 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMoE: An Efficient MoE by Orchestrating Atomic Experts at Scale
Feb 05, 2026Mixture-of-Experts (MoE) architectures are evolving towards finer granularity to improve parameter efficiency. However, existing MoE designs face an inherent trade-off between the granularity of expert specialization and hardware execution efficiency. We propose OmniMoE, a system-algorithm co-designed framework that pushes expert granularity to its logical extreme. OmniMoE introduces vector-level Atomic Experts, enabling scalable routing and execution within a single MoE layer, while retaining a shared dense MLP branch for general-purpose processing. Although this atomic design maximizes capacity, it poses severe challenges for routing complexity and memory access. To address these, OmniMoE adopts a system-algorithm co-design: (i) a Cartesian Product Router that decomposes the massive index space to reduce routing complexity from O(N) to O(sqrt(N)); and (ii) Expert-Centric Scheduling that inverts the execution order to turn scattered, memory-bound lookups into efficient dense matrix operations. Validated on seven benchmarks, OmniMoE (with 1.7B active parameters) achieves 50.9% zero-shot accuracy across seven benchmarks, outperforming coarse-grained (e.g., DeepSeekMoE) and fine-grained (e.g., PEER) baselines. Crucially, OmniMoE reduces inference latency from 73ms to 6.7ms (a 10.9-fold speedup) compared to PEER, demonstrating that massive-scale fine-grained MoE can be fast and accurate. Our code is open-sourced at https://github.com/flash-algo/omni-moe.
Towards Automated Kernel Generation in the Era of LLMs
Jan 26, 2026The performance of modern AI systems is fundamentally constrained by the quality of their underlying kernels, which translate high-level algorithmic semantics into low-level hardware operations. Achieving near-optimal kernels requires expert-level understanding of hardware architectures and programming models, making kernel engineering a critical but notoriously time-consuming and non-scalable process. Recent advances in large language models (LLMs) and LLM-based agents have opened new possibilities for automating kernel generation and optimization. LLMs are well-suited to compress expert-level kernel knowledge that is difficult to formalize, while agentic systems further enable scalable optimization by casting kernel development as an iterative, feedback-driven loop. Rapid progress has been made in this area. However, the field remains fragmented, lacking a systematic perspective for LLM-driven kernel generation. This survey addresses this gap by providing a structured overview of existing approaches, spanning LLM-based approaches and agentic optimization workflows, and systematically compiling the datasets and benchmarks that underpin learning and evaluation in this domain. Moreover, key open challenges and future research directions are further outlined, aiming to establish a comprehensive reference for the next generation of automated kernel optimization. To keep track of this field, we maintain an open-source GitHub repository at https://github.com/flagos-ai/awesome-LLM-driven-kernel-generation.
TransXSSM: A Hybrid Transformer State Space Model with Unified Rotary Position Embedding
Jun 12, 2025Transformers exhibit proficiency in capturing long-range dependencies, whereas State Space Models (SSMs) facilitate linear-time sequence modeling. Notwithstanding their synergistic potential, the integration of these architectures presents a significant challenge, primarily attributable to a fundamental incongruity in their respective positional encoding mechanisms: Transformers rely on explicit Rotary Position Embeddings (RoPE), while SSMs leverage implicit positional representations via convolutions. This divergence often precipitates discontinuities and suboptimal performance. To address this impediment, we propose a unified rotary position embedding (Unified RoPE) methodology, thereby establishing a consistent positional encoding framework for both self-attention and state-space components. Using this Unified RoPE, we introduce TransXSSM, a hybrid architecture that coherently integrates the Transformer and SSM layers under this unified positional encoding scheme. At a 4K sequence length, TransXSSM exhibits training and inference speeds that are 42.3\% and 29.5\% faster, respectively, relative to standard Transformer models. It also delivers higher accuracy: under comparable settings, it surpasses a Transformer baseline by over 4\% on language modeling benchmarks.TransXSSM furthermore scales more effectively: TransXSSM-1.3B gains 7.22\% in average accuracy over its 320M version (versus about 6\% gains for equivalent Transformers or SSMs). Our results show that unified positional encoding resolves positional incompatibility in hybrid models, enabling efficient, high-performance long-context modeling.
