 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse ActionGen: Accelerating Diffusion Policy with Real-time Pruning
Jan 19, 2026Diffusion Policy has dominated action generation due to its strong capabilities for modeling multi-modal action distributions, but its multi-step denoising processes make it impractical for real-time visuomotor control. Existing caching-based acceleration methods typically rely on $\textit{static}$ schedules that fail to adapt to the $\textit{dynamics}$ of robot-environment interactions, thereby leading to suboptimal performance. In this paper, we propose $\underline{\textbf{S}}$parse $\underline{\textbf{A}}$ction$\underline{\textbf{G}}$en ($\textbf{SAG}$) for extremely sparse action generation. To accommodate the iterative interactions, SAG customizes a rollout-adaptive prune-then-reuse mechanism that first identifies prunable computations globally and then reuses cached activations to substitute them during action diffusion. To capture the rollout dynamics, SAG parameterizes an observation-conditioned diffusion pruner for environment-aware adaptation and instantiates it with a highly parameter- and inference-efficient design for real-time prediction. Furthermore, SAG introduces a one-for-all reusing strategy that reuses activations across both timesteps and blocks in a zig-zag manner, minimizing the global redundancy. Extensive experiments on multiple robotic benchmarks demonstrate that SAG achieves up to 4$\times$ generation speedup without sacrificing performance. Project Page: https://sparse-actiongen.github.io/.
TS-DP: Reinforcement Speculative Decoding For Temporal Adaptive Diffusion Policy Acceleration
Dec 13, 2025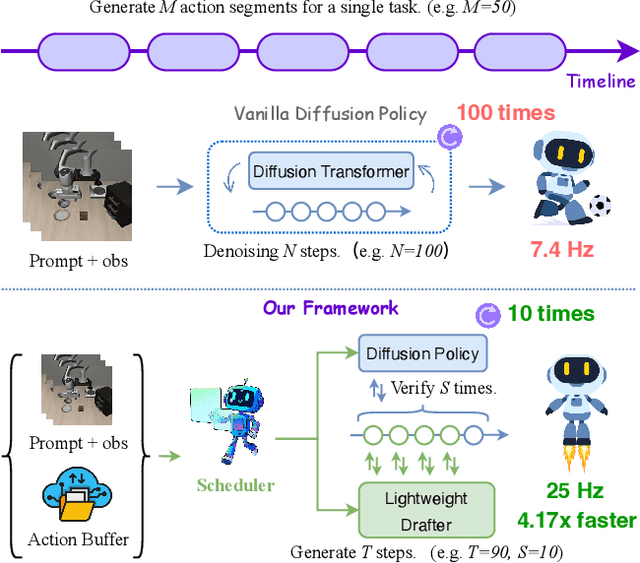
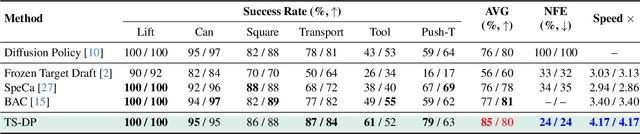

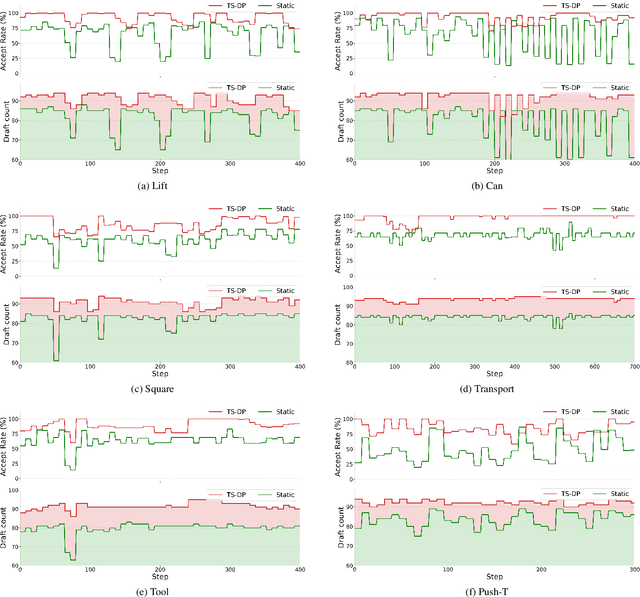
Diffusion Policy (DP) excels in embodied control but suffers from high inference latency and computational cost due to multiple iterative denoising steps. The temporal complexity of embodied tasks demands a dynamic and adaptable computation mode. Static and lossy acceleration methods, such as quantization, fail to handle such dynamic embodied tasks, while speculative decoding offers a lossless and adaptive yet underexplored alternative for DP. However, it is non-trivial to address the following challenges: how to match the base model's denoising quality at lower cost under time-varying task difficulty in embodied settings, and how to dynamically and interactively adjust computation based on task difficulty in such environments. In this paper, we propose Temporal-aware Reinforcement-based Speculative Diffusion Policy (TS-DP), the first framework that enables speculative decoding for DP with temporal adaptivity. First, to handle dynamic environments where task difficulty varies over time, we distill a Transformer-based drafter to imitate the base model and replace its costly denoising calls. Second, an RL-based scheduler further adapts to time-varying task difficulty by adjusting speculative parameters to maintain accuracy while improving efficiency. Extensive experiments across diverse embodied environments demonstrate that TS-DP achieves up to 4.17 times faster inference with over 94% accepted drafts, reaching an inference frequency of 25 Hz and enabling real-time diffusion-based control without performance degradation.
