 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Exhaustive Correlation for Spectral Super-Resolution: Where Unified Spatial-Spectral Attention Meets Mutual Linear Dependence
Dec 20, 2023Spectral super-resolution from the easily obtainable RGB image to hyperspectral image (HSI) has drawn increasing interest in the field of computational photography. The crucial aspect of spectral super-resolution lies in exploiting the correlation within HSIs. However, two types of bottlenecks in existing Transformers limit performance improvement and practical applications. First, existing Transformers often separately emphasize either spatial-wise or spectral-wise correlation, disrupting the 3D features of HSI and hindering the exploitation of unified spatial-spectral correlation. Second, the existing self-attention mechanism learns the correlation between pairs of tokens and captures the full-rank correlation matrix, leading to its inability to establish mutual linear dependence among multiple tokens. To address these issues, we propose a novel Exhaustive Correlation Transformer (ECT) for spectral super-resolution. First, we propose a Spectral-wise Discontinuous 3D (SD3D) splitting strategy, which models unified spatial-spectral correlation by simultaneously utilizing spatial-wise continuous splitting and spectral-wise discontinuous splitting. Second, we propose a Dynamic Low-Rank Mapping (DLRM) model, which captures mutual linear dependence among multiple tokens through a dynamically calculated low-rank dependence map. By integrating unified spatial-spectral attention with mutual linear dependence, our ECT can establish exhaustive correlation within HSI. The experimental results on both simulated and real data indicate that our method achieves state-of-the-art performance. Codes and pretrained models will be available later.
Computational Spectral Imaging with Unified Encoding Model: A Comparative Study and Beyond
Dec 20, 2023Computational spectral imaging is drawing increasing attention owing to the snapshot advantage, and amplitude, phase, and wavelength encoding systems are three types of representative implementations. Fairly comparing and understanding the performance of these systems is essential, but challenging due to the heterogeneity in encoding design. To overcome this limitation, we propose the unified encoding model (UEM) that covers all physical systems using the three encoding types. Specifically, the UEM comprises physical amplitude, physical phase, and physical wavelength encoding models that can be combined with a digital decoding model in a joint encoder-decoder optimization framework to compare the three systems under a unified experimental setup fairly. Furthermore, we extend the UEMs to ideal versions, namely, ideal amplitude, ideal phase, and ideal wavelength encoding models, which are free from physical constraints, to explore the full potential of the three types of computational spectral imaging systems. Finally, we conduct a holistic comparison of the three types of computational spectral imaging systems and provide valuable insights for designing and exploiting these systems in the future.
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Aug 05, 2022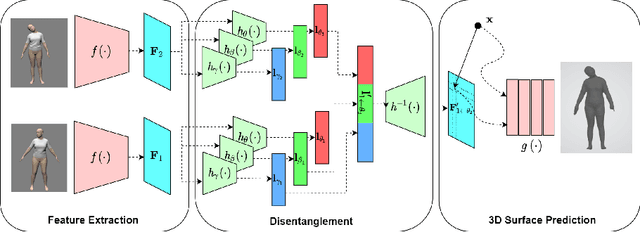

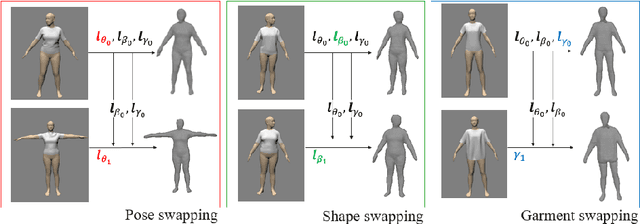
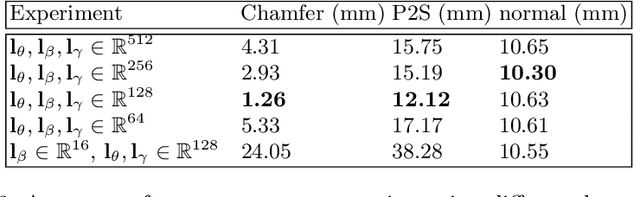
For visual manipulation tasks, we aim to represent image content with semantically meaningful features. However, learning implicit representations from images often lacks interpretability, especially when attributes are intertwined. We focus on the challenging task of extracting disentangled 3D attributes only from 2D image data. Specifically, we focus on human appearance and learn implicit pose, shape and garment representations of dressed humans from RGB images. Our method learns an embedding with disentangled latent representations of these three image properties and enables meaningful re-assembling of features and property control through a 2D-to-3D encoder-decoder structure. The 3D model is inferred solely from the feature map in the learned embedding space. To the best of our knowledge, our method is the first to achieve cross-domain disentanglement for this highly under-constrained problem. We qualitatively and quantitatively demonstrate our framework's ability to transfer pose, shape, and garments in 3D reconstruction on virtual data and show how an implicit shape loss can benefit the model's ability to recover fine-grained reconstruction details.
