 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adaptation for Deep Learning-based Wireless Communications
Sep 06, 2024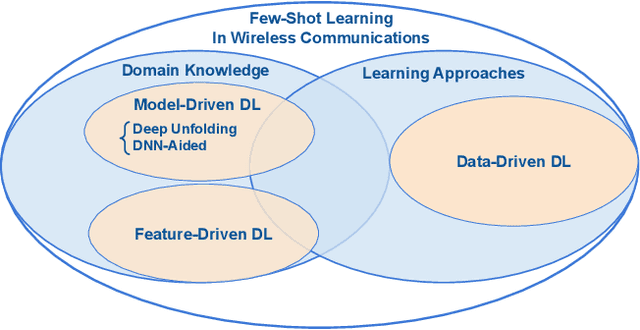



The integration with artificial intelligence (AI) is recognized as one of the six usage scenarios in next-generation wireless communications. However, several critical challenges hinder the widespread application of deep learning (DL) techniques in wireless communications. In particular, existing DL-based wireless communications struggle to adapt to the rapidly changing wireless environments. In this paper, we discuss fast adaptation for DL-based wireless communications by using few-shot learning (FSL) techniques. We first identify the differences between fast adaptation in wireless communications and traditional AI tasks by highlighting two distinct FSL design requirements for wireless communications. To establish a wide perspective, we present a comprehensive review of the existing FSL techniques in wireless communications that satisfy these two design requirements. In particular, we emphasize the importance of applying domain knowledge in achieving fast adaptation. We specifically focus on multiuser multiple-input multiple-output (MU-MIMO) precoding as an examples to demonstrate the advantages of the FSL to achieve fast adaptation in wireless communications. Finally, we highlight several open research issues for achieving broadscope future deployment of fast adaptive DL in wireless communication applications.
BADM: Batch ADMM for Deep Learning
Jun 30, 2024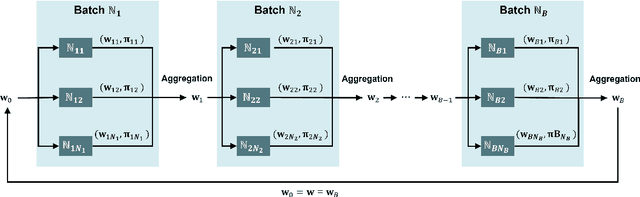
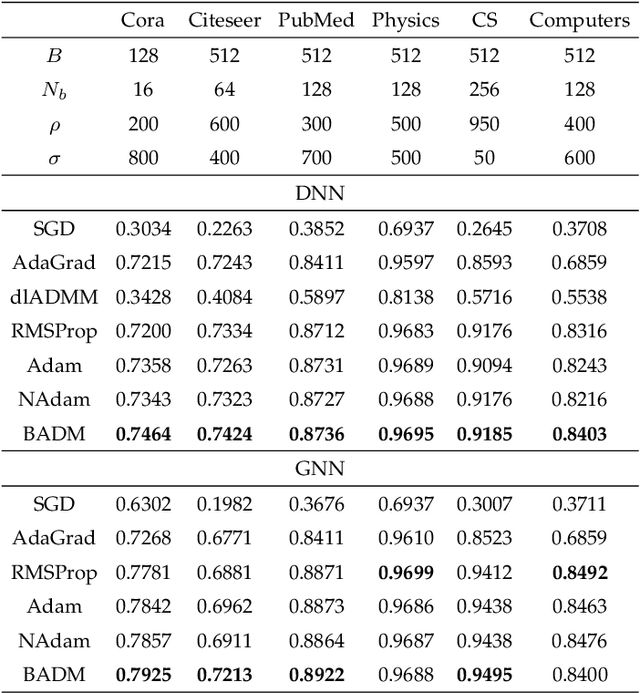
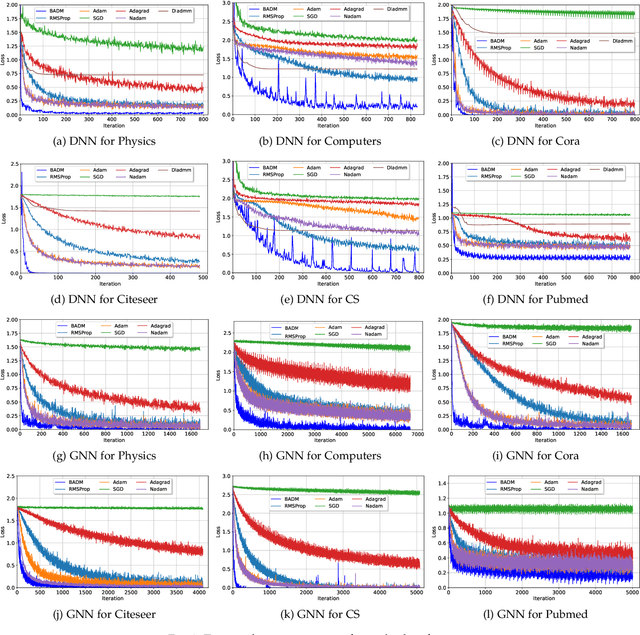
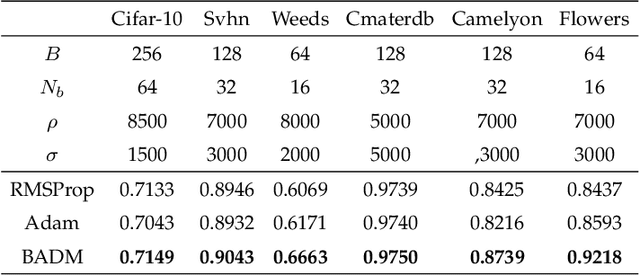
