 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPAS: Efficient Training with Progressive Activation Sharing
Jan 27, 2026We present a novel method for Efficient training with Progressive Activation Sharing (EPAS). This method bridges progressive training paradigm with the phenomenon of redundant QK (or KV ) activations across deeper layers of transformers. EPAS gradually grows a sharing region during training by switching decoder layers to activation sharing mode. This results in throughput increase due to reduced compute. To utilize deeper layer redundancy, the sharing region starts from the deep end of the model and grows towards the shallow end. The EPAS trained models allow for variable region lengths of activation sharing for different compute budgets during inference. Empirical evaluations with QK activation sharing in LLaMA models ranging from 125M to 7B parameters show up to an 11.1% improvement in training throughput and up to a 29% improvement in inference throughput while maintaining similar loss curve to the baseline models. Furthermore, applying EPAS in continual pretraining to transform TinyLLaMA into an attention-sharing model yields up to a 10% improvement in average accuracy over state-of-the-art methods, emphasizing the significance of progressive training in cross layer activation sharing models.
LoRA-Drop: Temporal LoRA Decoding for Efficient LLM Inference
Jan 05, 2026Autoregressive large language models (LLMs) are bottlenecked by sequential decoding, where each new token typically requires executing all transformer layers. Existing dynamic-depth and layer-skipping methods reduce this cost, but often rely on auxiliary routing mechanisms or incur accuracy degradation when bypassed layers are left uncompensated. We present \textbf{LoRA-Drop}, a plug-and-play inference framework that accelerates decoding by applying a \emph{temporal compute schedule} to a fixed subset of intermediate layers: on most decoding steps, selected layers reuse the previous-token hidden state and apply a low-rank LoRA correction, while periodic \emph{refresh} steps execute the full model to prevent drift. LoRA-Drop requires no routing network, is compatible with standard KV caching, and can reduce KV-cache footprint by skipping KV updates in droppable layers during LoRA steps and refreshing periodically. Across \textbf{LLaMA2-7B}, \textbf{LLaMA3-8B}, \textbf{Qwen2.5-7B}, and \textbf{Qwen2.5-14B}, LoRA-Drop achieves up to \textbf{2.6$\times$ faster decoding} and \textbf{45--55\% KV-cache reduction} while staying within \textbf{0.5 percentage points (pp)} of baseline accuracy. Evaluations on reasoning (GSM8K, MATH, BBH), code generation (HumanEval, MBPP), and long-context/multilingual benchmarks (LongBench, XNLI, XCOPA) identify a consistent \emph{safe zone} of scheduling configurations that preserves quality while delivering substantial efficiency gains, providing a simple path toward adaptive-capacity inference in LLMs. Codes are available at https://github.com/hosseinbv/LoRA-Drop.git.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Jan 04, 2026Scaling training compute, measured in FLOPs, has long been shown to improve the accuracy of large language models, yet training remains resource-intensive. Prior work shows that increasing test-time compute (TTC)-for example through iterative sampling-can allow smaller models to rival or surpass much larger ones at lower overall cost. We introduce TTC-aware training, where an intermediate checkpoint and a corresponding TTC configuration can together match or exceed the accuracy of a fully trained model while requiring substantially fewer training FLOPs. Building on this insight, we propose an early stopping algorithm that jointly selects a checkpoint and TTC configuration to minimize training compute without sacrificing accuracy. To make this practical, we develop an efficient TTC evaluation method that avoids exhaustive search, and we formalize a break-even bound that identifies when increased inference compute compensates for reduced training compute. Experiments demonstrate up to 92\% reductions in training FLOPs while maintaining and sometimes remarkably improving accuracy. These results highlight a new perspective for balancing training and inference compute in model development, enabling faster deployment cycles and more frequent model refreshes. Codes will be publicly released.
Bayesian Mixture of Experts For Large Language Models
Nov 12, 2025We present Bayesian Mixture of Experts (Bayesian-MoE), a post-hoc uncertainty estimation framework for fine-tuned large language models (LLMs) based on Mixture-of-Experts architectures. Our method applies a structured Laplace approximation to the second linear layer of each expert, enabling calibrated uncertainty estimation without modifying the original training procedure or introducing new parameters. Unlike prior approaches, which apply Bayesian inference to added adapter modules, Bayesian-MoE directly targets the expert pathways already present in MoE models, leveraging their modular design for tractable block-wise posterior estimation. We use Kronecker-factored low-rank approximations to model curvature and derive scalable estimates of predictive uncertainty and marginal likelihood. Experiments on common-sense reasoning benchmarks with Qwen1.5-MoE and DeepSeek-MoE demonstrate that Bayesian-MoE improves both expected calibration error (ECE) and negative log-likelihood (NLL) over baselines, confirming its effectiveness for reliable downstream decision-making.
ECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
E2E-Swin-Unet++: An Enhanced End-to-End Swin-Unet Architecture With Dual Decoders For PTMC Segmentation
Oct 23, 2024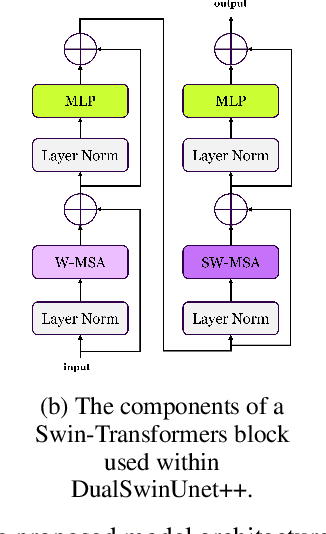
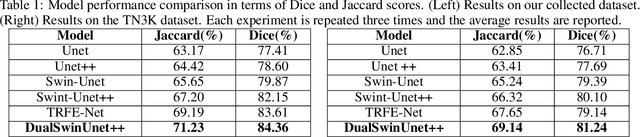
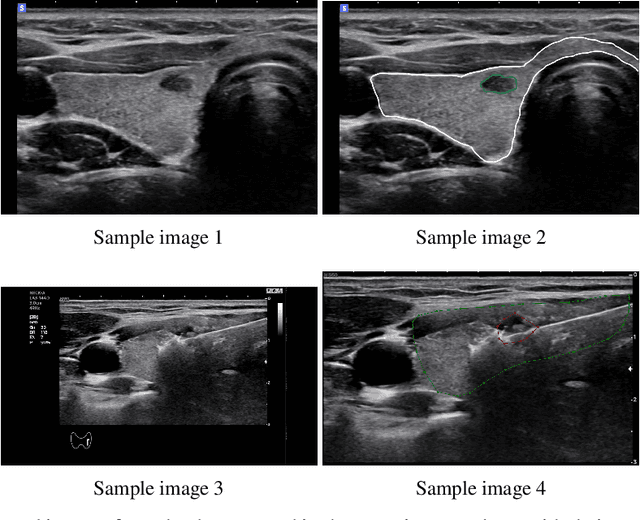
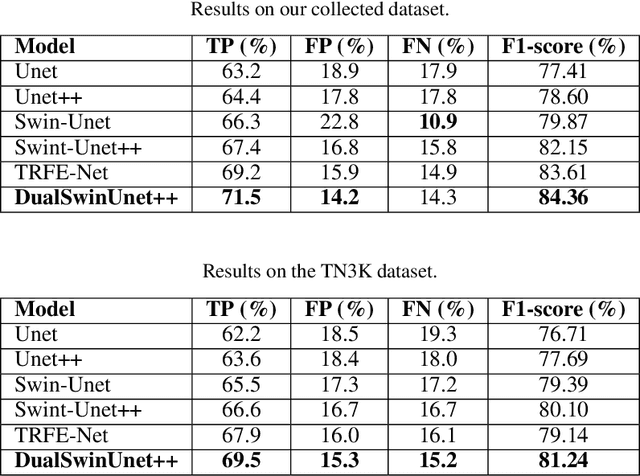
Efficiently managing papillary thyroid microcarcinoma (PTMC) while minimizing patient discomfort poses a significant clinical challenge. Radiofrequency ablation (RFA) offers a less invasive alternative to surgery and radiation therapy for PTMC treatment, characterized by shorter recovery times and reduced pain. As an image-guided procedure, RFA generates localized heat by delivering high-frequency electrical currents through electrodes to the targeted area under ultrasound imaging guidance. However, the precision and skill required by operators for accurate guidance using current ultrasound B-mode imaging technologies remain significant challenges. To address these challenges, we develop a novel AI segmentation model, E2E-Swin-Unet++. This model enhances ultrasound B-mode imaging by enabling real-time identification and segmentation of PTMC tumors and monitoring of the region of interest for precise targeting during treatment. E2E-Swin- Unet++ is an advanced end-to-end extension of the Swin-Unet architecture, incorporating thyroid region information to minimize the risk of false PTMC segmentation while providing fast inference capabilities. Experimental results on a real clinical RFA dataset demonstrate the superior performance of E2E-Swin-Unet++ compared to related models. Our proposed solution significantly improves the precision and control of RFA ablation treatment by enabling real-time identification and segmentation of PTMC margins during the procedure.