Occlusion-robust Visual Markerless Bone Tracking for Computer-Assisted Orthopaedic Surgery
Aug 24, 2021
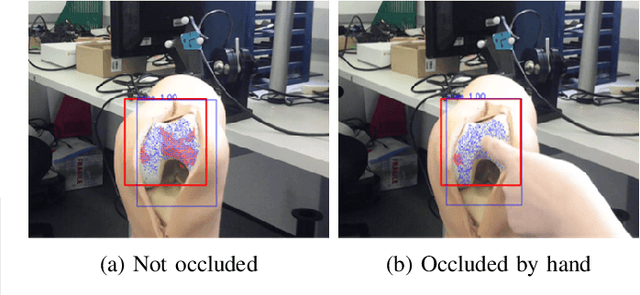
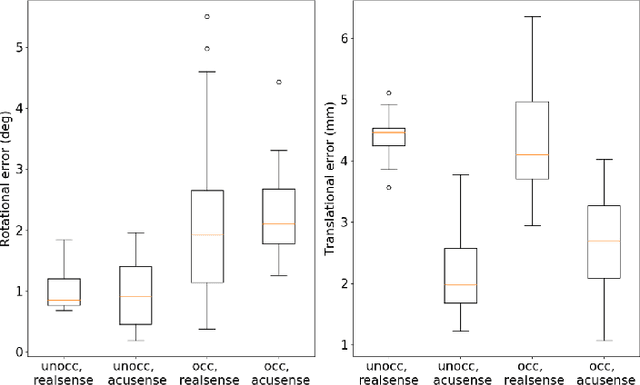
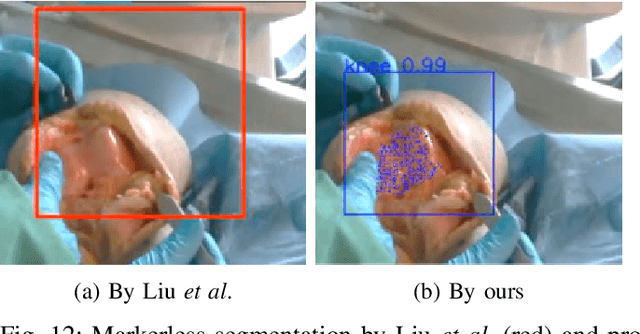
Conventional computer-assisted orthopaedic navigation systems rely on the tracking of dedicated optical markers for patient poses, which makes the surgical workflow more invasive, tedious, and expensive. Visual tracking has recently been proposed to measure the target anatomy in a markerless and effortless way, but the existing methods fail under real-world occlusion caused by intraoperative interventions. Furthermore, such methods are hardware-specific and not accurate enough for surgical applications. In this paper, we propose a RGB-D sensing-based markerless tracking method that is robust against occlusion. We design a new segmentation network that features dynamic region-of-interest prediction and robust 3D point cloud segmentation. As it is expensive to collect large-scale training data with occlusion instances, we also propose a new method to create synthetic RGB-D images for network training. Experimental results show that our proposed markerless tracking method outperforms recent state-of-the-art approaches by a large margin, especially when an occlusion exists. Furthermore, our method generalises well to new cameras and new target models, including a cadaver, without the need for network retraining. In practice, by using a high-quality commercial RGB-D camera, our proposed visual tracking method achieves an accuracy of 1-2 degress and 2-4 mm on a model knee, which meets the standard for clinical applications.