 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Promoted HDR Video Reconstruction
Jun 12, 2024



High dynamic range (HDR) video reconstruction aims to generate HDR videos from low dynamic range (LDR) frames captured with alternating exposures. Most existing works solely rely on the regression-based paradigm, leading to adverse effects such as ghosting artifacts and missing details in saturated regions. In this paper, we propose a diffusion-promoted method for HDR video reconstruction, termed HDR-V-Diff, which incorporates a diffusion model to capture the HDR distribution. As such, HDR-V-Diff can reconstruct HDR videos with realistic details while alleviating ghosting artifacts. However, the direct introduction of video diffusion models would impose massive computational burden. Instead, to alleviate this burden, we first propose an HDR Latent Diffusion Model (HDR-LDM) to learn the distribution prior of single HDR frames. Specifically, HDR-LDM incorporates a tonemapping strategy to compress HDR frames into the latent space and a novel exposure embedding to aggregate the exposure information into the diffusion process. We then propose a Temporal-Consistent Alignment Module (TCAM) to learn the temporal information as a complement for HDR-LDM, which conducts coarse-to-fine feature alignment at different scales among video frames. Finally, we design a Zero-Init Cross-Attention (ZiCA) mechanism to effectively integrate the learned distribution prior and temporal information for generating HDR frames. Extensive experiments validate that HDR-V-Diff achieves state-of-the-art results on several representative datasets.
Neural Degradation Representation Learning for All-In-One Image Restoration
Oct 19, 2023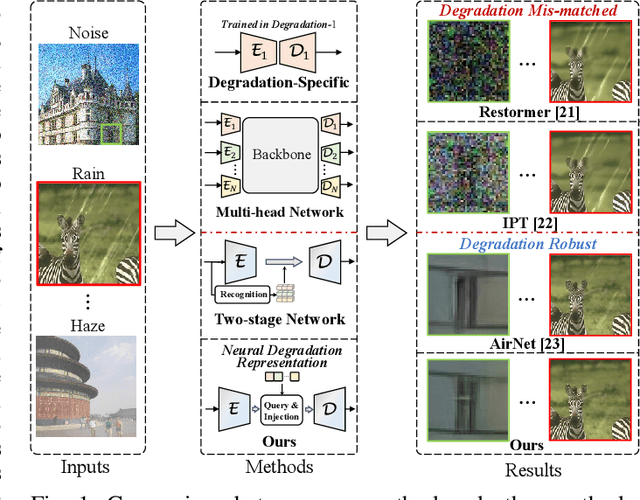
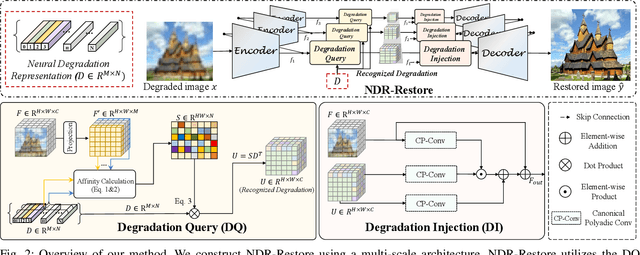
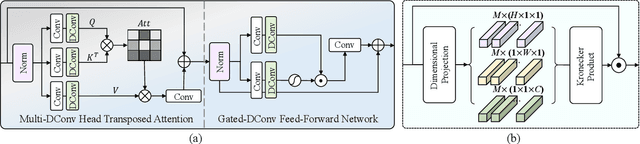
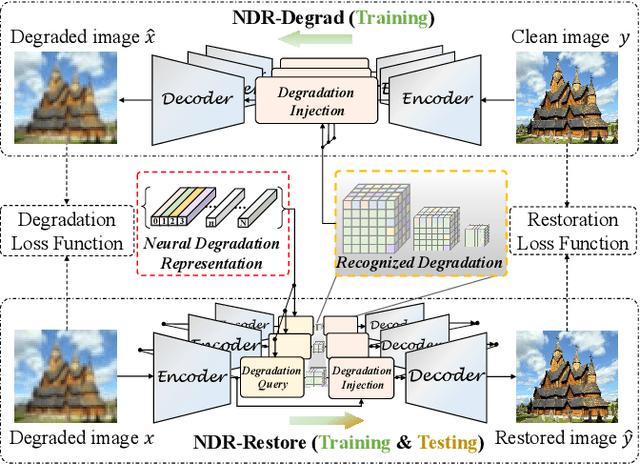
Existing methods have demonstrated effective performance on a single degradation type. In practical applications, however, the degradation is often unknown, and the mismatch between the model and the degradation will result in a severe performance drop. In this paper, we propose an all-in-one image restoration network that tackles multiple degradations. Due to the heterogeneous nature of different types of degradations, it is difficult to process multiple degradations in a single network. To this end, we propose to learn a neural degradation representation (NDR) that captures the underlying characteristics of various degradations. The learned NDR decomposes different types of degradations adaptively, similar to a neural dictionary that represents basic degradation components. Subsequently, we develop a degradation query module and a degradation injection module to effectively recognize and utilize the specific degradation based on NDR, enabling the all-in-one restoration ability for multiple degradations. Moreover, we propose a bidirectional optimization strategy to effectively drive NDR to learn the degradation representation by optimizing the degradation and restoration processes alternately. Comprehensive experiments on representative types of degradations (including noise, haze, rain, and downsampling) demonstrate the effectiveness and generalization capability of our method.
Mutual-Guided Dynamic Network for Image Fusion
Sep 01, 2023



Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.