 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
Human or Machine? A Preliminary Turing Test for Speech-to-Speech Interaction
Mar 02, 2026The pursuit of human-like conversational agents has long been guided by the Turing test. For modern speech-to-speech (S2S) systems, a critical yet unanswered question is whether they can converse like humans. To tackle this, we conduct the first Turing test for S2S systems, collecting 2,968 human judgments on dialogues between 9 state-of-the-art S2S systems and 28 human participants. Our results deliver a clear finding: no existing evaluated S2S system passes the test, revealing a significant gap in human-likeness. To diagnose this failure, we develop a fine-grained taxonomy of 18 human-likeness dimensions and crowd-annotate our collected dialogues accordingly. Our analysis shows that the bottleneck is not semantic understanding but stems from paralinguistic features, emotional expressivity, and conversational persona. Furthermore, we find that off-the-shelf AI models perform unreliably as Turing test judges. In response, we propose an interpretable model that leverages the fine-grained human-likeness ratings and delivers accurate and transparent human-vs-machine discrimination, offering a powerful tool for automatic human-likeness evaluation. Our work establishes the first human-likeness evaluation for S2S systems and moves beyond binary outcomes to enable detailed diagnostic insights, paving the way for human-like improvements in conversational AI systems.
Deep Unfolding-Based Channel Estimation for Wideband TeraHertz Near-Field Massive MIMO Systems
Aug 25, 2023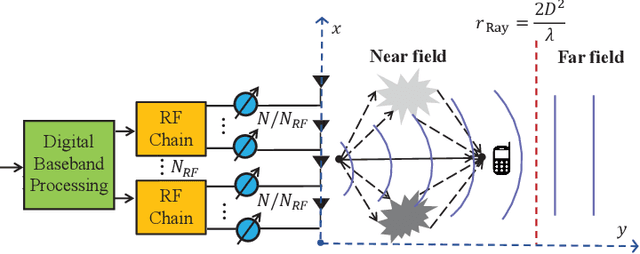
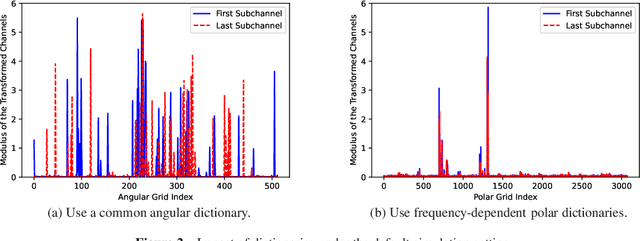
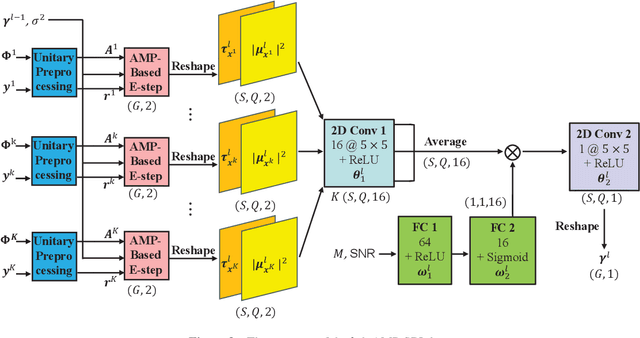
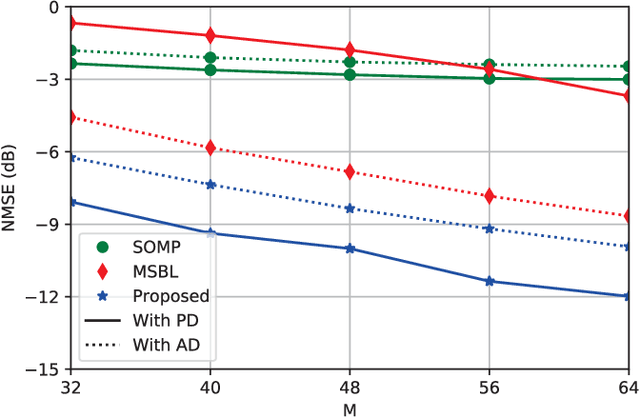