Block-wise Adaptive Caching for Accelerating Diffusion Policy
Jun 16, 2025Diffusion Policy has demonstrated strong visuomotor modeling capabilities, but its high computational cost renders it impractical for real-time robotic control. Despite huge redundancy across repetitive denoising steps, existing diffusion acceleration techniques fail to generalize to Diffusion Policy due to fundamental architectural and data divergences. In this paper, we propose Block-wise Adaptive Caching(BAC), a method to accelerate Diffusion Policy by caching intermediate action features. BAC achieves lossless action generation acceleration by adaptively updating and reusing cached features at the block level, based on a key observation that feature similarities vary non-uniformly across timesteps and locks. To operationalize this insight, we first propose the Adaptive Caching Scheduler, designed to identify optimal update timesteps by maximizing the global feature similarities between cached and skipped features. However, applying this scheduler for each block leads to signiffcant error surges due to the inter-block propagation of caching errors, particularly within Feed-Forward Network (FFN) blocks. To mitigate this issue, we develop the Bubbling Union Algorithm, which truncates these errors by updating the upstream blocks with signiffcant caching errors before downstream FFNs. As a training-free plugin, BAC is readily integrable with existing transformer-based Diffusion Policy and vision-language-action models. Extensive experiments on multiple robotic benchmarks demonstrate that BAC achieves up to 3x inference speedup for free.
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Jun 15, 2025Vision-Language-Action (VLA) models have attracted increasing attention for their strong control capabilities. However, their high computational cost and low execution frequency hinder their suitability for real-time tasks such as robotic manipulation and autonomous navigation. Existing VLA acceleration methods primarily focus on structural optimization, overlooking the fact that these models operate in sequential decision-making environments. As a result, temporal redundancy in sequential action generation and spatial redundancy in visual input remain unaddressed. To this end, we propose SP-VLA, a unified framework that accelerates VLA models by jointly scheduling models and pruning tokens. Specifically, we design an action-aware model scheduling mechanism that reduces temporal redundancy by dynamically switching between VLA model and a lightweight generator. Inspired by the human motion pattern of focusing on key decision points while relying on intuition for other actions, we categorize VLA actions into deliberative and intuitive, assigning the former to the VLA model and the latter to the lightweight generator, enabling frequency-adaptive execution through collaborative model scheduling. To address spatial redundancy, we further develop a spatio-semantic dual-aware token pruning method. Tokens are classified into spatial and semantic types and pruned based on their dual-aware importance to accelerate VLA inference. These two mechanisms work jointly to guide the VLA in focusing on critical actions and salient visual information, achieving effective acceleration while maintaining high accuracy. Experimental results demonstrate that our method achieves up to 1.5$\times$ acceleration with less than 3% drop in accuracy, outperforming existing approaches in multiple tasks.
SAMCL: Empowering SAM to Continually Learn from Dynamic Domains
Dec 06, 2024Segment Anything Model (SAM) struggles with segmenting objects in the open world, especially across diverse and dynamic domains. Continual segmentation (CS) is a potential technique to solve this issue, but a significant obstacle is the intractable balance between previous domains (stability) and new domains (plasticity) during CS. Furthermore, how to utilize two kinds of features of SAM, images and prompts, in an efficient and effective CS manner remains a significant hurdle. In this work, we propose a novel CS method, termed SAMCL, to address these challenges. It is the first study to empower SAM with the CS ability across dynamic domains. SAMCL decouples stability and plasticity during CS by two components: $\textit{AugModule}$ and $\textit{Module Selector}$. Specifically, SAMCL leverages individual $\textit{AugModule}$ to effectively and efficiently learn new relationships between images and prompts in each domain. $\textit{Module Selector}$ selects the appropriate module during testing, based on the inherent ability of SAM to distinguish between different domains. These two components enable SAMCL to realize a task-agnostic method without any interference across different domains. Experimental results demonstrate that SAMCL outperforms state-of-the-art methods, achieving an exceptionally low average forgetting of just $0.5$%, along with at least a $2.5$% improvement in transferring to unseen domains. Moreover, the tunable parameter consumption in AugModule is about $0.236$MB, marking at least a $23.3$% reduction compared to other fine-tuning methods.