Stochastic gradient descent-based algorithms are widely used for training deep neural networks but often suffer from slow convergence. To address the challenge, we leverage the framework of the alternating direction method of multipliers (ADMM) to develop a novel data-driven algorithm, called batch ADMM (BADM). The fundamental idea of the proposed algorithm is to split the training data into batches, which is further divided into sub-batches where primal and dual variables are updated to generate global parameters through aggregation. We evaluate the performance of BADM across various deep learning tasks, including graph modelling, computer vision, image generation, and natural language processing. Extensive numerical experiments demonstrate that BADM achieves faster convergence and superior testing accuracy compared to other state-of-the-art optimizers.
Learn to Adapt to New Environment from Past Experience and Few Pilot
Sep 02, 2022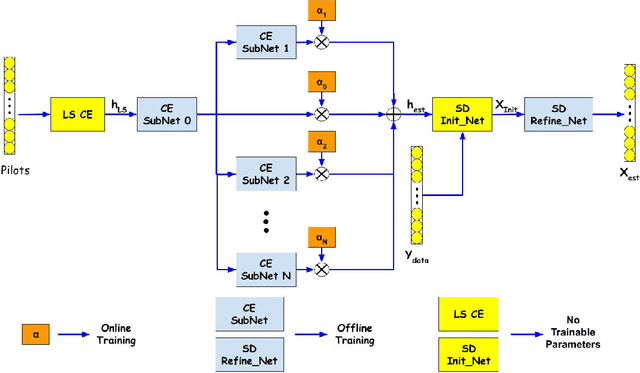
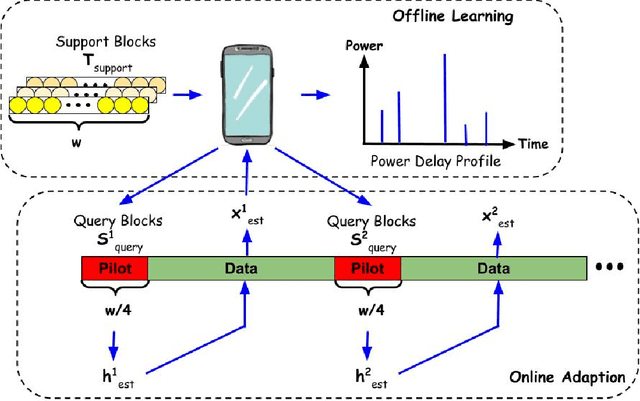
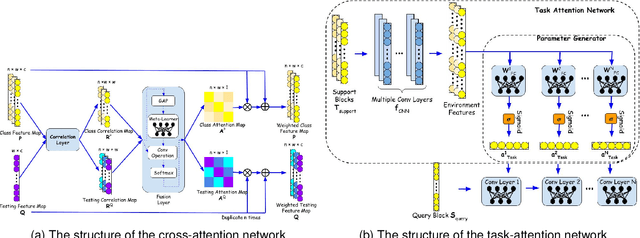
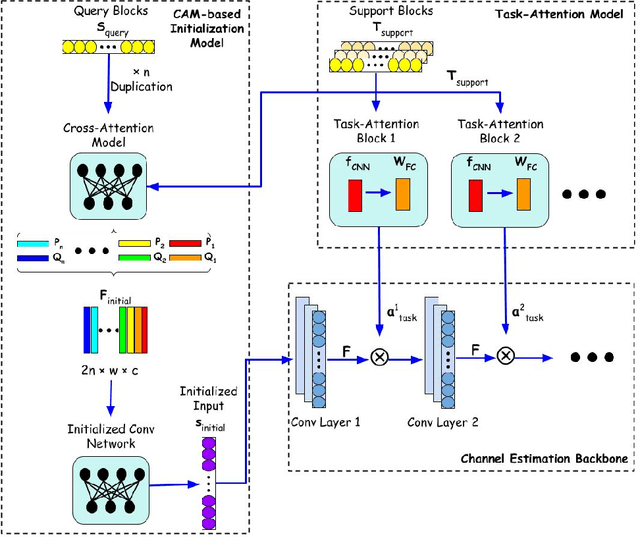
In recent years, deep learning has been widely applied in communications and achieved remarkable performance improvement. Most of the existing works are based on data-driven deep learning, which requires a significant amount of training data for the communication model to adapt to new environments and results in huge computing resources for collecting data and retraining the model. In this paper, we will significantly reduce the required amount of training data for new environments by leveraging the learning experience from the known environments. Therefore, we introduce few-shot learning to enable the communication model to generalize to new environments, which is realized by an attention-based method. With the attention network embedded into the deep learning-based communication model, environments with different power delay profiles can be learnt together in the training process, which