The combination of Terahertz (THz) and massive multiple-input multiple-output (MIMO) is promising to meet the increasing data rate demand of future wireless communication systems thanks to the huge bandwidth and spatial degrees of freedom. However, unique channel features such as the near-field beam split effect make channel estimation particularly challenging in THz massive MIMO systems. On one hand, adopting the conventional angular domain transformation dictionary designed for low-frequency far-field channels will result in degraded channel sparsity and destroyed sparsity structure in the transformed domain. On the other hand, most existing compressive sensing-based channel estimation algorithms cannot achieve high performance and low complexity simultaneously. To alleviate these issues, in this paper, we first adopt frequency-dependent near-field dictionaries to maintain good channel sparsity and sparsity structure in the transformed domain under the near-field beam split effect. Then, a deep unfolding-based wideband THz massive MIMO channel estimation algorithm is proposed. In each iteration of the unitary approximate message passing-sparse Bayesian learning algorithm, the optimal update rule is learned by a deep neural network (DNN), whose structure is customized to effectively exploit the inherent channel patterns. Furthermore, a mixed training method based on novel designs of the DNN structure and the loss function is developed to effectively train data from different system configurations. Simulation results validate the superiority of the proposed algorithm in terms of performance, complexity, and robustness.
AMP-SBL Unfolding for Wideband MmWave Massive MIMO Channel Estimation
Feb 01, 2023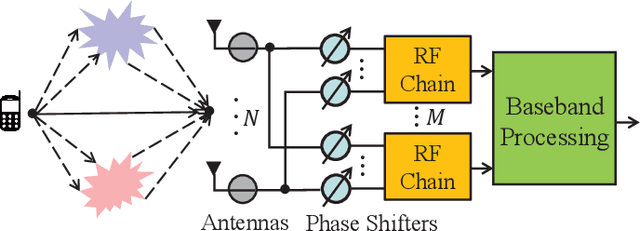
