 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMVI: Unifying Heterogeneous Attributes with Natural Neighbors for Missing Value Inference
Jan 08, 2026Missing value imputation is a fundamental challenge in machine intelligence, heavily dependent on data completeness. Current imputation methods often handle numerical and categorical attributes independently, overlooking critical interdependencies among heterogeneous features. To address these limitations, we propose a novel imputation approach that explicitly models cross-type feature dependencies within a unified framework. Our method leverages both complete and incomplete instances to ensure accurate and consistent imputation in tabular data. Extensive experimental results demonstrate that the proposed approach achieves superior performance over existing techniques and significantly enhances downstream machine learning tasks, providing a robust solution for real-world systems with missing data.
Chameleon: On the Scene Diversity and Domain Variety of AI-Generated Videos Detection
Mar 09, 2025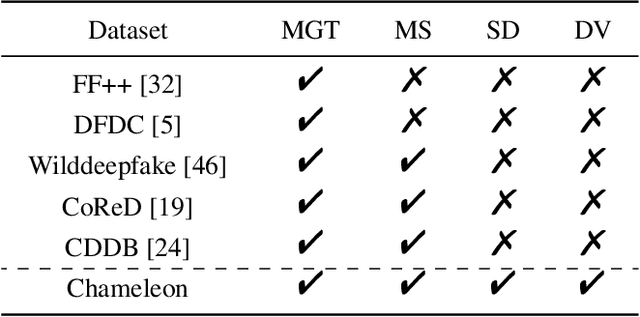

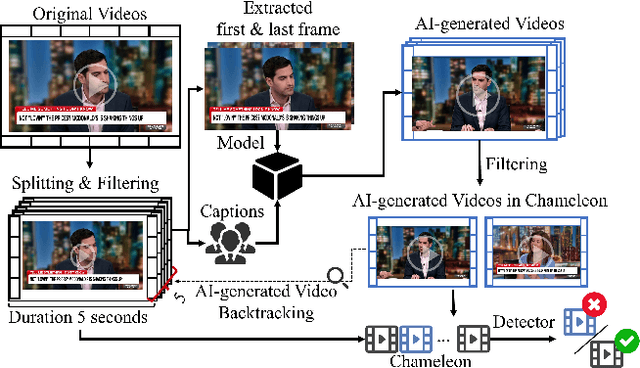
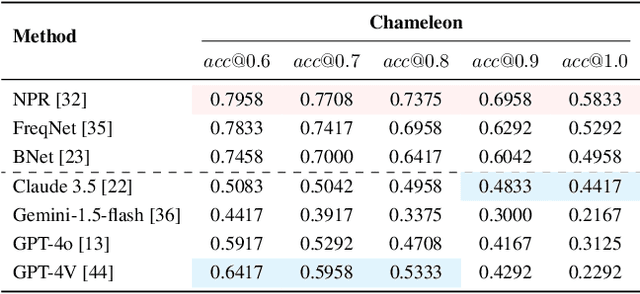
Artificial intelligence generated content (AIGC), known as DeepFakes, has emerged as a growing concern because it is being utilized as a tool for spreading disinformation. While much research exists on identifying AI-generated text and images, research on detecting AI-generated videos is limited. Existing datasets for AI-generated videos detection exhibit limitations in terms of diversity, complexity, and realism. To address these issues, this paper focuses on AI-generated videos detection and constructs a diverse dataset named Chameleon. We generate videos through multiple generation tools and various real video sources. At the same time, we preserve the videos' real-world complexity, including scene switches and dynamic perspective changes, and expand beyond face-centered detection to include human actions and environment generation. Our work bridges the gap between AI-generated dataset construction and real-world forensic needs, offering a valuable benchmark to counteract the evolving threats of AI-generated content.
Composited-Nested-Learning with Data Augmentation for Nested Named Entity Recognition
Jun 18, 2024



Nested Named Entity Recognition (NNER) focuses on addressing overlapped entity recognition. Compared to Flat Named Entity Recognition (FNER), annotated resources are scarce in the corpus for NNER. Data augmentation is an effective approach to address the insufficient annotated corpus. However, there is a significant lack of exploration in data augmentation methods for NNER. Due to the presence of nested entities in NNER, existing data augmentation methods cannot be directly applied to NNER tasks. Therefore, in this work, we focus on data augmentation for NNER and resort to more expressive structures, Composited-Nested-Label Classification (CNLC) in which constituents are combined by nested-word and nested-label, to model nested entities. The dataset is augmented using the Composited-Nested-Learning (CNL). In addition, we propose the Confidence Filtering Mechanism (CFM) for a more efficient selection of generated data. Experimental results demonstrate that this approach results in improvements in ACE2004 and ACE2005 and alleviates the impact of sample imbalance.
