 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Continual Learning with Low Memory Footprint For Edge Device
Jul 15, 2024



Continual learning(CL) is a useful technique to acquire dynamic knowledge continually. Although powerful cloud platforms can fully exert the ability of CL,e.g., customized recommendation systems, similar personalized requirements for edge devices are almost disregarded. This phenomenon stems from the huge resource overhead involved in training neural networks and overcoming the forgetting problem of CL. This paper focuses on these scenarios and proposes a compact algorithm called LightCL. Different from other CL methods bringing huge resource consumption to acquire generalizability among all tasks for delaying forgetting, LightCL compress the resource consumption of already generalized components in neural networks and uses a few extra resources to improve memory in other parts. We first propose two new metrics of learning plasticity and memory stability to seek generalizability during CL. Based on the discovery that lower and middle layers have more generalizability and deeper layers are opposite, we $\textit{Maintain Generalizability}$ by freezing the lower and middle layers. Then, we $\textit{Memorize Feature Patterns}$ to stabilize the feature extracting patterns of previous tasks to improve generalizability in deeper layers. In the experimental comparison, LightCL outperforms other SOTA methods in delaying forgetting and reduces at most $\textbf{6.16$\times$}$ memory footprint, proving the excellent performance of LightCL in efficiency. We also evaluate the efficiency of our method on an edge device, the Jetson Nano, which further proves our method's practical effectiveness.
Jump-teaching: Ultra Efficient and Robust Learning with Noisy Label
May 28, 2024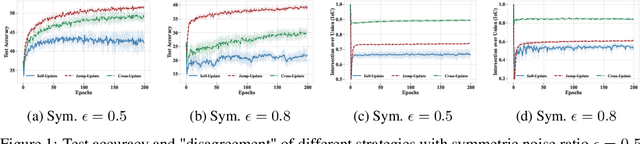
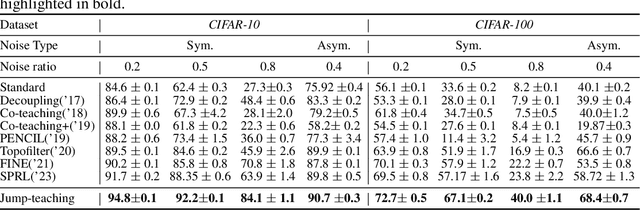
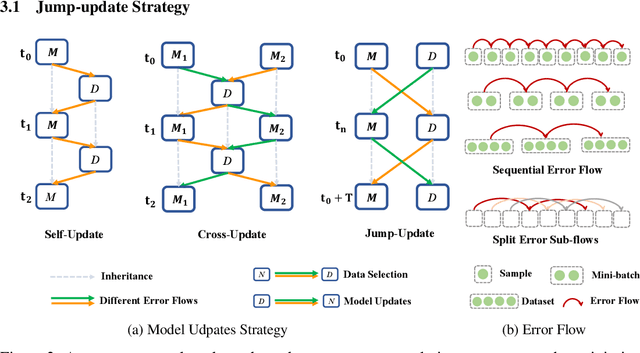

Sample selection is the most straightforward technique to combat label noise, aiming to distinguish mislabeled samples during training and avoid the degradation of the robustness of the model. In the workflow, $\textit{selecting possibly clean data}$ and $\textit{model update}$ are iterative. However, their interplay and intrinsic characteristics hinder the robustness and efficiency of learning with noisy labels: 1) The model chooses clean data with selection bias, leading to the accumulated error in the model update. 2) Most selection strategies leverage partner networks or supplementary information to mitigate label corruption, albeit with increased computation resources and lower throughput speed. Therefore, we employ only one network with the jump manner update to decouple the interplay and mine more semantic information from the loss for a more precise selection. Specifically, the selection of clean data for each model update is based on one of the prior models, excluding the last iteration. The strategy of model update exhibits a jump behavior in the form. Moreover, we map the outputs of the network and labels into the same semantic feature space, respectively. In this space, a detailed and simple loss distribution is generated to distinguish clean samples more effectively. Our proposed approach achieves almost up to $2.53\times$ speedup, $0.46\times$ peak memory footprint, and superior robustness over state-of-the-art works with various noise settings.