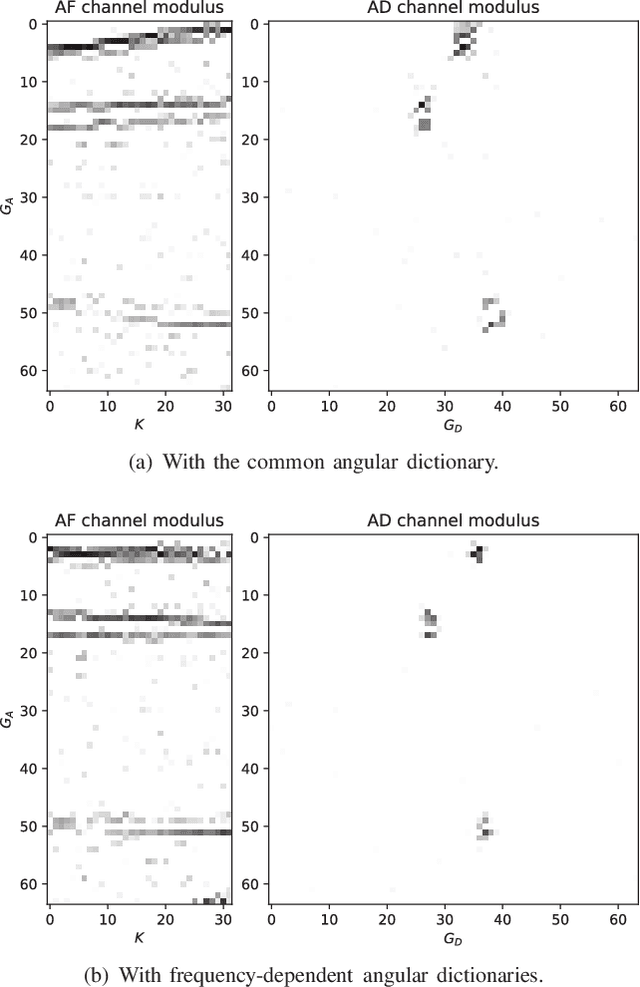
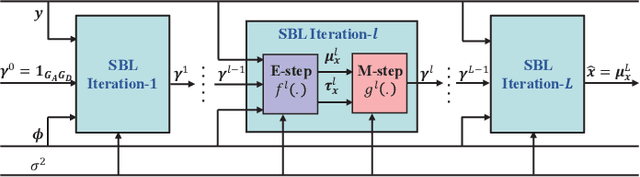
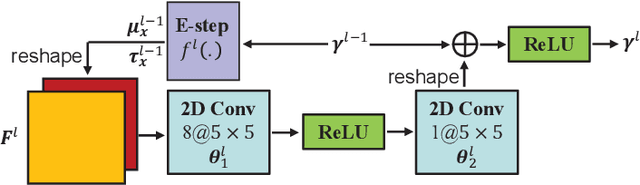
In wideband millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems, channel estimation is challenging due to the hybrid analog-digital architecture, which compresses the received pilot signal and makes channel estimation a compressive sensing (CS) problem. However, existing high-performance CS algorithms usually suffer from high complexity. On the other hand, the beam squint effect caused by huge bandwidth and massive antennas will deteriorate estimation performance. In this paper, frequency-dependent angular dictionaries are first adopted to compensate for beam squint. Then, the expectation-maximization (EM)-based sparse Bayesian learning (SBL) algorithm is enhanced in two aspects, where the E-step in each iteration is implemented by approximate message passing (AMP) to reduce complexity while the M-step is realized by a deep neural network (DNN) to improve performance. In simulation, the proposed AMP-SBL unfolding-based channel estimator achieves satisfactory performance with low complexity.
Learn to Adapt to New Environment from Past Experience and Few Pilot
Sep 02, 2022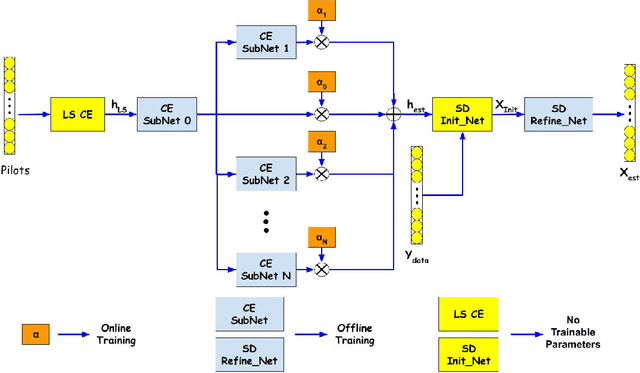
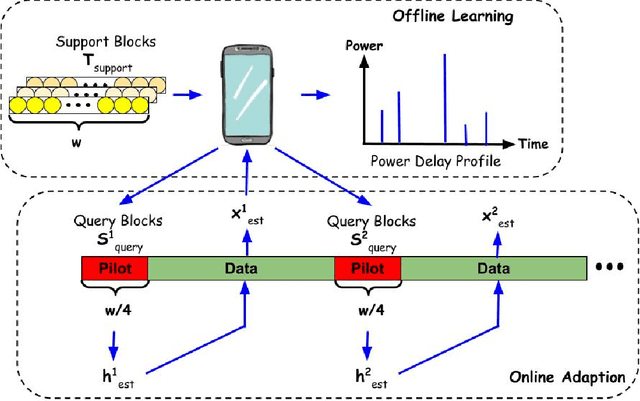
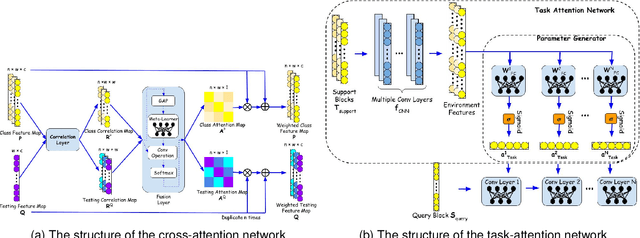
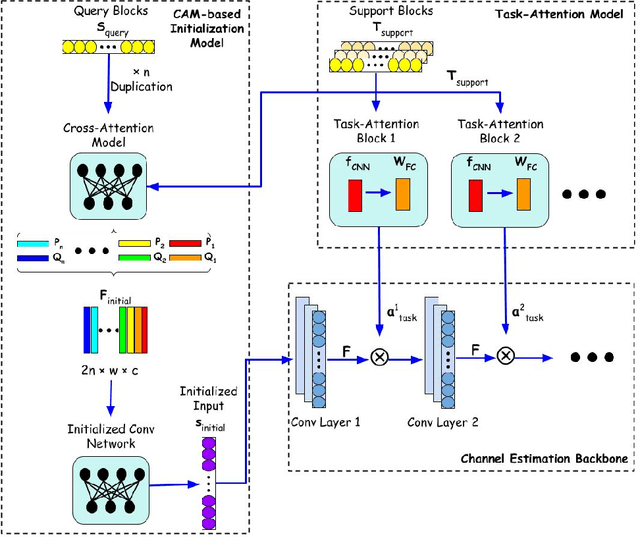
In recent years, deep learning has been widely applied in communications and achieved remarkable performance improvement. Most of the existing works are based on data-driven deep learning, which requires a significant amount of training data for the communication model to adapt to new environments and results in huge computing resources for collecting data and retraining the