PyPop7: A Pure-Python Library for Population-Based Black-Box Optimization
Dec 12, 2022In this paper, we present a pure-Python open-source library, called PyPop7, for black-box optimization (BBO). It provides a unified and modular interface for more than 60 versions and variants of different black-box optimization algorithms, particularly population-based optimizers, which can be classified into 12 popular families: Evolution Strategies (ES), Natural Evolution Strategies (NES), Estimation of Distribution Algorithms (EDA), Cross-Entropy Method (CEM), Differential Evolution (DE), Particle Swarm Optimizer (PSO), Cooperative Coevolution (CC), Simulated Annealing (SA), Genetic Algorithms (GA), Evolutionary Programming (EP), Pattern Search (PS), and Random Search (RS). It also provides many examples, interesting tutorials, and full-fledged API documentations. Through this new library, we expect to provide a well-designed platform for benchmarking of optimizers and promote their real-world applications, especially for large-scale BBO. Its source code and documentations are available at https://github.com/Evolutionary-Intelligence/pypop and https://pypop.readthedocs.io/en/latest, respectively.
MSA-GCN:Multiscale Adaptive Graph Convolution Network for Gait Emotion Recognition
Sep 19, 2022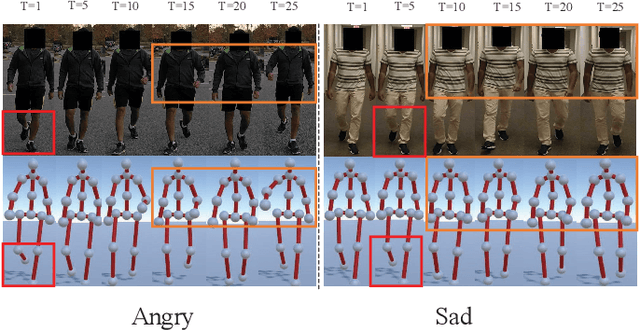
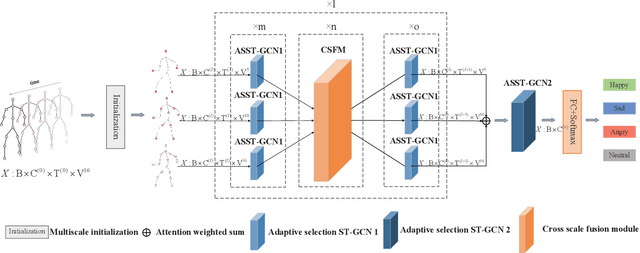
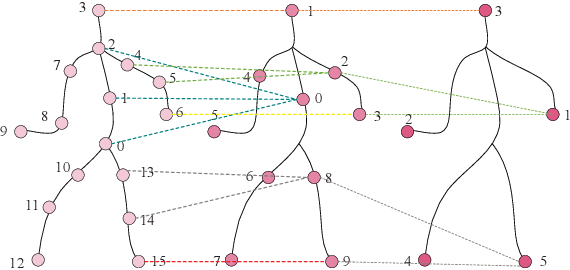
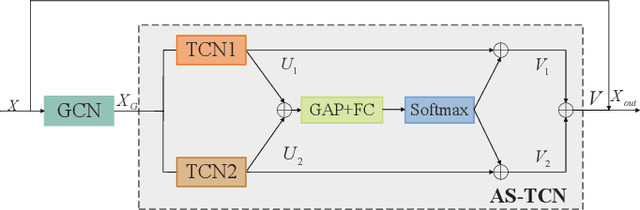
Gait emotion recognition plays a crucial role in the intelligent system. Most of the existing methods recognize emotions by focusing on local actions over time. However, they ignore that the effective distances of different emotions in the time domain are different, and the local actions during walking are quite similar. Thus, emotions should be represented by global states instead of indirect local actions. To address these issues, a novel Multi Scale Adaptive Graph Convolution Network (MSA-GCN) is presented in this work through constructing dynamic temporal receptive fields and designing multiscale information aggregation to recognize emotions. In our model, a adaptive selective spatial-temporal graph convolution is designed to select the convolution kernel dynamically to obtain the soft spatio-temporal features of different emotions. Moreover, a Cross-Scale mapping Fusion Mechanism (CSFM) is designed to construct an adaptive adjacency matrix to enhance information interaction and reduce redundancy. Compared with previous state-of-the-art methods, the proposed method achieves the best performance on two public datasets, improving the mAP by 2\%. We also conduct extensive ablations studies to show the effectiveness of different components in our methods.
