 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuel Gauge: Estimating Chain-of-Thought Length Ahead of Time in Large Multimodal Models
Mar 11, 2026Reasoning Large Multi-modality Models (LMMs) have become the de facto choice for many applications. However, these models rely on a Chain-of-Thought (CoT) process that is lengthy and unpredictable at runtime, often resulting in inefficient use of computational resources (due to memory fragmentation) and sub-optimal accuracy (due to under- and over-thinking). We observe empirically that the CoT process follows a very simple form, whose behavior is independent of the specific generated samples. This suggests that the CoT length can be estimated ahead of time based on a hidden parameter representing the amount of "fuel" available to support the reasoning process. Based on this insight, we propose Fuel Gauge, the first method which extracts this hidden signal and predicts CoT length ahead of time. We demonstrate the utility on the Fuel Gauge on two downstream tasks: predictive KV cache allocation, which addresses memory fragmentation in LMM serving systems, and CoT length modulation, which mitigates under-thinking and over-thinking. Extensive experiments on LMMs across text-only, image-text, and video-text question answering benchmarks demonstrate the effectiveness, generalizability, and practical value of our Fuel Gauge. For example, on the GPQA-Diamond benchmark, our Fuel Gauge achieves less than half the CoT length prediction error compared to the baseline; this translates into a 13.37x reduction in the memory allocation frequency.
PipeFlow: Pipelined Processing and Motion-Aware Frame Selection for Long-Form Video Editing
Dec 30, 2025Long-form video editing poses unique challenges due to the exponential increase in the computational cost from joint editing and Denoising Diffusion Implicit Models (DDIM) inversion across extended sequences. To address these limitations, we propose PipeFlow, a scalable, pipelined video editing method that introduces three key innovations: First, based on a motion analysis using Structural Similarity Index Measure (SSIM) and Optical Flow, we identify and propose to skip editing of frames with low motion. Second, we propose a pipelined task scheduling algorithm that splits a video into multiple segments and performs DDIM inversion and joint editing in parallel based on available GPU memory. Lastly, we leverage a neural network-based interpolation technique to smooth out the border frames between segments and interpolate the previously skipped frames. Our method uniquely scales to longer videos by dividing them into smaller segments, allowing PipeFlow's editing time to increase linearly with video length. In principle, this enables editing of infinitely long videos without the growing per-frame computational overhead encountered by other methods. PipeFlow achieves up to a 9.6X speedup compared to TokenFlow and a 31.7X speedup over Diffusion Motion Transfer (DMT).
AdaptViG: Adaptive Vision GNN with Exponential Decay Gating
Nov 13, 2025



Vision Graph Neural Networks (ViGs) offer a new direction for advancements in vision architectures. While powerful, ViGs often face substantial computational challenges stemming from their graph construction phase, which can hinder their efficiency. To address this issue we propose AdaptViG, an efficient and powerful hybrid Vision GNN that introduces a novel graph construction mechanism called Adaptive Graph Convolution. This mechanism builds upon a highly efficient static axial scaffold and a dynamic, content-aware gating strategy called Exponential Decay Gating. This gating mechanism selectively weighs long-range connections based on feature similarity. Furthermore, AdaptViG employs a hybrid strategy, utilizing our efficient gating mechanism in the early stages and a full Global Attention block in the final stage for maximum feature aggregation. Our method achieves a new state-of-the-art trade-off between accuracy and efficiency among Vision GNNs. For instance, our AdaptViG-M achieves 82.6% top-1 accuracy, outperforming ViG-B by 0.3% while using 80% fewer parameters and 84% fewer GMACs. On downstream tasks, AdaptViG-M obtains 45.8 mIoU, 44.8 APbox, and 41.1 APmask, surpassing the much larger EfficientFormer-L7 by 0.7 mIoU, 2.2 APbox, and 2.1 APmask, respectively, with 78% fewer parameters.