model. In this paper, we will significantly reduce the required amount of training data for new environments by leveraging the learning experience from the known environments. Therefore, we introduce few-shot learning to enable the communication model to generalize to new environments, which is realized by an attention-based method. With the attention network embedded into the deep learning-based communication model, environments with different power delay profiles can be learnt together in the training process, which is called the learning experience. By exploiting the learning experience, the communication model only requires few pilot blocks to perform well in the new environment. Through an example of deep-learning-based channel estimation, we demonstrate that this novel design method achieves better performance than the existing data-driven approach designed for few-shot learning.
A Deep Learning-Based Framework for Low Complexity Multi-User MIMO Precoding Design
Jul 08, 2022
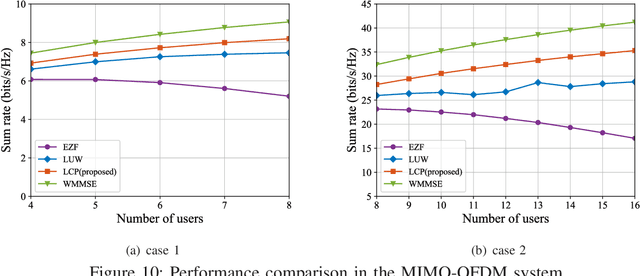
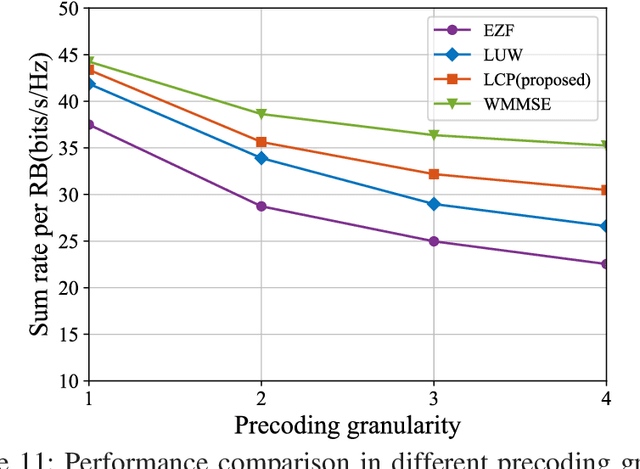
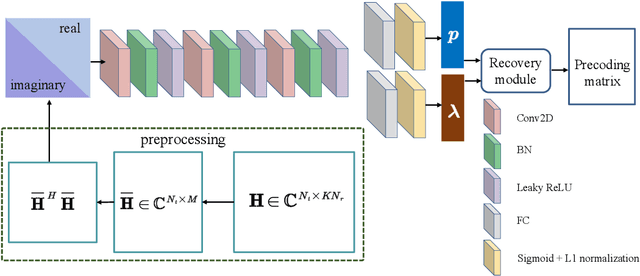
Using precoding to suppress multi-user interference is a well-known technique to improve spectra efficiency in multiuser multiple-input multiple-output (MU-MIMO) systems, and the pursuit of high performance and low complexity precoding method has been the focus in the last decade. The traditional algorithms including the zero-forcing (ZF) algorithm and the weighted minimum mean square error (WMMSE) algorithm failed to achieve a satisfactory trade-off between complexity and performance. In this paper, leveraging on the power of deep learning, we propose a low-complexity precoding design framework for MU-MIMO systems. The key idea is to transform the MIMO