 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Defense Against Poisoning Attacks on Federated Learning: LayerCAM Augmented with Autoencoder
Paper and Code
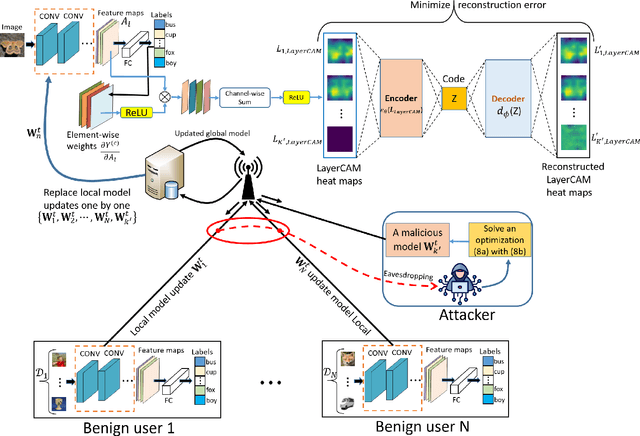

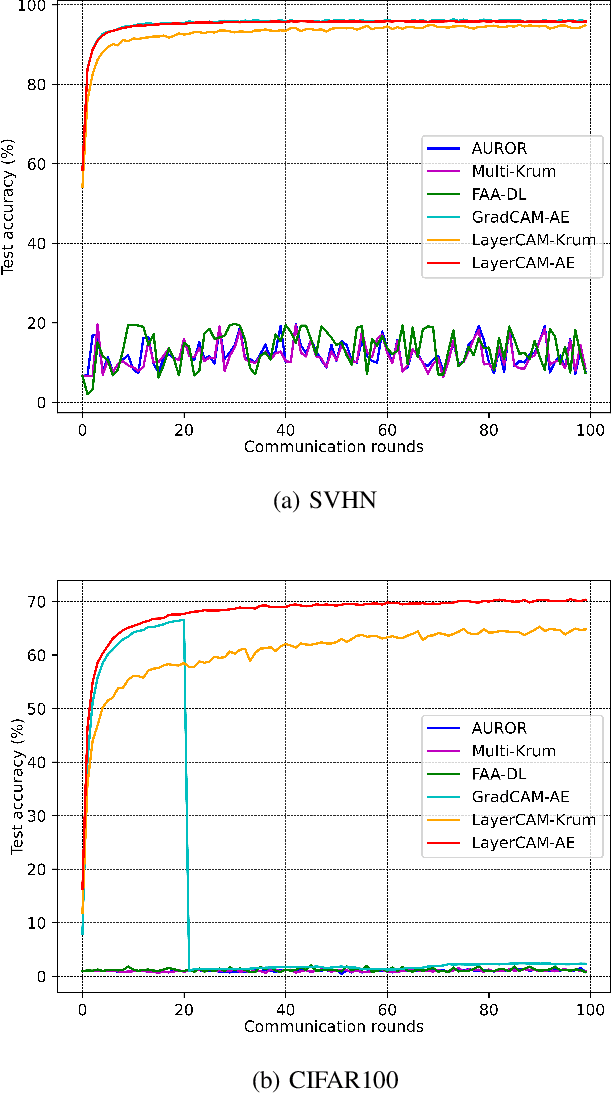
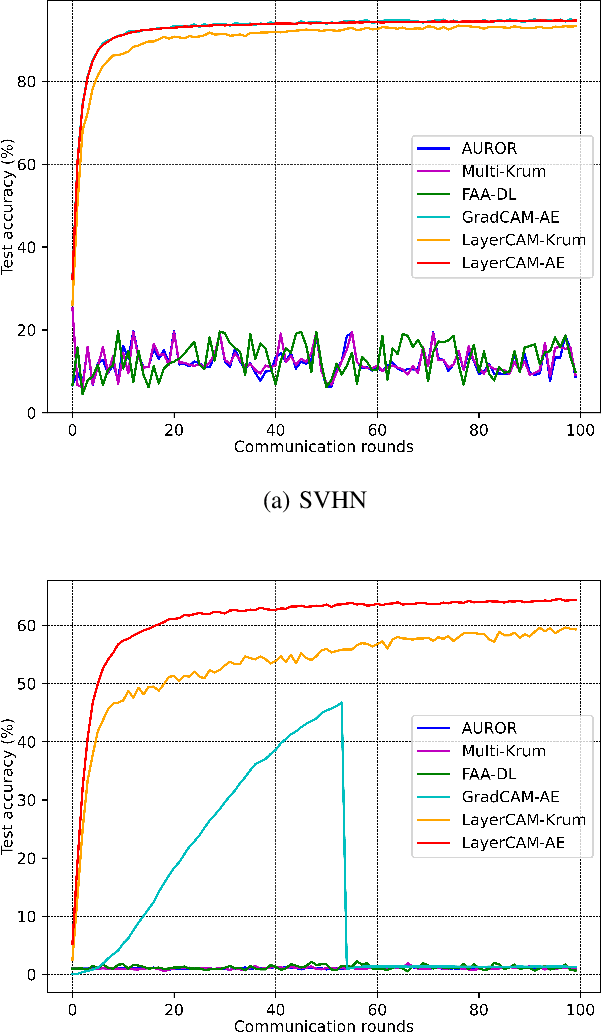
Recent attacks on federated learning (FL) can introduce malicious model updates that circumvent widely adopted Euclidean distance-based detection methods. This paper proposes a novel defense strategy, referred to as LayerCAM-AE, designed to counteract model poisoning in federated learning. The LayerCAM-AE puts forth a new Layer Class Activation Mapping (LayerCAM) integrated with an autoencoder (AE), significantly enhancing detection capabilities. Specifically, LayerCAM-AE generates a heat map for each local model update, which is then transformed into a more compact visual format. The autoencoder is designed to process the LayerCAM heat maps from the local model updates, improving their distinctiveness and thereby increasing the accuracy in spotting anomalous maps and malicious local models. To address the risk of misclassifications with LayerCAM-AE, a voting algorithm is developed, where a local model update is flagged as malicious if its heat maps are consistently suspicious over several rounds of communication. Extensive tests of LayerCAM-AE on the SVHN and CIFAR-100 datasets are performed under both Independent and Identically Distributed (IID) and non-IID settings in comparison with existing ResNet-50 and REGNETY-800MF defense models. Experimental results show that LayerCAM-AE increases detection rates (Recall: 1.0, Precision: 1.0, FPR: 0.0, Accuracy: 1.0, F1 score: 1.0, AUC: 1.0) and test accuracy in FL, surpassing the performance of both the ResNet-50 and REGNETY-800MF. Our code is available at: https://github.com/jjzgeeks/LayerCAM-AE