 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
Decentralized Federated Learning by Partial Message Exchange
Mar 02, 2026Decentralized federated learning (DFL) has emerged as a transformative server-free paradigm that enables collaborative learning over large-scale heterogeneous networks. However, it continues to face fundamental challenges, including data heterogeneity, restrictive assumptions for theoretical analysis, and degraded convergence when standard communication- or privacyenhancing techniques are applied. To overcome these drawbacks, this paper develops a novel algorithm, PaME (DFL by Partial Message Exchange). The central principle is to allow only randomly selected sparse coordinates to be exchanged between two neighbor nodes. Consequently, PaME achieves substantial reductions in communication costs while still preserving a high level of privacy, without sacrificing accuracy. Moreover, grounded in rigorous analysis, the algorithm is shown to converge at a linear rate under the gradient to be locally Lipschitz continuous and the communication matrix to be doubly stochastic. These two mild assumptions not only dispense with many restrictive conditions commonly imposed by existing DFL methods but also enables PaME to effectively address data heterogeneity. Furthermore, comprehensive numerical experiments demonstrate its superior performance compared with several representative decentralized learning algorithms.
Neural Collapse based Deep Supervised Federated Learning for Signal Detection in OFDM Systems
Jun 24, 2025Future wireless networks are expected to be AI-empowered, making their performance highly dependent on the quality of training datasets. However, physical-layer entities often observe only partial wireless environments characterized by different power delay profiles. Federated learning is capable of addressing this limited observability, but often struggles with data heterogeneity. To tackle this challenge, we propose a neural collapse (NC) inspired deep supervised federated learning (NCDSFL) algorithm.
Fast Adaptation for Deep Learning-based Wireless Communications
Sep 06, 2024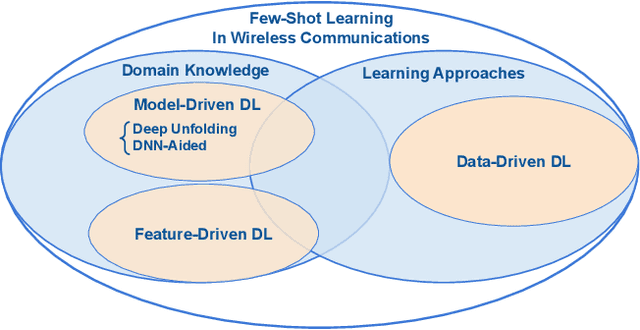



The integration with artificial intelligence (AI) is recognized as one of the six usage scenarios in next-generation wireless communications. However, several critical challenges hinder the widespread application of deep learning (DL) techniques in wireless communications. In particular, existing DL-based wireless communications struggle to adapt to the rapidly changing wireless environments. In this paper, we discuss fast adaptation for DL-based wireless communications by using few-shot learning (FSL) techniques. We first identify the differences between fast adaptation in wireless communications and traditional AI tasks by highlighting two distinct FSL design requirements for wireless communications. To establish a wide perspective, we present a comprehensive review of the existing FSL techniques in wireless communications that satisfy these two design requirements. In particular, we emphasize the importance of applying domain knowledge in achieving fast adaptation. We specifically focus on multiuser multiple-input multiple-output (MU-MIMO) precoding as an examples to demonstrate the advantages of the FSL to achieve fast adaptation in wireless communications. Finally, we highlight several open research issues for achieving broadscope future deployment of fast adaptive DL in wireless communication applications.
