 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 08, 2022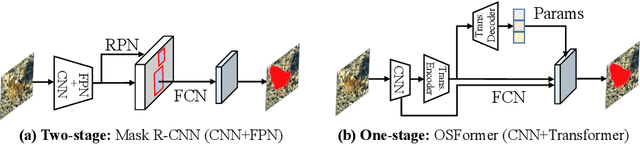
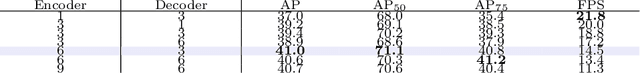

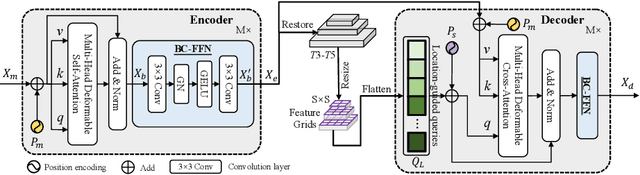
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.
Superpixel Segmentation Based on Spatially Constrained Subspace Clustering
Dec 11, 2020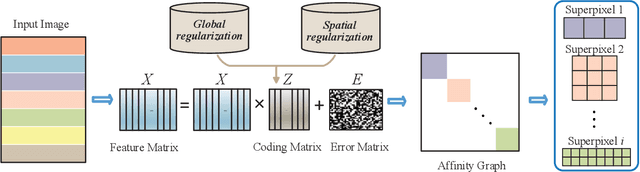
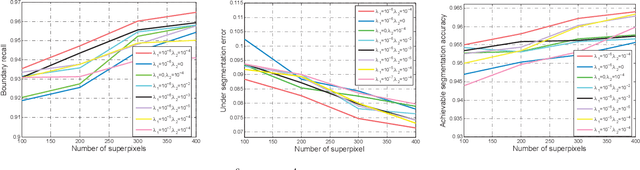

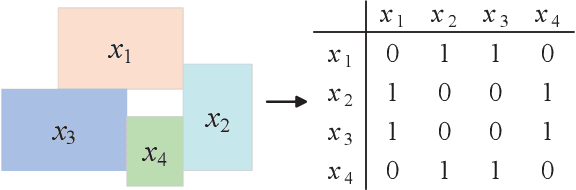
Superpixel segmentation aims at dividing the input image into some representative regions containing pixels with similar and consistent intrinsic properties, without any prior knowledge about the shape and size of each superpixel. In this paper, to alleviate the limitation of superpixel segmentation applied in practical industrial tasks that detailed boundaries are difficult to be kept, we regard each representative region with independent semantic information as a subspace, and correspondingly formulate superpixel segmentation as a subspace clustering problem to preserve more detailed content boundaries. We show that a simple integration of superpixel segmentation with the conventional subspace clustering does not effectively work due to the spatial correlation of the pixels within a superpixel, which may lead to boundary confusion and segmentation error when the correlation is ignored. Consequently, we devise a spatial regularization and propose a novel convex locality-constrained subspace clustering model that is able to constrain the spatial adjacent pixels with similar attributes to be clustered into a superpixel and generate the content-aware superpixels with more detailed boundaries. Finally, the proposed model is solved by an efficient alternating direction method of multipliers (ADMM) solver. Experiments on different standard datasets demonstrate that the proposed method achieves superior performance both quantitatively and qualitatively compared with some state-of-the-art methods.