Screening COVID-19 Based on CT/CXR Images & Building a Publicly Available CT-scan Dataset of COVID-19
Dec 29, 2020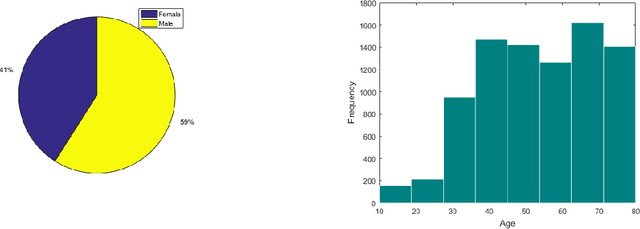
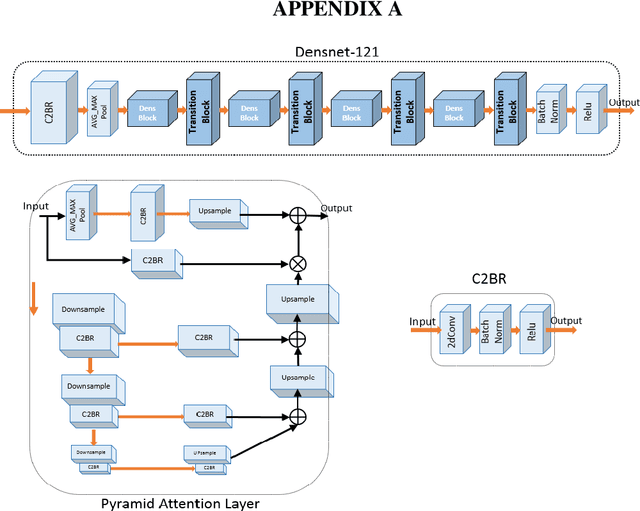
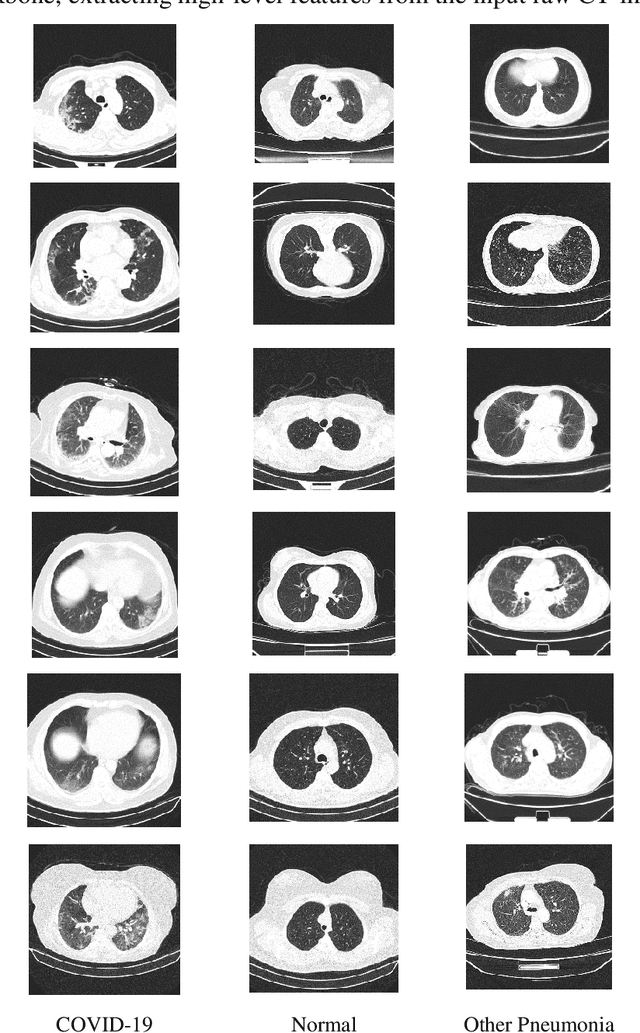
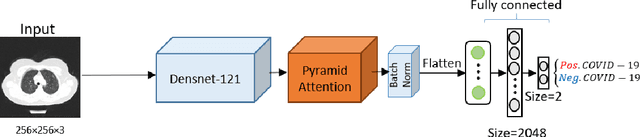
The rapid outbreak of COVID-19 threatens humans life all around the world. Due to insufficient diagnostic infrastructures, developing an accurate, efficient, inexpensive, and quick diagnostic tool is of great importance. As chest radiography, such as chest X-ray (CXR) and CT computed tomography (CT), is a possible way for screening COVID-19, developing an automatic image classification tool is immensely helpful for detecting the patients with COVID-19. To date, researchers have proposed several different screening methods; however, none of them could achieve a reliable and highly sensitive performance yet. The main drawbacks of current methods are the lack of having enough training data, low generalization performance, and a high rate of false-positive detection. To tackle such limitations, this study firstly builds a large-size publicly available CT-scan dataset, consisting of more than 13k CT-images of more than 1000 individuals, in which 8k images are taken from 500 patients infected with COVID-19. Secondly, we propose a deep learning model for screening COVID-19 using our proposed CT dataset and report the baseline results. Finally, we extend the proposed CT model for screening COVID-19 from CXR images using a transfer learning approach. The experimental results show that the proposed CT and CXR methods achieve the AUC scores of 0.886 and 0.984 respectively.
