 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Pre-trained Indeterminate Speaker Representation Model for Speaker Diarization and Speaker Verification
Paper and Code
May 16, 2022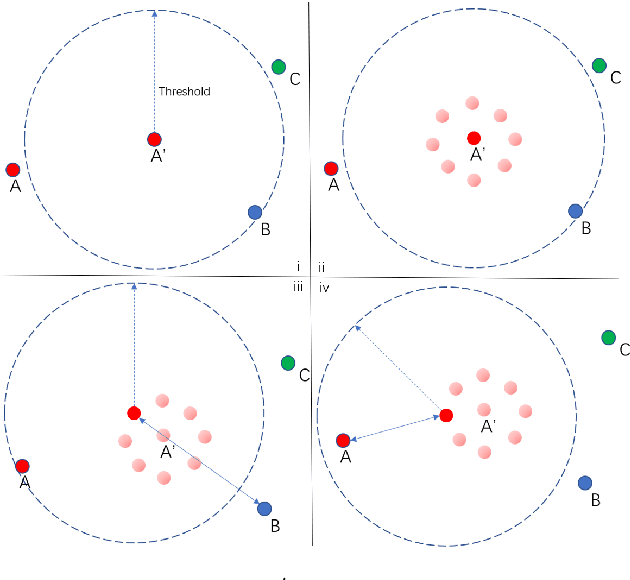

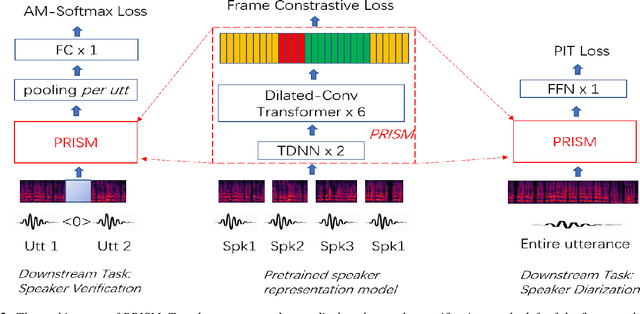

Speaker embedding has been a fundamental feature for speaker-related tasks such as verification, clustering, and diarization. Traditionally, speaker embeddings are represented as fixed vectors in high-dimensional space. This could lead to biased estimations, especially when handling shorter utterances. In this paper we propose to represent a speaker utterance as "floating" vector whose state is indeterminate without knowing the context. The state of a speaker representation is jointly determined by itself, other speech from the same speaker, as well as other speakers it is being compared to. The content of the speech also contributes to determining the final state of a speaker representation. We pre-train an indeterminate speaker representation model that estimates the state of an utterance based on the context. The pre-trained model can be fine-tuned for downstream tasks such as speaker verification, speaker clustering, and speaker diarization. Substantial improvements are observed across all downstream tasks.