VCMamba: Bridging Convolutions with Multi-Directional Mamba for Efficient Visual Representation
Sep 04, 2025Recent advances in Vision Transformers (ViTs) and State Space Models (SSMs) have challenged the dominance of Convolutional Neural Networks (CNNs) in computer vision. ViTs excel at capturing global context, and SSMs like Mamba offer linear complexity for long sequences, yet they do not capture fine-grained local features as effectively as CNNs. Conversely, CNNs possess strong inductive biases for local features but lack the global reasoning capabilities of transformers and Mamba. To bridge this gap, we introduce \textit{VCMamba}, a novel vision backbone that integrates the strengths of CNNs and multi-directional Mamba SSMs. VCMamba employs a convolutional stem and a hierarchical structure with convolutional blocks in its early stages to extract rich local features. These convolutional blocks are then processed by later stages incorporating multi-directional Mamba blocks designed to efficiently model long-range dependencies and global context. This hybrid design allows for superior feature representation while maintaining linear complexity with respect to image resolution. We demonstrate VCMamba's effectiveness through extensive experiments on ImageNet-1K classification and ADE20K semantic segmentation. Our VCMamba-B achieves 82.6% top-1 accuracy on ImageNet-1K, surpassing PlainMamba-L3 by 0.3% with 37% fewer parameters, and outperforming Vision GNN-B by 0.3% with 64% fewer parameters. Furthermore, VCMamba-B obtains 47.1 mIoU on ADE20K, exceeding EfficientFormer-L7 by 2.0 mIoU while utilizing 62% fewer parameters. Code is available at https://github.com/Wertyuui345/VCMamba.
RapidNet: Multi-Level Dilated Convolution Based Mobile Backbone
Dec 14, 2024Vision transformers (ViTs) have dominated computer vision in recent years. However, ViTs are computationally expensive and not well suited for mobile devices; this led to the prevalence of convolutional neural network (CNN) and ViT-based hybrid models for mobile vision applications. Recently, Vision GNN (ViG) and CNN hybrid models have also been proposed for mobile vision tasks. However, all of these methods remain slower compared to pure CNN-based models. In this work, we propose Multi-Level Dilated Convolutions to devise a purely CNN-based mobile backbone. Using Multi-Level Dilated Convolutions allows for a larger theoretical receptive field than standard convolutions. Different levels of dilation also allow for interactions between the short-range and long-range features in an image. Experiments show that our proposed model outperforms state-of-the-art (SOTA) mobile CNN, ViT, ViG, and hybrid architectures in terms of accuracy and/or speed on image classification, object detection, instance segmentation, and semantic segmentation. Our fastest model, RapidNet-Ti, achieves 76.3\% top-1 accuracy on ImageNet-1K with 0.9 ms inference latency on an iPhone 13 mini NPU, which is faster and more accurate than MobileNetV2x1.4 (74.7\% top-1 with 1.0 ms latency). Our work shows that pure CNN architectures can beat SOTA hybrid and ViT models in terms of accuracy and speed when designed properly.
CrediRAG: Network-Augmented Credibility-Based Retrieval for Misinformation Detection in Reddit
Oct 15, 2024



Fake news threatens democracy and exacerbates the polarization and divisions in society; therefore, accurately detecting online misinformation is the foundation of addressing this issue. We present CrediRAG, the first fake news detection model that combines language models with access to a rich external political knowledge base with a dense social network to detect fake news across social media at scale. CrediRAG uses a news retriever to initially assign a misinformation score to each post based on the source credibility of similar news articles to the post title content. CrediRAG then improves the initial retrieval estimations through a novel weighted post-to-post network connected based on shared commenters and weighted by the average stance of all shared commenters across every pair of posts. We achieve 11% increase in the F1-score in detecting misinformative posts over state-of-the-art methods. Extensive experiments conducted on curated real-world Reddit data of over 200,000 posts demonstrate the superior performance of CrediRAG on existing baselines. Thus, our approach offers a more accurate and scalable solution to combat the spread of fake news across social media platforms.
Scaling Graph Convolutions for Mobile Vision
Jun 09, 2024



To compete with existing mobile architectures, MobileViG introduces Sparse Vision Graph Attention (SVGA), a fast token-mixing operator based on the principles of GNNs. However, MobileViG scales poorly with model size, falling at most 1% behind models with similar latency. This paper introduces Mobile Graph Convolution (MGC), a new vision graph neural network (ViG) module that solves this scaling problem. Our proposed mobile vision architecture, MobileViGv2, uses MGC to demonstrate the effectiveness of our approach. MGC improves on SVGA by increasing graph sparsity and introducing conditional positional encodings to the graph operation. Our smallest model, MobileViGv2-Ti, achieves a 77.7% top-1 accuracy on ImageNet-1K, 2% higher than MobileViG-Ti, with 0.9 ms inference latency on the iPhone 13 Mini NPU. Our largest model, MobileViGv2-B, achieves an 83.4% top-1 accuracy, 0.8% higher than MobileViG-B, with 2.7 ms inference latency. Besides image classification, we show that MobileViGv2 generalizes well to other tasks. For object detection and instance segmentation on MS COCO 2017, MobileViGv2-M outperforms MobileViG-M by 1.2 $AP^{box}$ and 0.7 $AP^{mask}$, and MobileViGv2-B outperforms MobileViG-B by 1.0 $AP^{box}$ and 0.7 $AP^{mask}$. For semantic segmentation on ADE20K, MobileViGv2-M achieves 42.9% $mIoU$ and MobileViGv2-B achieves 44.3% $mIoU$. Our code can be found at \url{https://github.com/SLDGroup/MobileViGv2}.