BADM: Batch ADMM for Deep Learning
Jun 30, 2024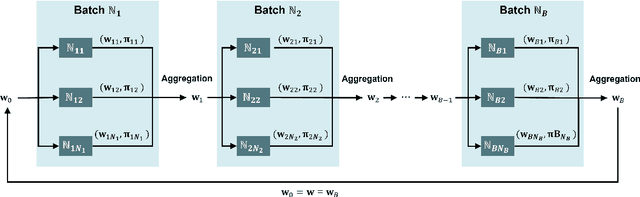
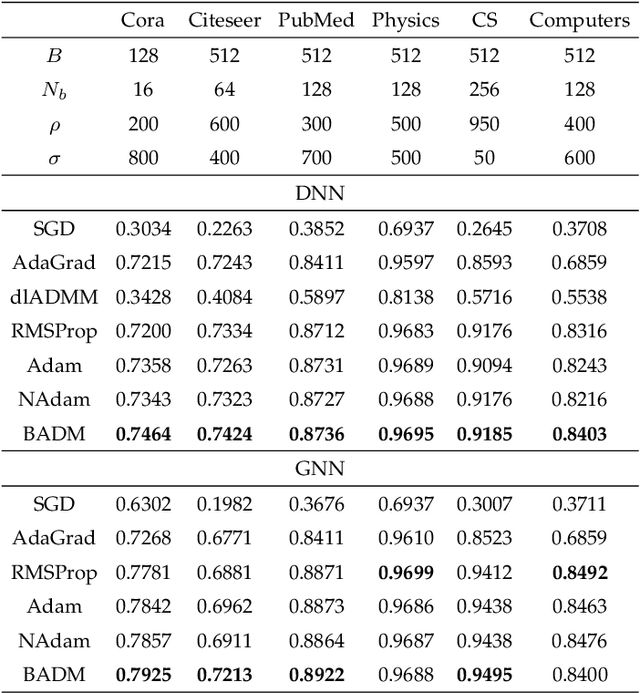
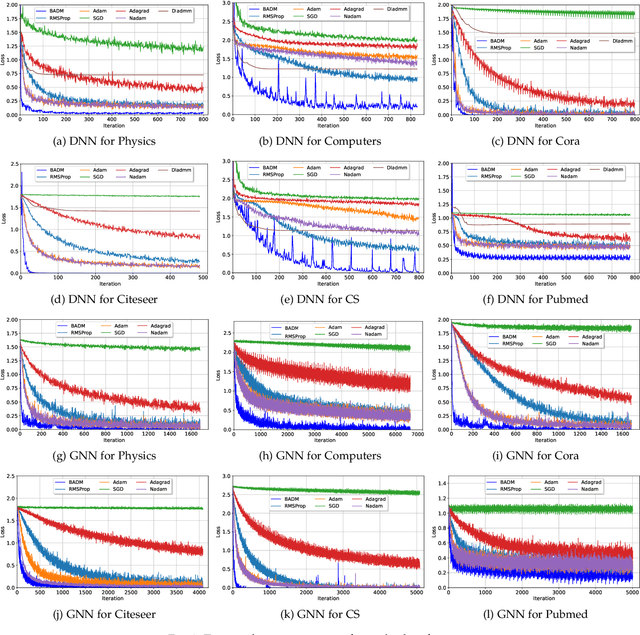
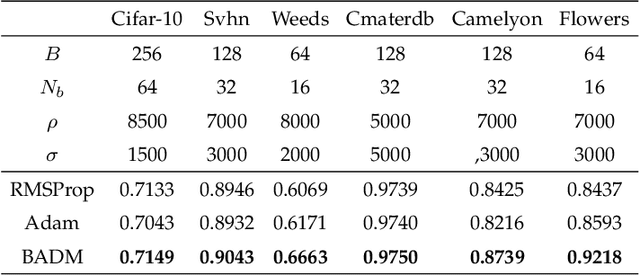
Stochastic gradient descent-based algorithms are widely used for training deep neural networks but often suffer from slow convergence. To address the challenge, we leverage the framework of the alternating direction method of multipliers (ADMM) to develop a novel data-driven algorithm, called batch ADMM (BADM). The fundamental idea of the proposed algorithm is to split the training data into batches, which is further divided into sub-batches where primal and dual variables are updated to generate global parameters through aggregation. We evaluate the performance of BADM across various deep learning tasks, including graph modelling, computer vision, image generation, and natural language processing. Extensive numerical experiments demonstrate that BADM achieves faster convergence and superior testing accuracy compared to other state-of-the-art optimizers.