Concise Reasoning, Big Gains: Pruning Long Reasoning Trace with Difficulty-Aware Prompting
May 26, 2025Existing chain-of-thought (CoT) distillation methods can effectively transfer reasoning abilities to base models but suffer from two major limitations: excessive verbosity of reasoning traces and inadequate adaptability to problem difficulty. Long reasoning traces significantly increase inference costs, and uniform-length solutions prevent base models from learning adaptive reasoning strategies. To address these issues, we propose a difficulty-aware prompting (DAP) method to dynamically shorten reasoning traces without performance loss. In our approach, a large teacher model first judges each problem's difficulty and then rewrites its reasoning traces to an appropriate shorter length, yielding concise yet complete reasoning traces. Leveraging the DAP pipeline, we curate a distilled dataset called LiteCoT consisting of 100K concise reasoning examples, with solutions averaging only 720 tokens (an order of magnitude shorter than typical CoTs). Using LiteCoT, we distilled a new family of reasoning models called Liter (1.5B, 7B, and 32B) based on the Qwen2.5 architecture. Experiments show that a student model fine-tuned on just 100K of these difficulty-pruned CoT samples outperforms a model distilled on 800K original Long CoT samples, while significantly reducing training and inference costs. Our method also generalizes well: across 11 diverse benchmarks, the shorter difficulty-aware CoTs achieve equal or better accuracy than Long chains, using far fewer tokens. For example, on the challenging AIME24 exam, our approach reaches $74.2\%$ Pass@1 using only about 5K inference tokens, surpassing other methods that consume many more tokens. Our code and data are available at https://github.com/Evanwu1125/LiteCoT.
Wonderful Matrices: Combining for a More Efficient and Effective Foundation Model Architecture
Dec 16, 2024In order to make the foundation model more efficient and effective, our idea is combining sequence transformation and state transformation. First, we prove the availability of rotary position embedding in the state space duality algorithm, which reduces the perplexity of the hybrid quadratic causal self-attention and state space duality by more than 4%, to ensure that the combining sequence transformation unifies position encoding. Second, we propose dynamic mask attention, which maintains 100% accuracy in the more challenging multi-query associative recall task, improving by more than 150% compared to quadratic causal self-attention and state space duality, to ensure that the combining sequence transformation selectively filters relevant information. Third, we design cross domain mixture of experts, which makes the computational speed of expert retrieval with more than 1024 experts 8 to 10 times faster than the mixture of experts, to ensure that the combining state transformation quickly retrieval mixture. Finally, we summarize these matrix algorithms that can form the foundation model: Wonderful Matrices, which can be a competitor to popular model architectures.
Cheems: Wonderful Matrices More Efficient and More Effective Architecture
Jul 25, 2024



Recent studies have shown that, relative position encoding performs well in selective state space model scanning algorithms, and the architecture that balances SSM and Attention enhances the efficiency and effectiveness of the algorithm, while the sparse activation of the mixture of experts reduces the training cost. I studied the effectiveness of using different position encodings in structured state space dual algorithms, and the more effective SSD-Attn internal and external function mixing method, and designed a more efficient cross domain mixture of experts. I found that the same matrix is very wonderful in different algorithms, which allows us to establish a new hybrid sparse architecture: Cheems. Compared with other hybrid architectures, it is more efficient and more effective in language modeling tasks.
OTCE: Hybrid SSM and Attention with Cross Domain Mixture of Experts to construct Observer-Thinker-Conceiver-Expresser
Jun 25, 2024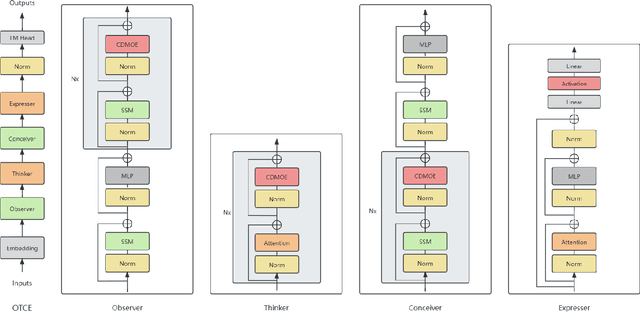



Recent research has shown that combining Mamba with Transformer architecture, which has selective state space and quadratic self-attention mechanism, outperforms using Mamba or Transformer architecture alone in language modeling tasks. The quadratic self-attention mechanism effectively alleviates the shortcomings of selective state space in handling long-term dependencies of any element in the sequence. We propose a position information injection method that connects the selective state space model with the quadratic attention, and integrates these two architectures with hybrid experts with cross-sharing domains, so that we can enjoy the advantages of both. We design a new architecture with a more biomimetic idea: Observer-Thinker-Conceiver-Expresser (OTCE), which can compete with well-known medium-scale open-source language models on a small scale in language modeling tasks.