precoding problem into the multiple-input single-output precoding problem, where the optimal precoding structure can be obtained in closed-form. A customized deep neural network is designed to fit the mapping from the channels to the precoding matrix. In addition, the technique of input dimensionality reduction, network pruning, and recovery module compression are used to further improve the computational efficiency. Furthermore, the extension to the practical MIMO orthogonal frequency-division multiplexing (MIMO-OFDM) system is studied. Simulation results show that the proposed low-complexity precoding scheme achieves similar performance as the WMMSE algorithm with very low computational complexity.
Deep Learning-based Channel Estimation for Wideband Hybrid MmWave Massive MIMO
May 10, 2022
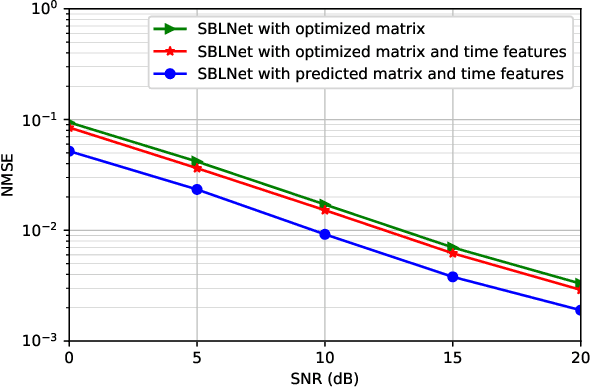
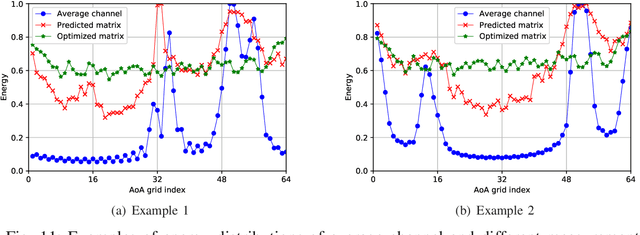
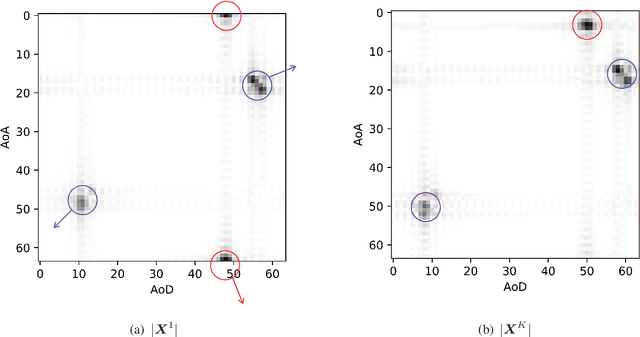
Hybrid analog-digital (HAD) architecture is widely adopted in practical millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems to reduce hardware cost and energy consumption. However, channel estimation in the context of HAD is challenging due to only limited radio frequency (RF) chains at transceivers. Although various compressive sensing (CS) algorithms have been developed to solve this problem by exploiting inherent channel sparsity and sparsity structures, practical effects, such as power leakage and beam squint, can still make the real channel features deviate from the assumed models and result in performance degradation. Also, the high complexity of CS algorithms caused by a large number of iterations hinders their applications in practice. To tackle these issues, we develop a deep learning (DL)-based channel estimation approach