Rescale-Invariant Federated Reinforcement Learning for Resource Allocation in V2X Networks
May 03, 2024
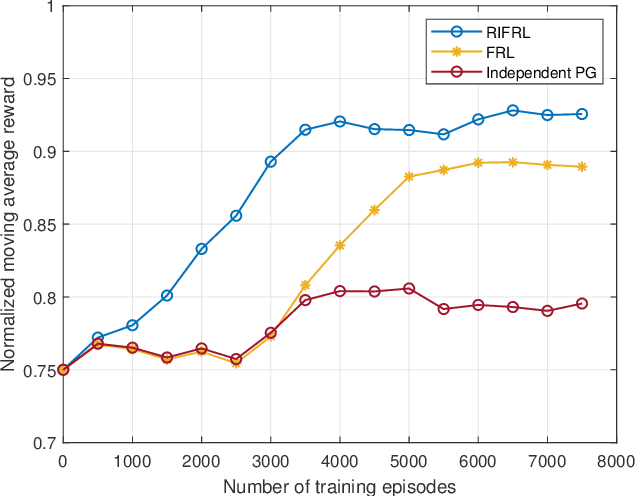
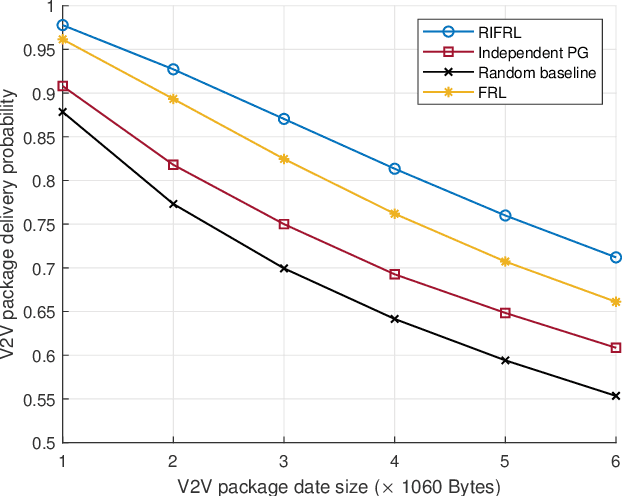
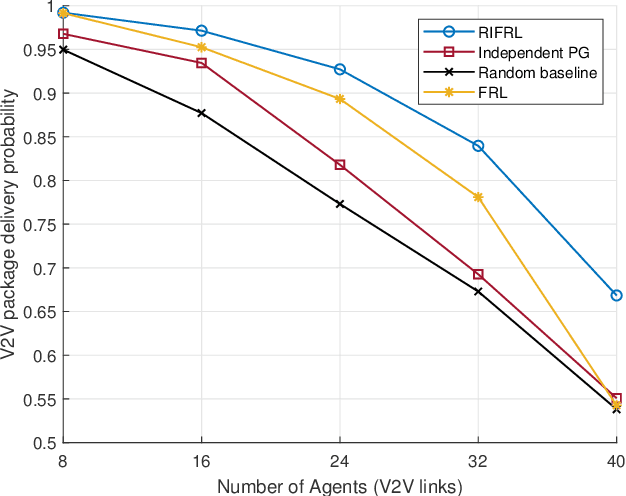
Federated Reinforcement Learning (FRL) offers a promising solution to various practical challenges in resource allocation for vehicle-to-everything (V2X) networks. However, the data discrepancy among individual agents can significantly degrade the performance of FRL-based algorithms. To address this limitation, we exploit the node-wise invariance property of ReLU-activated neural networks, with the aim of reducing data discrepancy to improve learning performance. Based on this property, we introduce a backward rescale-invariant operation to develop a rescale-invariant FRL algorithm. Simulation results demonstrate that the proposed algorithm notably enhances both convergence speed and convergent performance.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Federated Reinforcement Learning for Resource Allocation in V2X Networks
Oct 15, 2023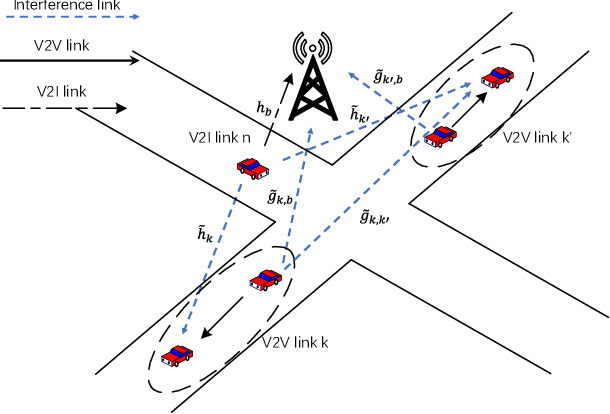
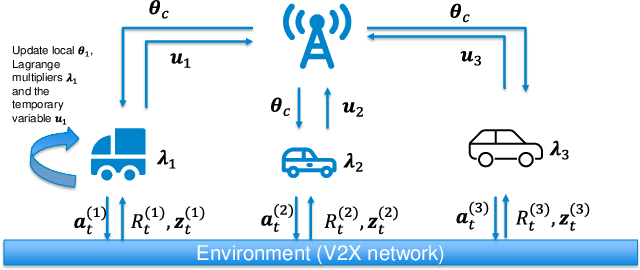

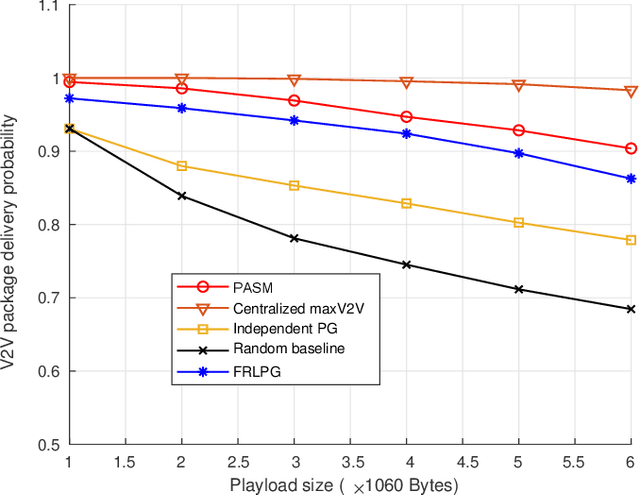
Resource allocation significantly impacts the performance of vehicle-to-everything (V2X) networks. Most existing algorithms for resource allocation are based on optimization or machine learning (e.g., reinforcement learning). In this paper, we explore resource allocation in a V2X network under the framework of federated reinforcement learning (FRL). On one hand, the usage of RL overcomes many challenges from the model-based optimization schemes. On the other hand, federated learning (FL) enables agents to deal with a number of practical issues, such as privacy, communication overhead, and exploration efficiency. The framework of FRL is then implemented by the