 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting DirectSAM for Semantic Contour Extraction in Remote Sensing Images
Oct 08, 2024
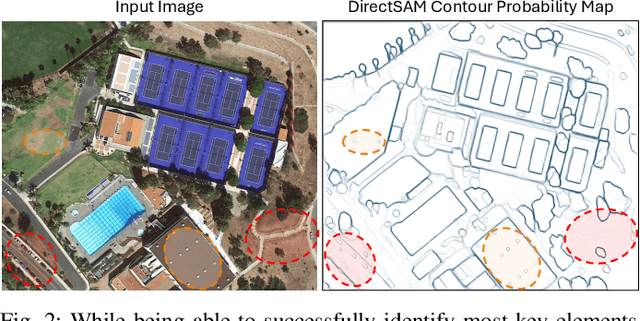


The Direct Segment Anything Model (DirectSAM) excels in class-agnostic contour extraction. In this paper, we explore its use by applying it to optical remote sensing imagery, where semantic contour extraction-such as identifying buildings, road networks, and coastlines-holds significant practical value. Those applications are currently handled via training specialized small models separately on small datasets in each domain. We introduce a foundation model derived from DirectSAM, termed DirectSAM-RS, which not only inherits the strong segmentation capability acquired from natural images, but also benefits from a large-scale dataset we created for remote sensing semantic contour extraction. This dataset comprises over 34k image-text-contour triplets, making it at least 30 times larger than individual dataset. DirectSAM-RS integrates a prompter module: a text encoder and cross-attention layers attached to the DirectSAM architecture, which allows flexible conditioning on target class labels or referring expressions. We evaluate the DirectSAM-RS in both zero-shot and fine-tuning setting, and demonstrate that it achieves state-of-the-art performance across several downstream benchmarks.
ReFlow-TTS: A Rectified Flow Model for High-fidelity Text-to-Speech
Sep 29, 2023The diffusion models including Denoising Diffusion Probabilistic Models (DDPM) and score-based generative models have demonstrated excellent performance in speech synthesis tasks. However, its effectiveness comes at the cost of numerous sampling steps, resulting in prolonged sampling time required to synthesize high-quality speech. This drawback hinders its practical applicability in real-world scenarios. In this paper, we introduce ReFlow-TTS, a novel rectified flow based method for speech synthesis with high-fidelity. Specifically, our ReFlow-TTS is simply an Ordinary Differential Equation (ODE) model that transports Gaussian distribution to the ground-truth Mel-spectrogram distribution by straight line paths as much as possible. Furthermore, our proposed approach enables high-quality speech synthesis with a single sampling step and eliminates the need for training a teacher model. Our experiments on LJSpeech Dataset show that our ReFlow-TTS method achieves the best performance compared with other diffusion based models. And the ReFlow-TTS with one step sampling achieves competitive performance compared with existing one-step TTS models.