Efficient Continual Learning with Low Memory Footprint For Edge Device
Jul 15, 2024



Continual learning(CL) is a useful technique to acquire dynamic knowledge continually. Although powerful cloud platforms can fully exert the ability of CL,e.g., customized recommendation systems, similar personalized requirements for edge devices are almost disregarded. This phenomenon stems from the huge resource overhead involved in training neural networks and overcoming the forgetting problem of CL. This paper focuses on these scenarios and proposes a compact algorithm called LightCL. Different from other CL methods bringing huge resource consumption to acquire generalizability among all tasks for delaying forgetting, LightCL compress the resource consumption of already generalized components in neural networks and uses a few extra resources to improve memory in other parts. We first propose two new metrics of learning plasticity and memory stability to seek generalizability during CL. Based on the discovery that lower and middle layers have more generalizability and deeper layers are opposite, we $\textit{Maintain Generalizability}$ by freezing the lower and middle layers. Then, we $\textit{Memorize Feature Patterns}$ to stabilize the feature extracting patterns of previous tasks to improve generalizability in deeper layers. In the experimental comparison, LightCL outperforms other SOTA methods in delaying forgetting and reduces at most $\textbf{6.16$\times$}$ memory footprint, proving the excellent performance of LightCL in efficiency. We also evaluate the efficiency of our method on an edge device, the Jetson Nano, which further proves our method's practical effectiveness.
Jump-teaching: Ultra Efficient and Robust Learning with Noisy Label
May 28, 2024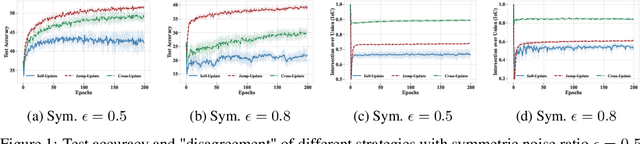
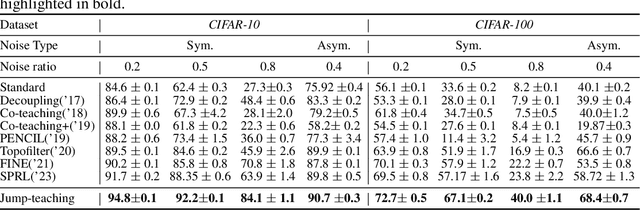
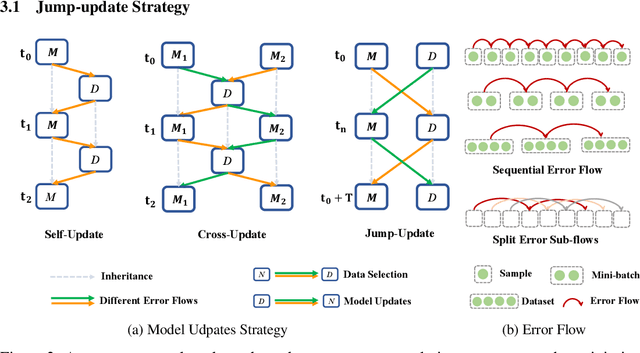

Sample selection is the most straightforward technique to combat label noise, aiming to distinguish mislabeled samples during training and avoid the degradation of the robustness of the model. In the workflow, $\textit{selecting possibly clean data}$ and $\textit{model update}$ are iterative. However, their interplay and intrinsic characteristics hinder the robustness and efficiency of learning with noisy labels: 1) The model chooses clean data with selection bias, leading to the accumulated error in the model update. 2) Most selection strategies leverage partner networks or supplementary information to mitigate label corruption, albeit with increased computation resources and lower throughput speed. Therefore, we employ only one network with the jump manner update to decouple the interplay and mine more semantic information from the loss for a more precise selection. Specifically, the selection of clean data for each model update is based on one of the prior models, excluding the last iteration. The strategy of model update exhibits a jump behavior in the form. Moreover, we map the outputs of the network and labels into the same semantic feature space, respectively. In this space, a detailed and simple loss distribution is generated to distinguish clean samples more effectively. Our proposed approach achieves almost up to $2.53\times$ speedup, $0.46\times$ peak memory footprint, and superior robustness over state-of-the-art works with various noise settings.