FedNoiL: A Simple Two-Level Sampling Method for Federated Learning with Noisy Labels
May 20, 2022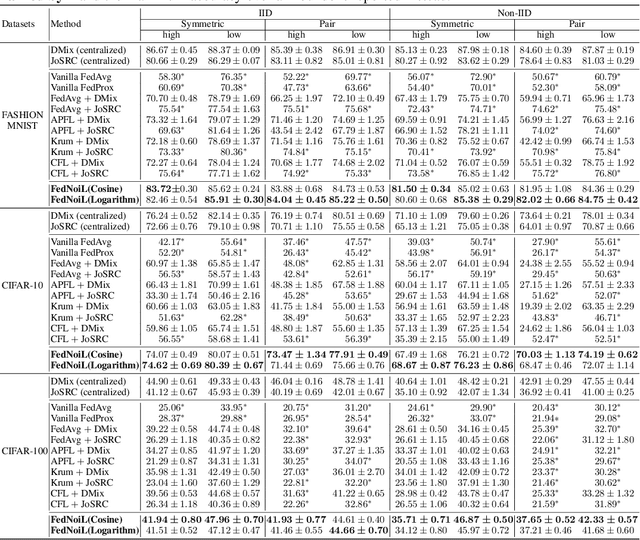
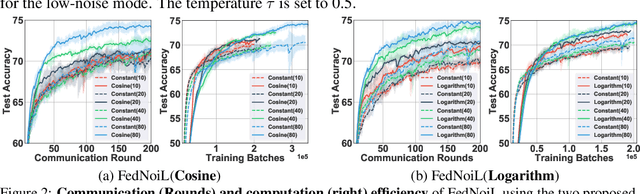
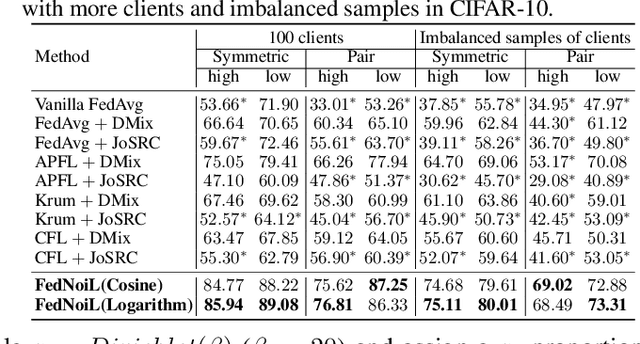
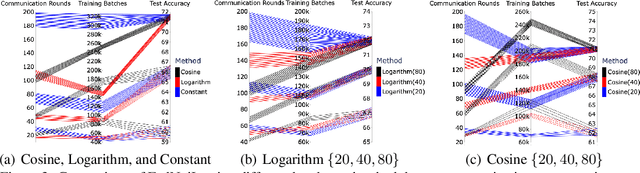
Federated learning (FL) aims at training a global model on the server side while the training data are collected and located at the local devices. Hence, the labels in practice are usually annotated by clients of varying expertise or criteria and thus contain different amounts of noises. Local training on noisy labels can easily result in overfitting to noisy labels, which is devastating to the global model through aggregation. Although recent robust FL methods take malicious clients into account, they have not addressed local noisy labels on each device and the impact to the global model. In this paper, we develop a simple two-level sampling method "FedNoiL" that (1) selects clients for more robust global aggregation on the server; and (2) selects clean labels and correct pseudo-labels at the client end for more robust local training. The sampling probabilities are built upon clean label detection by the global model. Moreover, we investigate different schedules changing the local epochs between aggregations over the course of FL, which notably improves the communication and computation efficiency in noisy label setting. In experiments with homogeneous/heterogeneous data distributions and noise ratios, we observed that direct combinations of SOTA FL methods with SOTA noisy-label learning methods can easily fail but our method consistently achieves better and robust performance.