Weakly Supervised Learning with Region and Box-level Annotations for Salient Instance Segmentation
Aug 19, 2020
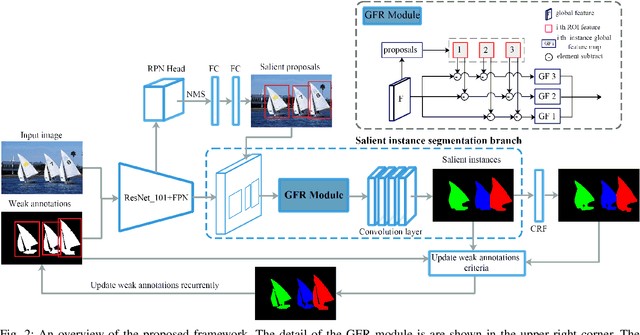


Salient instance segmentation is a new challenging task that received widespread attention in saliency detection area. Due to the limited scale of the existing dataset and the high mask annotations cost, it is difficult to train a salient instance neural network completely. In this paper, we appeal to train a salient instance segmentation framework by a weakly supervised source without resorting to laborious labeling. We present a cyclic global context salient instance segmentation network (CGCNet), which is supervised by the combination of the binary salient regions and bounding boxes from the existing saliency detection datasets. For a precise pixel-level location, a global feature refining layer is introduced that dilates the context features of each salient instance to the global context in the image. Meanwhile, a labeling updating scheme is embedded in the proposed framework to online update the weak annotations for next iteration. Experiment results demonstrate that the proposed end-to-end network trained by weakly supervised annotations can be competitive to the existing fully supervised salient instance segmentation methods. Without bells and whistles, our proposed method achieves a mask AP of 57.13%, which outperforms the best fully supervised methods and establishes new states of the art for weakly supervised salient instance segmentation.
Salient Instance Segmentation via Subitizing and Clustering
Sep 29, 2019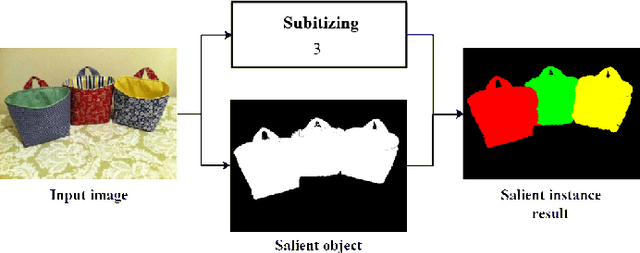
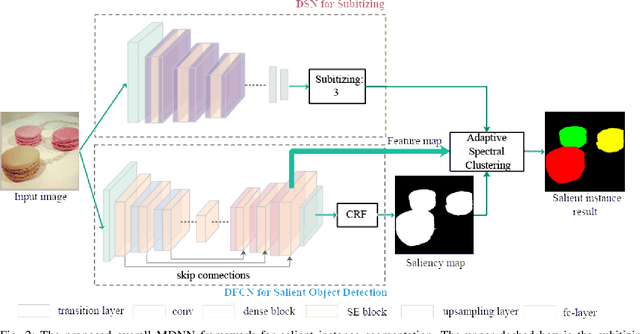

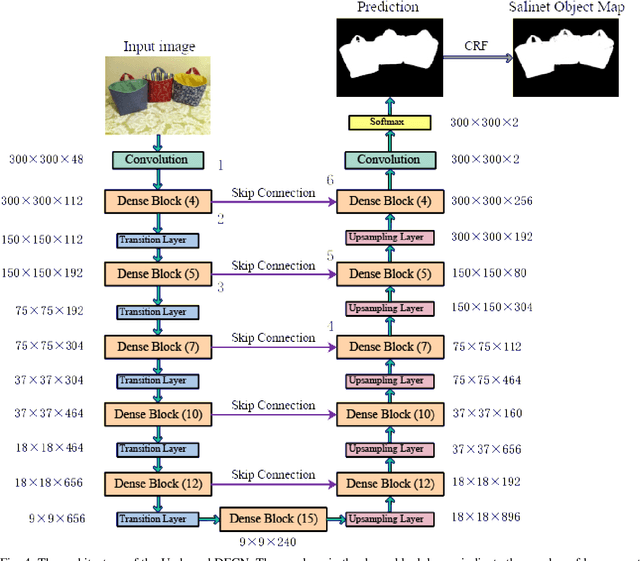
The goal of salient region detection is to identify the regions of an image that attract the most attention. Many methods have achieved state-of-the-art performance levels on this task. Recently, salient instance segmentation has become an even more challenging task than traditional salient region detection; however, few of the existing methods have concentrated on this underexplored problem. Unlike the existing methods, which usually employ object proposals