where the sparse Bayesian learning (SBL) algorithm is unfolded into a deep neural network (DNN). In each SBL layer, Gaussian variance parameters of the sparse angular domain channel are updated by a tailored DNN, which is able to effectively capture complicated channel sparsity structures in various domains. Besides, the measurement matrix is jointly optimized for performance improvement. Then, the proposed approach is extended to the multi-block case where channel correlation in time is further exploited to adaptively predict the measurement matrix and facilitate the update of Gaussian variance parameters. Based on simulation results, the proposed approaches significantly outperform existing approaches but with reduced complexity.
Online Deep Neural Network for Optimization in Wireless Communications
Feb 07, 2022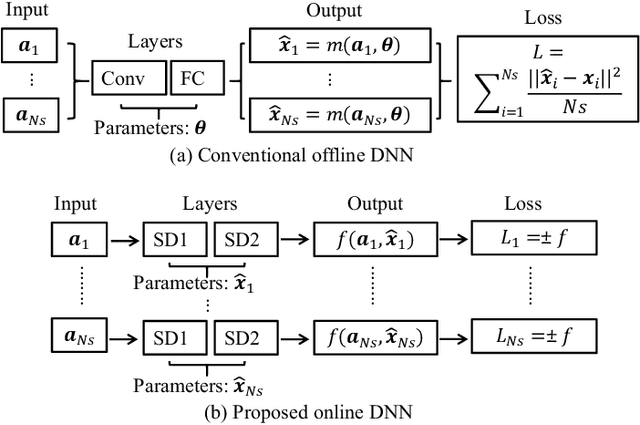
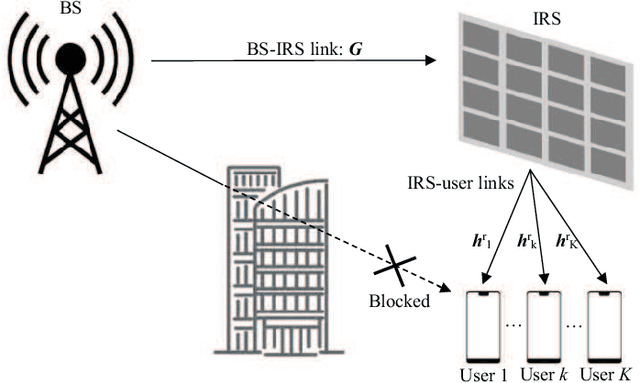
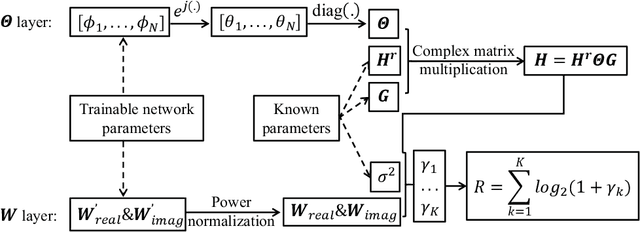
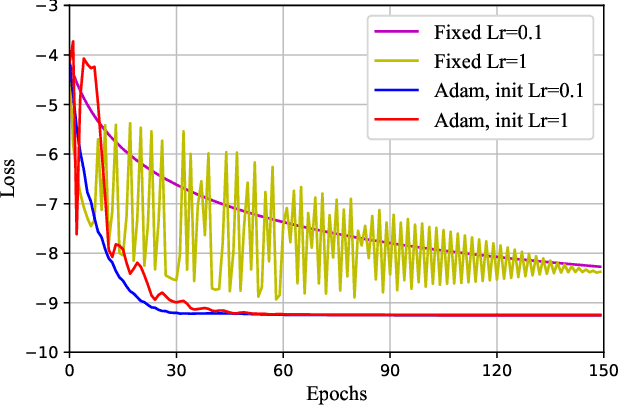
Recently, deep neural network (DNN) has been widely adopted in the design of intelligent communication systems thanks to its strong learning ability and low testing complexity. However, most current offline DNN-based methods still suffer from unsatisfactory performance, limited generalization ability, and poor interpretability. In this article, we propose an online DNN-based approach to solve general optimization problems in wireless communications, where a dedicated DNN is trained for each data sample. By treating the optimization variables and the objective function as network parameters and loss function, respectively, the optimization problem can be solved equivalently through network training. Thanks to the online optimization nature and meaningful network parameters, the