SemiNLL: A Framework of Noisy-Label Learning by Semi-Supervised Learning
Dec 02, 2020


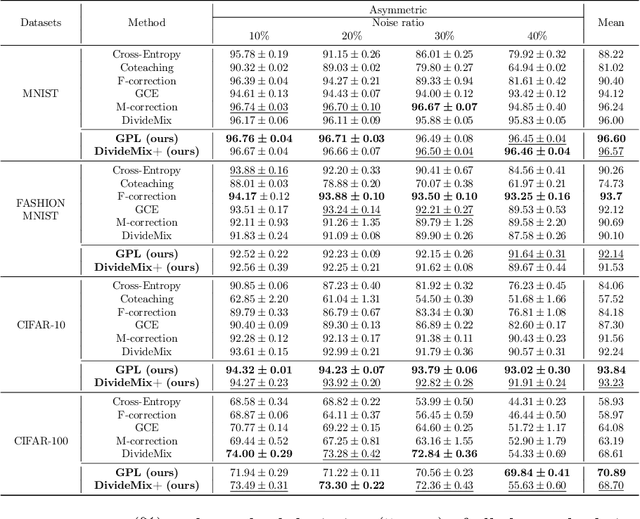
Deep learning with noisy labels is a challenging task. Recent prominent methods that build on a specific sample selection (SS) strategy and a specific semi-supervised learning (SSL) model achieved state-of-the-art performance. Intuitively, better performance could be achieved if stronger SS strategies and SSL models are employed. Following this intuition, one might easily derive various effective noisy-label learning methods using different combinations of SS strategies and SSL models, which is, however, reinventing the wheel in essence. To prevent this problem, we propose SemiNLL, a versatile framework that combines SS strategies and SSL models in an end-to-end manner. Our framework can absorb various SS strategies and SSL backbones, utilizing their power to achieve promising performance. We also instantiate our framework with different combinations, which set the new state of the art on benchmark-simulated and real-world datasets with noisy labels.
Confusable Learning for Large-class Few-Shot Classification
Nov 06, 2020
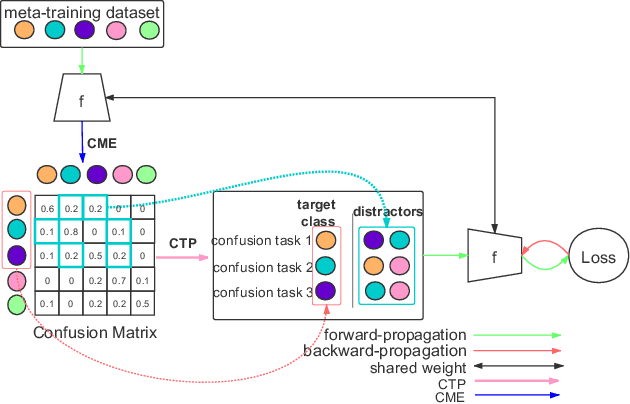


Few-shot image classification is challenging due to the lack of ample samples in each class. Such a challenge becomes even tougher when the number of classes is very large, i.e., the large-class few-shot scenario. In this novel scenario, existing approaches do not perform well because they ignore confusable classes, namely similar classes that are difficult to distinguish from each other. These classes carry more information. In this paper, we propose a biased learning paradigm called Confusable Learning, which focuses more on confusable classes. Our method can be applied to mainstream meta-learning algorithms. Specifically, our method maintains a dynamically updating confusion matrix, which analyzes confusable classes in the dataset. Such a confusion matrix helps meta learners to emphasize on confusable classes. Comprehensive experiments on Omniglot, Fungi, and ImageNet demonstrate the efficacy of our method over state-of-the-art baselines.
