 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer-Centric Multimodal Prompt Generation for Large Language Model Based Identity-Aware Basketball Video Captioning
Jul 27, 2025Existing sports video captioning methods often focus on the action yet overlook player identities, limiting their applicability. Although some methods integrate extra information to generate identity-aware descriptions, the player identities are sometimes incorrect because the extra information is independent of the video content. This paper proposes a player-centric multimodal prompt generation network for identity-aware sports video captioning (LLM-IAVC), which focuses on recognizing player identities from a visual perspective. Specifically, an identity-related information extraction module (IRIEM) is designed to extract player-related multimodal embeddings. IRIEM includes a player identification network (PIN) for extracting visual features and player names, and a bidirectional semantic interaction module (BSIM) to link player features with video content for mutual enhancement. Additionally, a visual context learning module (VCLM) is designed to capture the key video context information. Finally, by integrating the outputs of the above modules as the multimodal prompt for the large language model (LLM), it facilitates the generation of descriptions with player identities. To support this work, we construct a new benchmark called NBA-Identity, a large identity-aware basketball video captioning dataset with 9,726 videos covering 9 major event types. The experimental results on NBA-Identity and VC-NBA-2022 demonstrate that our proposed model achieves advanced performance. Code and dataset are publicly available at https://github.com/Zeyu1226-mt/LLM-IAVC.
Modular-Cam: Modular Dynamic Camera-view Video Generation with LLM
Apr 16, 2025
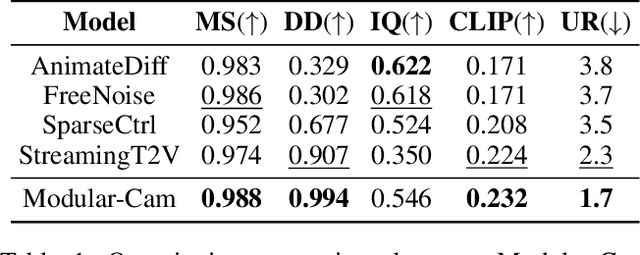
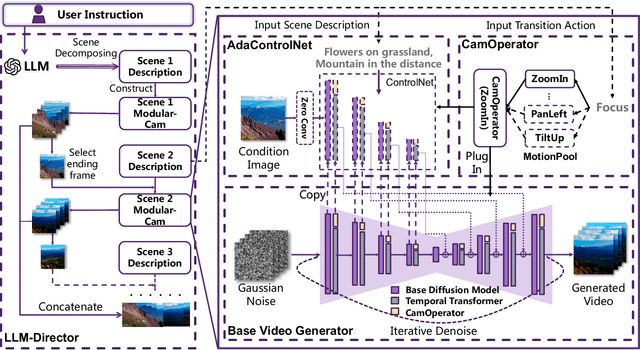

Text-to-Video generation, which utilizes the provided text prompt to generate high-quality videos, has drawn increasing attention and achieved great success due to the development of diffusion models recently. Existing methods mainly rely on a pre-trained text encoder to capture the semantic information and perform cross attention with the encoded text prompt to guide the generation of video. However, when it comes to complex prompts that contain dynamic scenes and multiple camera-view transformations, these methods can not decompose the overall information into separate scenes, as well as fail to smoothly change scenes based on the corresponding camera-views. To solve these problems, we propose a novel method, i.e., Modular-Cam. Specifically, to better understand a given complex prompt, we utilize a large language model to analyze user instructions and decouple them into multiple scenes together with transition actions. To generate a video containing dynamic scenes that match the given camera-views, we incorporate the widely-used temporal transformer into the diffusion model to ensure continuity within a single scene and propose CamOperator, a modular network based module that well controls the camera movements. Moreover, we propose AdaControlNet, which utilizes ControlNet to ensure consistency across scenes and adaptively adjusts the color tone of the generated video. Extensive qualitative and quantitative experiments prove our proposed Modular-Cam's strong capability of generating multi-scene videos together with its ability to achieve fine-grained control of camera movements. Generated results are available at https://modular-cam.github.io.