 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextDoctor: Unified Document Image Inpainting via Patch Pyramid Diffusion Models
Mar 06, 2025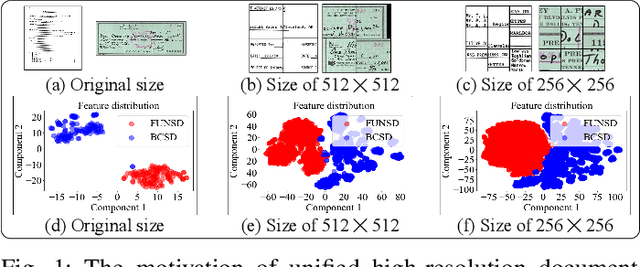

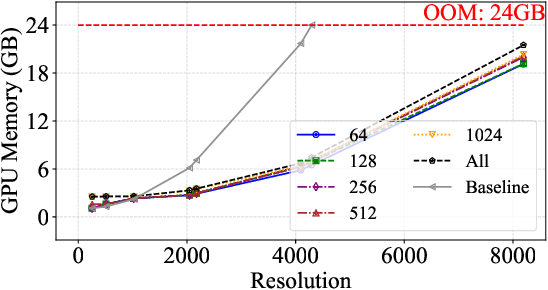
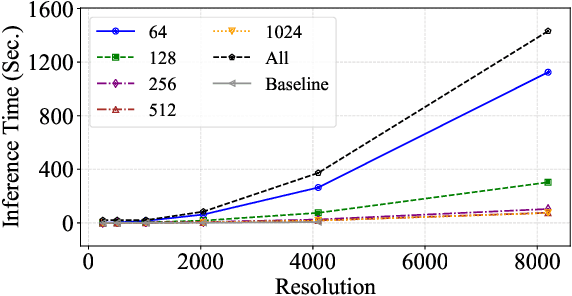
Digital versions of real-world text documents often suffer from issues like environmental corrosion of the original document, low-quality scanning, or human interference. Existing document restoration and inpainting methods typically struggle with generalizing to unseen document styles and handling high-resolution images. To address these challenges, we introduce TextDoctor, a novel unified document image inpainting method. Inspired by human reading behavior, TextDoctor restores fundamental text elements from patches and then applies diffusion models to entire document images instead of training models on specific document types. To handle varying text sizes and avoid out-of-memory issues, common in high-resolution documents, we propose using structure pyramid prediction and patch pyramid diffusion models. These techniques leverage multiscale inputs and pyramid patches to enhance the quality of inpainting both globally and locally. Extensive qualitative and quantitative experiments on seven public datasets validated that TextDoctor outperforms state-of-the-art methods in restoring various types of high-resolution document images.
Synthetic Demographic Data Generation for Card Fraud Detection Using GANs
Jun 29, 2023Using machine learning models to generate synthetic data has become common in many fields. Technology to generate synthetic transactions that can be used to detect fraud is also growing fast. Generally, this synthetic data contains only information about the transaction, such as the time, place, and amount of money. It does not usually contain the individual user's characteristics (age and gender are occasionally included). Using relatively complex synthetic demographic data may improve the complexity of transaction data features, thus improving the fraud detection performance. Benefiting from developments of machine learning, some deep learning models have potential to perform better than other well-established synthetic data generation methods, such as microsimulation. In this study, we built a deep-learning Generative Adversarial Network (GAN), called DGGAN, which will be used for demographic data generation. Our model generates samples during model training, which we found important to overcame class imbalance issues. This study can help improve the cognition of synthetic data and further explore the application of synthetic data generation in card fraud detection.