DL-Reg: A Deep Learning Regularization Technique using Linear Regression
Nov 03, 2020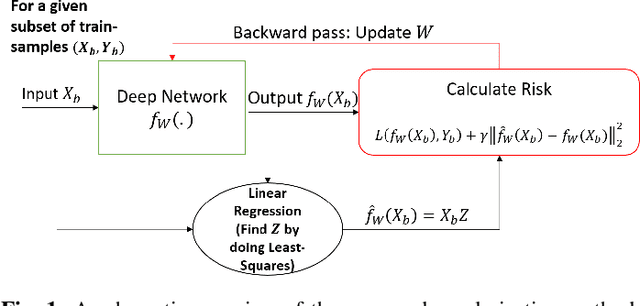
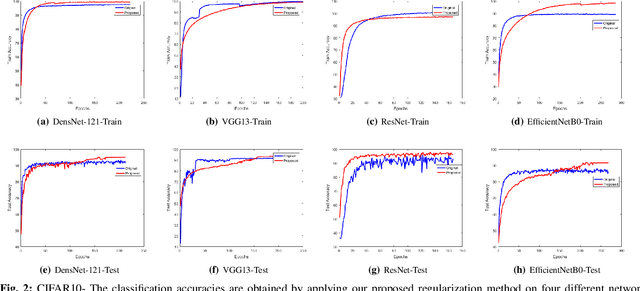
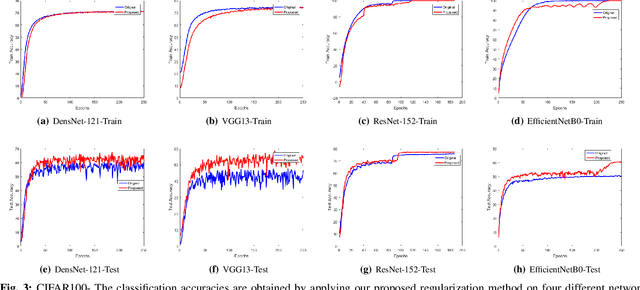
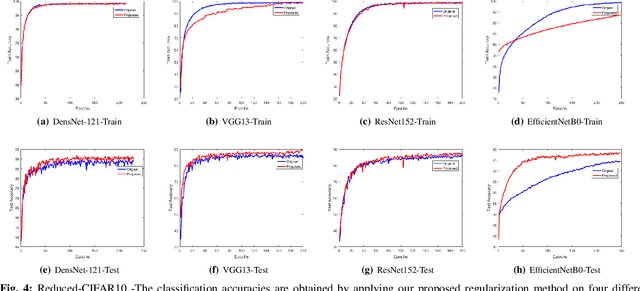
Regularization plays a vital role in the context of deep learning by preventing deep neural networks from the danger of overfitting. This paper proposes a novel deep learning regularization method named as DL-Reg, which carefully reduces the nonlinearity of deep networks to a certain extent by explicitly enforcing the network to behave as much linear as possible. The key idea is to add a linear constraint to the objective function of the deep neural networks, which is simply the error of a linear mapping from the inputs to the outputs of the model. More precisely, the proposed DL-Reg carefully forces the network to behave in a linear manner. This linear constraint, which is further adjusted by a regularization factor, prevents the network from the risk of overfitting. The performance of DL-Reg is evaluated by training state-of-the-art deep network models on several benchmark datasets. The experimental results show that the proposed regularization method: 1) gives major improvements over the existing regularization techniques, and 2) significantly improves the performance of deep neural networks, especially in the case of small-sized training datasets.