 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam Ryu's Submission to SIGMORPHON 2024 Shared Task on Subword Tokenization
Paper and Code
Oct 19, 2024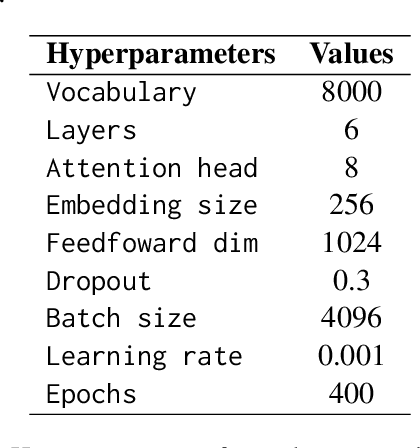
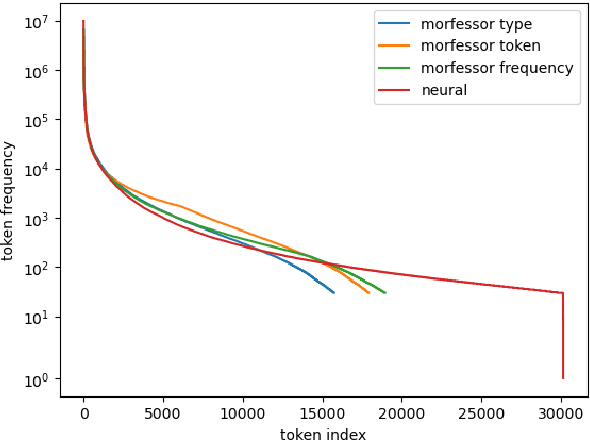


This papers presents the submission of team Ryu to the canceled SIGMORPHON 2024 shared task on subword tokenization. My submission explores whether morphological segmentation methods can be used as a part of subword tokenizers. I adopt two approaches: the statistical segmentation method Morfessor and a transformer based sequence-to-sequence (seq2seq) segmentation model in tokenizers. The prediction results show that morphological segmentation could be as effective as commonly used subword tokenizers. Additionally, I investigate how a tokenizer's vocabulary influences the performance of language models. A tokenizer with a balanced token frequency distribution tends to work better. A balanced token vocabulary can be achieved by keeping frequent words as unique tokens.