is called the learning experience. By exploiting the learning experience, the communication model only requires few pilot blocks to perform well in the new environment. Through an example of deep-learning-based channel estimation, we demonstrate that this novel design method achieves better performance than the existing data-driven approach designed for few-shot learning.
Accretionary Learning with Deep Neural Networks
Nov 21, 2021
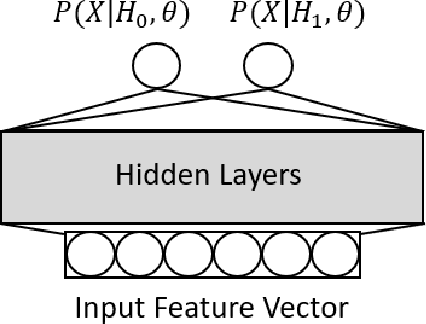
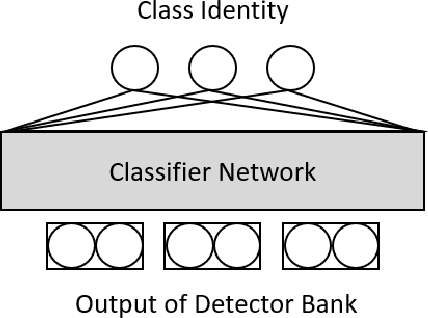
One of the fundamental limitations of Deep Neural Networks (DNN) is its inability to acquire and accumulate new cognitive capabilities. When some new data appears, such as new object classes that are not in the prescribed set of objects being recognized, a conventional DNN would not be able to recognize them due to the fundamental formulation that it takes. The current solution is typically to re-design and re-learn the entire network, perhaps with a new configuration, from a newly expanded dataset to accommodate new knowledge. This process is quite different from that of a human learner. In this paper, we propose a new learning method named Accretionary Learning (AL) to emulate human learning, in that the set of objects to be recognized may not be pre-specified. The corresponding learning structure is modularized, which can dynamically expand to register and use new knowledge. During accretionary learning, the learning process does not require the system to be totally re-designed and re-trained as the set of objects grows in size. The proposed DNN structure does not forget previous knowledge when learning to recognize new data classes. We show that the new structure and the design methodology lead to a system that can grow to cope with increased cognitive complexity while providing stable and superior overall performance.