 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTCE: Hybrid SSM and Attention with Cross Domain Mixture of Experts to construct Observer-Thinker-Conceiver-Expresser
Paper and Code
Jun 25, 2024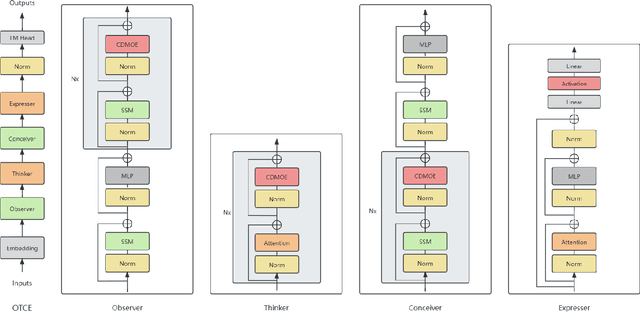



Recent research has shown that combining Mamba with Transformer architecture, which has selective state space and quadratic self-attention mechanism, outperforms using Mamba or Transformer architecture alone in language modeling tasks. The quadratic self-attention mechanism effectively alleviates the shortcomings of selective state space in handling long-term dependencies of any element in the sequence. We propose a position information injection method that connects the selective state space model with the quadratic attention, and integrates these two architectures with hybrid experts with cross-sharing domains, so that we can enjoy the advantages of both. We design a new architecture with a more biomimetic idea: Observer-Thinker-Conceiver-Expresser (OTCE), which can compete with well-known medium-scale open-source language models on a small scale in language modeling tasks.