Self-attention-based BiGRU and capsule network for named entity recognition
Jan 30, 2020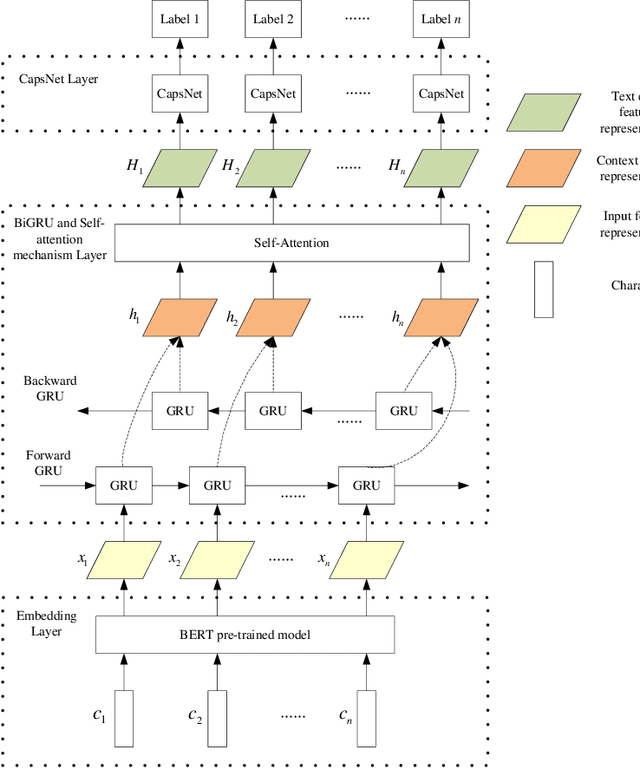
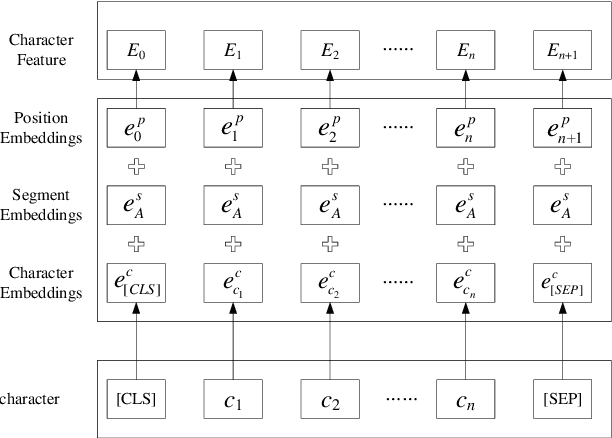
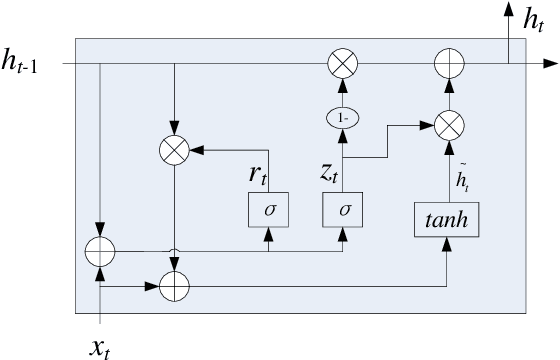
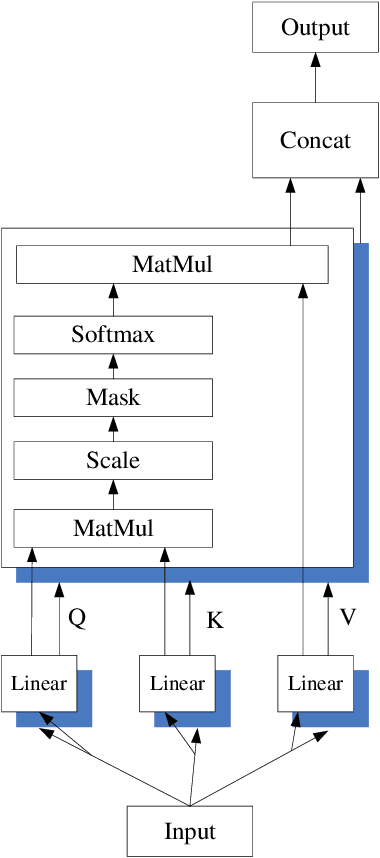
Named entity recognition(NER) is one of the tasks of natural language processing(NLP). In view of the problem that the traditional character representation ability is weak and the neural network method is unable to capture the important sequence information. An self-attention-based bidirectional gated recurrent unit(BiGRU) and capsule network(CapsNet) for NER is proposed. This model generates character vectors through bidirectional encoder representation of transformers(BERT) pre-trained model. BiGRU is used to capture sequence context features, and self-attention mechanism is proposed to give different focus on the information captured by hidden layer of BiGRU. Finally, we propose to use CapsNet for entity recognition. We evaluated the recognition performance of the model on two datasets. Experimental results show that the model has better performance without relying on external dictionary information.