 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFlow-TTS: A Rectified Flow Model for High-fidelity Text-to-Speech
Sep 29, 2023The diffusion models including Denoising Diffusion Probabilistic Models (DDPM) and score-based generative models have demonstrated excellent performance in speech synthesis tasks. However, its effectiveness comes at the cost of numerous sampling steps, resulting in prolonged sampling time required to synthesize high-quality speech. This drawback hinders its practical applicability in real-world scenarios. In this paper, we introduce ReFlow-TTS, a novel rectified flow based method for speech synthesis with high-fidelity. Specifically, our ReFlow-TTS is simply an Ordinary Differential Equation (ODE) model that transports Gaussian distribution to the ground-truth Mel-spectrogram distribution by straight line paths as much as possible. Furthermore, our proposed approach enables high-quality speech synthesis with a single sampling step and eliminates the need for training a teacher model. Our experiments on LJSpeech Dataset show that our ReFlow-TTS method achieves the best performance compared with other diffusion based models. And the ReFlow-TTS with one step sampling achieves competitive performance compared with existing one-step TTS models.
Community Detection Graph Convolutional Network for Overlap-Aware Speaker Diarization
Jun 26, 2023



The clustering algorithm plays a crucial role in speaker diarization systems. However, traditional clustering algorithms suffer from the complex distribution of speaker embeddings and lack of digging potential relationships between speakers in a session. We propose a novel graph-based clustering approach called Community Detection Graph Convolutional Network (CDGCN) to improve the performance of the speaker diarization system. The CDGCN-based clustering method consists of graph generation, sub-graph detection, and Graph-based Overlapped Speech Detection (Graph-OSD). Firstly, the graph generation refines the local linkages among speech segments. Secondly the sub-graph detection finds the optimal global partition of the speaker graph. Finally, we view speaker clustering for overlap-aware speaker diarization as an overlapped community detection task and design a Graph-OSD component to output overlap-aware labels. By capturing local and global information, the speaker diarization system with CDGCN clustering outperforms the traditional Clustering-based Speaker Diarization (CSD) systems on the DIHARD III corpus.
* Accepted by ICASSP2023
Deep Representation Decomposition for Rate-Invariant Speaker Verification
May 28, 2022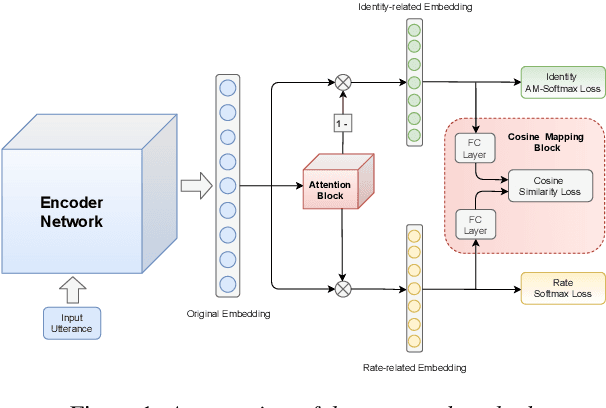

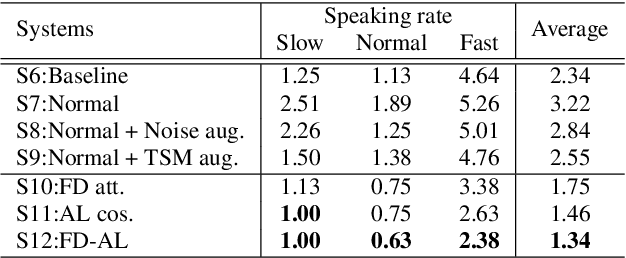
While promising performance for speaker verification has been achieved by deep speaker embeddings, the advantage would reduce in the case of speaking-style variability. Speaking rate mismatch is often observed in practical speaker verification systems, which may actually degrade the system performance. To reduce intra-class discrepancy caused by speaking rate, we propose a deep representation decomposition approach with adversarial learning to learn speaking rate-invariant speaker embeddings. Specifically, adopting an attention block, we decompose the original embedding into an identity-related component and a rate-related component through multi-task training. Additionally, to reduce the latent relationship between the two decomposed components, we further propose a cosine mapping block to train the parameters adversarially to minimize the cosine similarity between the two decomposed components. As a result, identity-related features become robust to speaking rate and then are used for verification. Experiments are conducted on VoxCeleb1 data and HI-MIA data to demonstrate the effectiveness of our proposed approach.
XMUSPEECH System for VoxCeleb Speaker Recognition Challenge 2021
Sep 06, 2021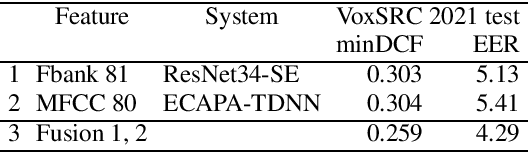
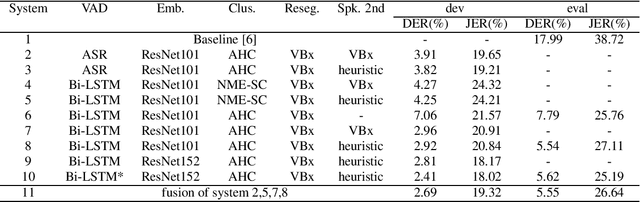


This paper describes the XMUSPEECH speaker recognition and diarisation systems for the VoxCeleb Speaker Recognition Challenge 2021. For track 2, we evaluate two systems including ResNet34-SE and ECAPA-TDNN. For track 4, an important part of our system is VAD module which greatly improves the performance. Our best submission on the track 4 obtained on the evaluation set DER 5.54% and JER 27.11%, while the performance on the development set is DER 2.92% and JER 20.84%.