inexact alternative direction method of multipliers (ADMM), where subproblems are solved approximately using policy gradients and accelerated by an adaptive step size calculated from their second moments. The developed algorithm, PASM, is proven to be convergent under mild conditions and has a nice numerical performance compared with some baseline methods for solving the resource allocation problem in a V2X network.
Self-Supervised Neuron Segmentation with Multi-Agent Reinforcement Learning
Oct 06, 2023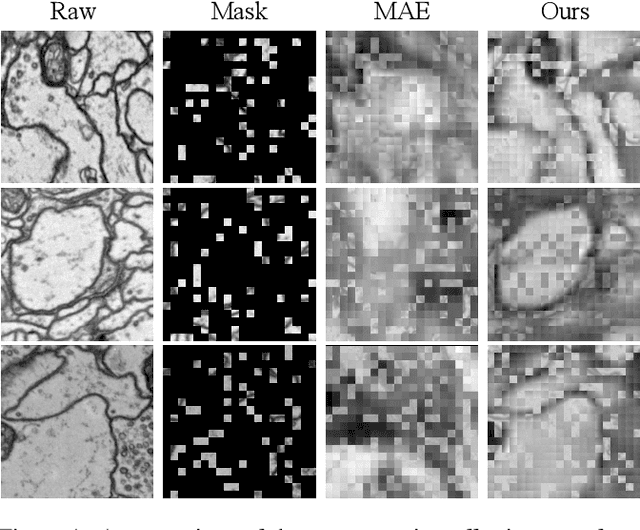
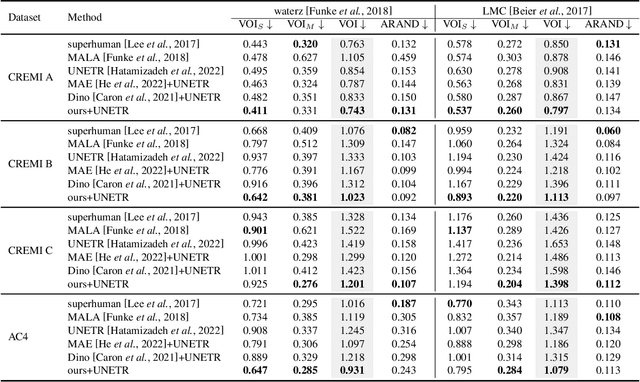
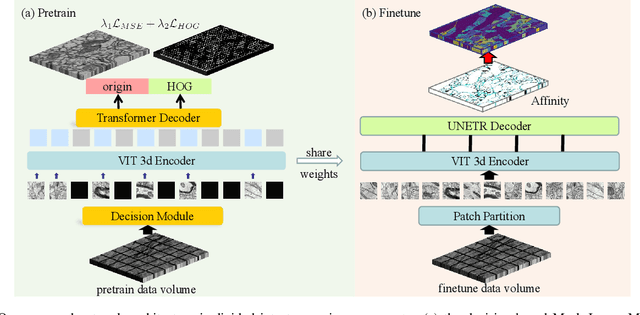
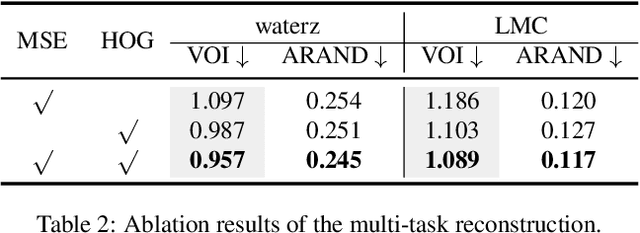
The performance of existing supervised neuron segmentation methods is highly dependent on the number of accurate annotations, especially when applied to large scale electron microscopy (EM) data. By extracting semantic information from unlabeled data, self-supervised methods can improve the performance of downstream tasks, among which the mask image model (MIM) has been widely used due to its simplicity and effectiveness in recovering original information from masked images. However, due to the high degree of structural locality in EM images, as well as the existence of considerable noise, many voxels contain little discriminative information, making MIM pretraining inefficient on the neuron segmentation task. To overcome this challenge, we propose a decision-based MIM that utilizes reinforcement learning (RL) to automatically search for optimal image masking ratio and masking strategy. Due to the vast exploration space, using single-agent RL for voxel prediction is impractical. Therefore, we treat each input patch as an agent with a shared behavior policy, allowing for multi-agent collaboration. Furthermore, this multi-agent model can capture dependencies between voxels, which is