proposed approach owns strong generalization ability and interpretability, while its superior performance is demonstrated through a practical example of joint beamforming in intelligent reflecting surface (IRS)-aided multi-user multiple-input multiple-output (MIMO) systems. Simulation results show that the proposed online DNN outperforms conventional offline DNN and state-of-the-art iterative optimization algorithm, but with low complexity.
Deep Learning based Channel Estimation for Massive MIMO with Hybrid Transceivers
Feb 07, 2022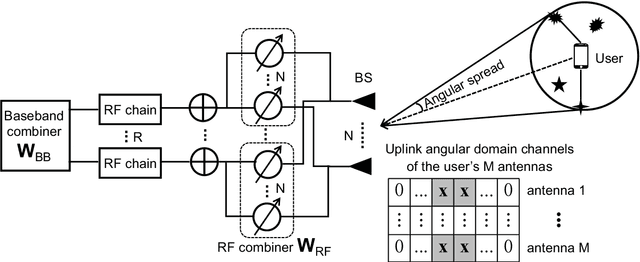
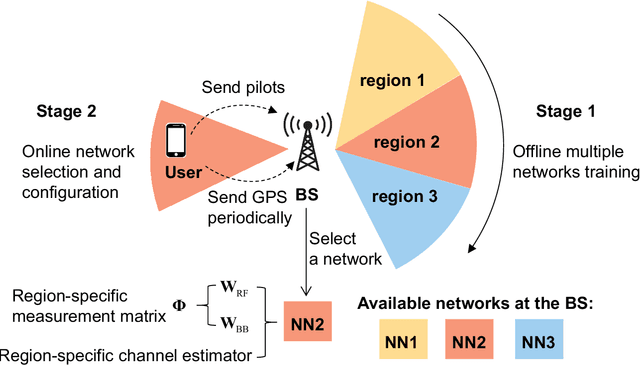
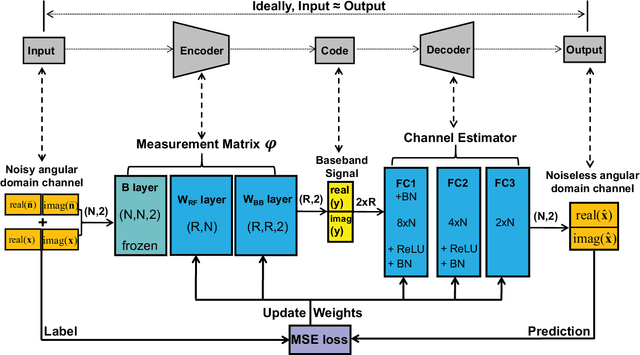
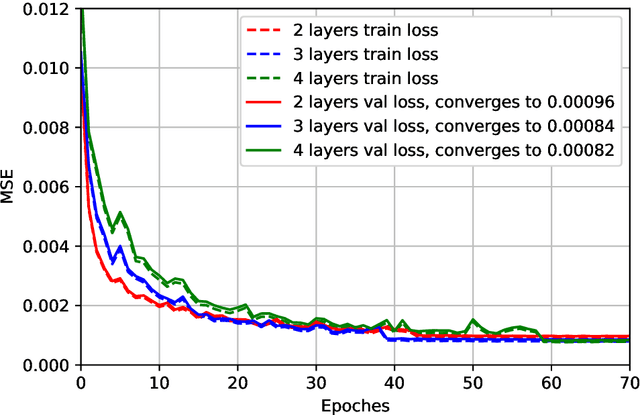
Accurate and efficient estimation of the high dimensional channels is one of the critical challenges for practical applications of massive multiple-input multiple-output (MIMO). In the context of hybrid analog-digital (HAD) transceivers, channel estimation becomes even more complicated due to information loss caused by limited radio-frequency chains. The conventional compressive sensing (CS) algorithms usually suffer from unsatisfactory performance and high computational complexity. In this paper, we propose a novel deep learning (DL) based framework for uplink channel estimation in HAD massive MIMO systems. To better exploit the sparsity structure of channels in the angular domain, a novel angular space segmentation method is proposed, where the entire angular space is segmented into many small regions and a dedicated neural network is trained offline for each region. During online testing, the most suitable network is selected based on the information from the global positioning system. Inside each neural network, the region-specific measurement matrix and