and a novel exposure embedding to aggregate the exposure information into the diffusion process. We then propose a Temporal-Consistent Alignment Module (TCAM) to learn the temporal information as a complement for HDR-LDM, which conducts coarse-to-fine feature alignment at different scales among video frames. Finally, we design a Zero-Init Cross-Attention (ZiCA) mechanism to effectively integrate the learned distribution prior and temporal information for generating HDR frames. Extensive experiments validate that HDR-V-Diff achieves state-of-the-art results on several representative datasets.
Diffusion-based Light Field Synthesis
Feb 01, 2024
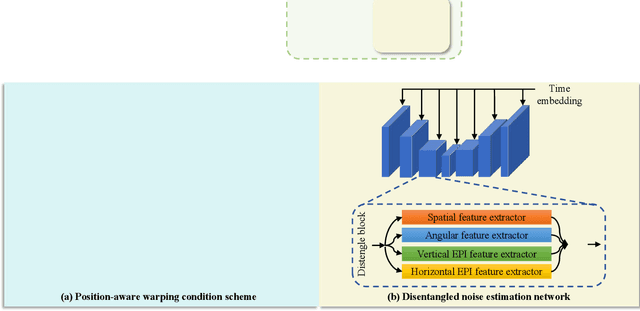


Light fields (LFs), conducive to comprehensive scene radiance recorded across angular dimensions, find wide applications in 3D reconstruction, virtual reality, and computational photography.However, the LF acquisition is inevitably time-consuming and resource-intensive due to the mainstream acquisition strategy involving manual capture or laborious software synthesis.Given such a challenge, we introduce LFdiff, a straightforward yet effective diffusion-based generative framework tailored for LF synthesis, which adopts only a single RGB image as input.LFdiff leverages disparity estimated by a monocular depth estimation network and incorporates two distinctive components: a novel condition scheme and a noise estimation network tailored for LF data.Specifically, we design a position-aware warping condition scheme, enhancing inter-view geometry learning via a robust conditional signal.We then propose DistgUnet, a disentanglement-based noise estimation network, to harness comprehensive LF representations.Extensive experiments demonstrate that LFdiff excels in synthesizing visually pleasing and disparity-controllable light fields with enhanced generalization capability.Additionally, comprehensive results affirm the broad applicability of the generated LF data, spanning applications like LF super-resolution and refocusing.
Toward Real-World Light Field Super-Resolution
May 30, 2023Deep learning has opened up new possibilities for light field super-resolution (SR), but existing methods trained on synthetic datasets with simple degradations (e.g., bicubic downsampling) suffer from poor performance when applied to complex real-world scenarios. To address this problem, we introduce LytroZoom, the first real-world light field SR dataset capturing paired low- and high-resolution light fields of diverse indoor and outdoor scenes using a Lytro ILLUM camera. Additionally, we propose the Omni-Frequency Projection Network (OFPNet), which decomposes the omni-frequency components and iteratively enhances them through frequency projection operations to address spatially variant degradation processes present in all frequency components. Experiments demonstrate that models trained on LytroZoom outperform those trained on synthetic datasets and are generalizable to diverse content and devices. Quantitative and qualitative evaluations verify the superiority of OFPNet. We believe this work will inspire future research in real-world light field SR.