beneficial for the downstream segmentation task. Experiments conducted on representative EM datasets demonstrate that our approach has a significant advantage over alternative self-supervised methods on the task of neuron segmentation. Code is available at \url{https://github.com/ydchen0806/dbMiM}.
Communication-Efficient Decentralized Federated Learning via One-Bit Compressive Sensing
Aug 31, 2023


Decentralized federated learning (DFL) has gained popularity due to its practicality across various applications. Compared to the centralized version, training a shared model among a large number of nodes in DFL is more challenging, as there is no central server to coordinate the training process. Especially when distributed nodes suffer from limitations in communication or computational resources, DFL will experience extremely inefficient and unstable training. Motivated by these challenges, in this paper, we develop a novel algorithm based on the framework of the inexact alternating direction method (iADM). On one hand, our goal is to train a shared model with a sparsity constraint. This constraint enables us to leverage one-bit compressive sensing (1BCS), allowing transmission of one-bit information among neighbour nodes. On the other hand, communication between neighbour nodes occurs only at certain steps, reducing the number of communication rounds. Therefore, the algorithm exhibits notable communication efficiency. Additionally, as each node selects only a subset of neighbours to participate in the training, the algorithm is robust against stragglers. Additionally, complex items are computed only once for several consecutive steps and subproblems are solved inexactly using closed-form solutions, resulting in high computational efficiency. Finally, numerical experiments showcase the algorithm's effectiveness in both communication and computation.