to roughly count and locate object instances, our method applies salient objects subitizing to predict an accurate number of instances for salient instance segmentation. In this paper, we propose a multitask densely connected neural network (MDNN) to segment salient instances in an image. In contrast to existing approaches, our framework is proposal-free and category-independent. The MDNN contains two parallel branches: the first is a densely connected subitizing network (DSN) used for subitizing prediction; the second is a densely connected fully convolutional network (DFCN) used for salient region detection. The MDNN simultaneously outputs saliency maps and salient object subitizing. Then, an adaptive deep feature-based spectral clustering operation segments the salient regions into instances based on the subitizing and saliency maps. The experimental results on both salient region detection and salient instance segmentation datasets demonstrate the satisfactory performance of our framework. Notably, its APr@0.5 and Apr@0.7 reaches 73.46% and 60.14% in the salient instance dataset, substantially higher than the results achieved by the state-of-the-art algorithm.
EasyConvPooling: Random Pooling with Easy Convolution for Accelerating Training and Testing
Jun 05, 2018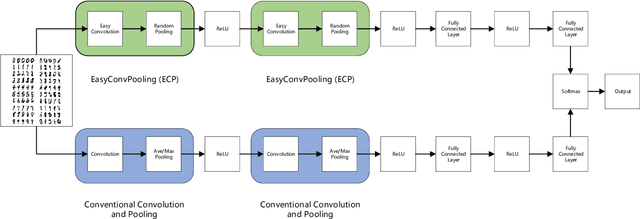
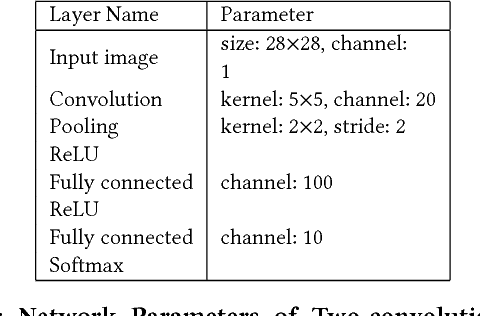
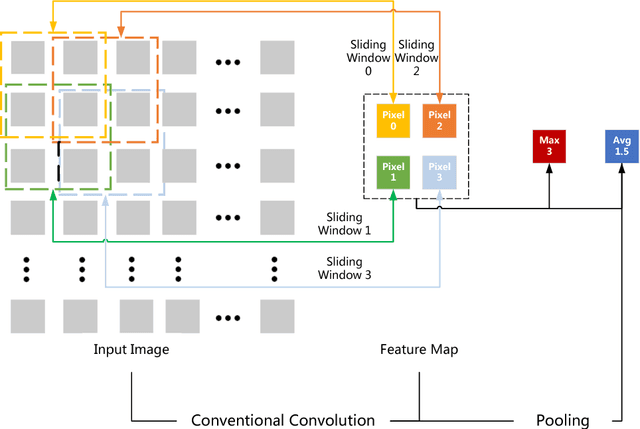
Convolution operations dominate the overall execution time of Convolutional Neural Networks (CNNs). This paper proposes an easy yet efficient technique for both Convolutional Neural Network training and testing. The conventional convolution and pooling operations are replaced by Easy Convolution and Random Pooling (ECP). In ECP, we randomly select one pixel out of four and only conduct convolution operations of the selected pixel. As a result, only a quarter of the conventional convolution computations are needed. Experiments demonstrate that the proposed EasyConvPooling can achieve 1.45x speedup on training time and 1.64x on testing time. What's more, a speedup of 5.09x on pure Easy Convolution operations is obtained compared to conventional convolution operations.