 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJump-teaching: Ultra Efficient and Robust Learning with Noisy Label
Paper and Code
May 28, 2024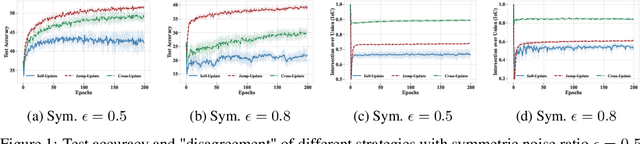
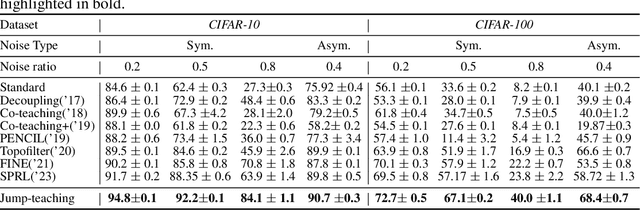
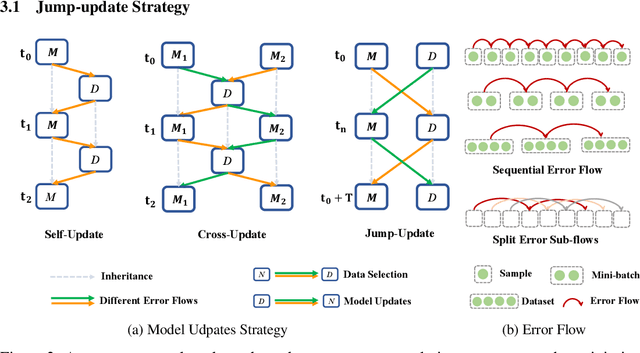

Sample selection is the most straightforward technique to combat label noise, aiming to distinguish mislabeled samples during training and avoid the degradation of the robustness of the model. In the workflow, $\textit{selecting possibly clean data}$ and $\textit{model update}$ are iterative. However, their interplay and intrinsic characteristics hinder the robustness and efficiency of learning with noisy labels: 1) The model chooses clean data with selection bias, leading to the accumulated error in the model update. 2) Most selection strategies leverage partner networks or supplementary information to mitigate label corruption, albeit with increased computation resources and lower throughput speed. Therefore, we employ only one network with the jump manner update to decouple the interplay and mine more semantic information from the loss for a more precise selection. Specifically, the selection of clean data for each model update is based on one of the prior models, excluding the last iteration. The strategy of model update exhibits a jump behavior in the form. Moreover, we map the outputs of the network and labels into the same semantic feature space, respectively. In this space, a detailed and simple loss distribution is generated to distinguish clean samples more effectively. Our proposed approach achieves almost up to $2.53\times$ speedup, $0.46\times$ peak memory footprint, and superior robustness over state-of-the-art works with various noise settings.