channel estimator are jointly optimized, which not only improves the signal measurement efficiency, but also enhances the channel estimation capability. Simulation results show that the proposed approach significantly outperforms the state-of-the-art CS algorithms in terms of estimation performance and computational complexity.
An Attention-Aided Deep Learning Framework for Massive MIMO Channel Estimation
Aug 21, 2021

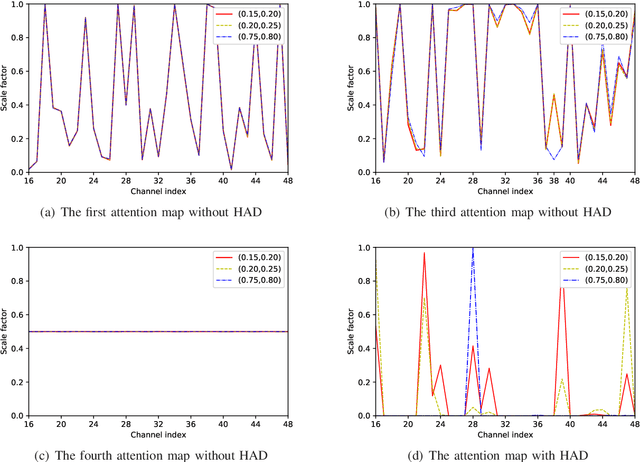
Channel estimation is one of the key issues in practical massive multiple-input multiple-output (MIMO) systems. Compared with conventional estimation algorithms, deep learning (DL) based ones have exhibited great potential in terms of performance and complexity. In this paper, an attention mechanism, exploiting the channel distribution characteristics, is proposed to improve the estimation accuracy of highly separable channels with narrow angular spread by realizing the "divide-and-conquer" policy. Specifically, we introduce a novel attention-aided DL channel estimation framework for conventional massive MIMO systems and devise an embedding method to effectively integrate the attention mechanism into the fully connected neural network for the hybrid analog-digital (HAD) architecture. Simulation results show that in both scenarios, the channel estimation performance is significantly improved with the aid of attention at the cost of small complexity overhead. Furthermore, strong robustness under different system and channel parameters can be achieved by the proposed approach, which further strengthens its practical value. We also investigate the distributions of learned attention maps to reveal the role of attention, which endows the proposed approach with a certain degree of interpretability.