 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Representation Decomposition for Rate-Invariant Speaker Verification
May 28, 2022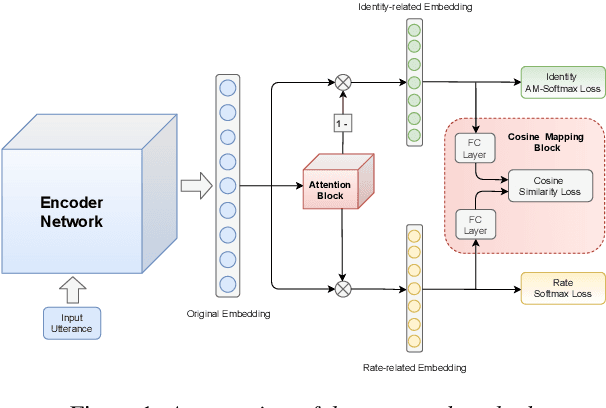

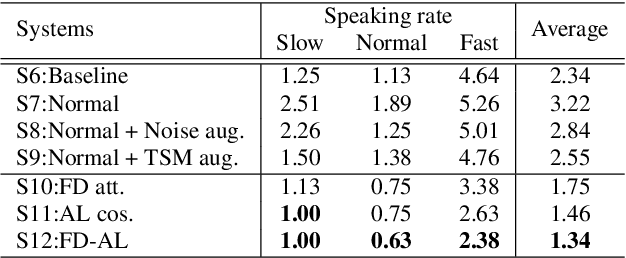
While promising performance for speaker verification has been achieved by deep speaker embeddings, the advantage would reduce in the case of speaking-style variability. Speaking rate mismatch is often observed in practical speaker verification systems, which may actually degrade the system performance. To reduce intra-class discrepancy caused by speaking rate, we propose a deep representation decomposition approach with adversarial learning to learn speaking rate-invariant speaker embeddings. Specifically, adopting an attention block, we decompose the original embedding into an identity-related component and a rate-related component through multi-task training. Additionally, to reduce the latent relationship between the two decomposed components, we further propose a cosine mapping block to train the parameters adversarially to minimize the cosine similarity between the two decomposed components. As a result, identity-related features become robust to speaking rate and then are used for verification. Experiments are conducted on VoxCeleb1 data and HI-MIA data to demonstrate the effectiveness of our proposed approach.
Graph Convolutional Network Based Semi-Supervised Learning on Multi-Speaker Meeting Data
Apr 25, 2022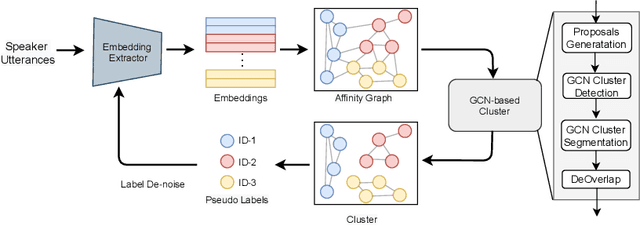

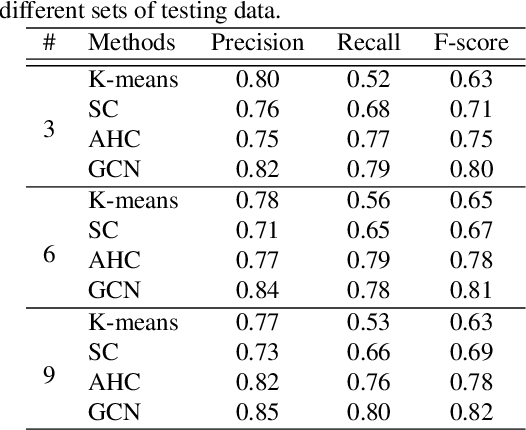

Unsupervised clustering on speakers is becoming increasingly important for its potential uses in semi-supervised learning. In reality, we are often presented with enormous amounts of unlabeled data from multi-party meetings and discussions. An effective unsupervised clustering approach would allow us to significantly increase the amount of training data without additional costs for annotations. Recently, methods based on graph convolutional networks (GCN) have received growing attention for unsupervised clustering, as these methods exploit the connectivity patterns between nodes to improve learning performance. In this work, we present a GCN-based approach for semi-supervised learning. Given a pre-trained embedding extractor, a graph convolutional network is trained on the labeled data and clusters unlabeled data with "pseudo-labels". We present a self-correcting training mechanism that iteratively runs the cluster-train-correct process on pseudo-labels. We show that this proposed approach effectively uses unlabeled data and improves speaker recognition accuracy.