 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Stereo Feature Descriptor for Visual Odometry
Sep 23, 2018



In this paper, we propose a simple way to utilize stereo camera data to improve feature descriptors. Computer vision algorithms that use a stereo camera require some calculations of 3D information. We leverage this pre-calculated information to improve feature descriptor algorithms. We use the 3D feature information to estimate the scale of each feature. This way, each feature descriptor will be more robust to scale change without significant computations. In addition, we use stereo images to construct the descriptor vector. The Scale-Invariant Feature Transform (SIFT) and Fast Retina Keypoint (FREAK) descriptors are used to evaluate the proposed method. The scale normalization technique in feature tracking test improves the standard SIFT by 8.75% and improves the standard FREAK by 28.65%. Using the proposed stereo feature descriptor, a visual odometry algorithm is designed and tested on the KITTI dataset. The stereo FREAK descriptor raises the number of inlier matches by 19% and consequently improves the accuracy of visual odometry by 23%.
Novel Adaptive Genetic Algorithm Sample Consensus
Nov 26, 2017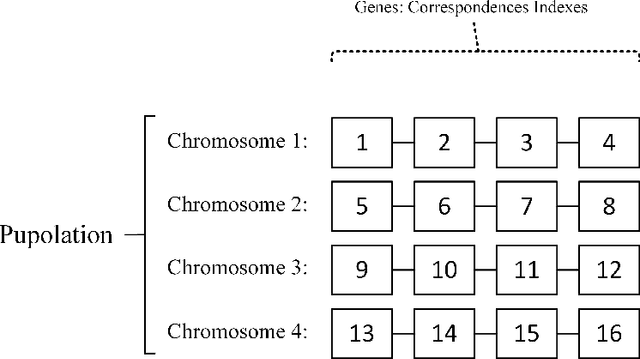

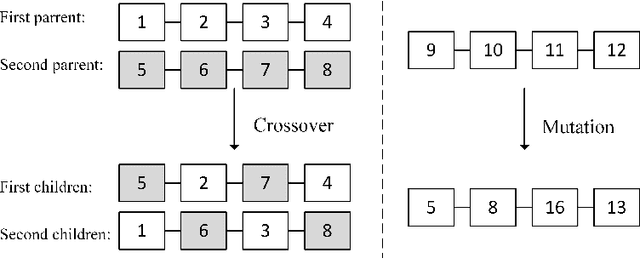
Random sample consensus (RANSAC) is a successful algorithm in model fitting applications. It is vital to have strong exploration phase when there are an enormous amount of outliers within the dataset. Achieving a proper model is guaranteed by pure exploration strategy of RANSAC. However, finding the optimum result requires exploitation. GASAC is an evolutionary paradigm to add exploitation capability to the algorithm. Although GASAC improves the results of RANSAC, it has a fixed strategy for balancing between exploration and exploitation. In this paper, a new paradigm is proposed based on genetic algorithm with an adaptive strategy. We utilize an adaptive genetic operator to select high fitness individuals as parents and mutate low fitness ones. In the mutation phase, a training method is used to gradually learn which gene is the best replacement for the mutated gene. The proposed method adaptively balance between exploration and exploitation by learning about genes. During the final Iterations, the algorithm draws on this information to improve the final results. The proposed method is extensively evaluated on two set of experiments. In all tests, our method outperformed the other methods in terms of both the number of inliers found and the speed of the algorithm.