Ada-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
Jun 07, 2024
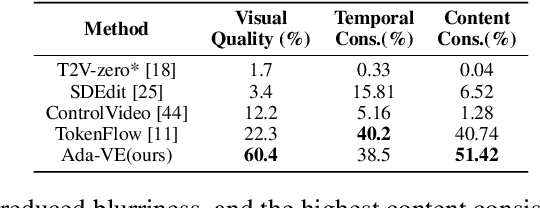
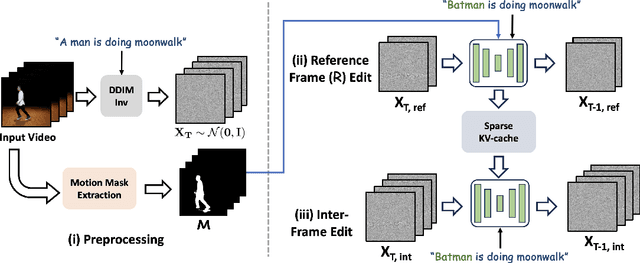

Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.
PP-SAM: Perturbed Prompts for Robust Adaptation of Segment Anything Model for Polyp Segmentation
May 27, 2024The Segment Anything Model (SAM), originally designed for general-purpose segmentation tasks, has been used recently for polyp segmentation. Nonetheless, fine-tuning SAM with data from new imaging centers or clinics poses significant challenges. This is because this necessitates the creation of an expensive and time-intensive annotated dataset, along with the potential for variability in user prompts during inference. To address these issues, we propose a robust fine-tuning technique, PP-SAM, that allows SAM to adapt to the polyp segmentation task with limited images. To this end, we utilize variable perturbed bounding box prompts (BBP) to enrich the learning context and enhance the model's robustness to BBP perturbations during inference. Rigorous experiments on polyp segmentation benchmarks reveal that our variable BBP perturbation significantly improves model resilience. Notably, on Kvasir, 1-shot fine-tuning boosts the DICE score by 20% and 37% with 50 and 100-pixel BBP perturbations during inference, respectively. Moreover, our experiments show that 1-shot, 5-shot, and 10-shot PP-SAM with 50-pixel perturbations during inference outperform a recent state-of-the-art (SOTA) polyp segmentation method by 26%, 7%, and 5% DICE scores, respectively. Our results motivate the broader applicability of our PP-SAM for other medical imaging tasks with limited samples. Our implementation is available at https://github.com/SLDGroup/PP-SAM.
EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation
May 11, 2024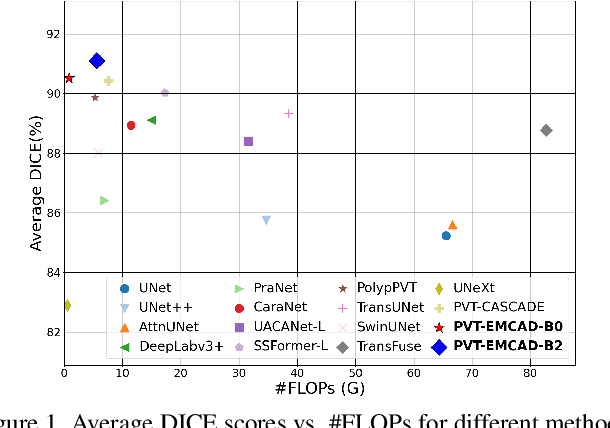
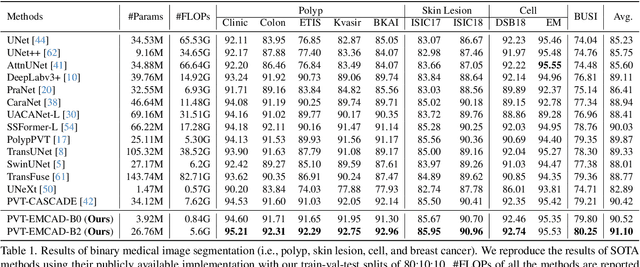
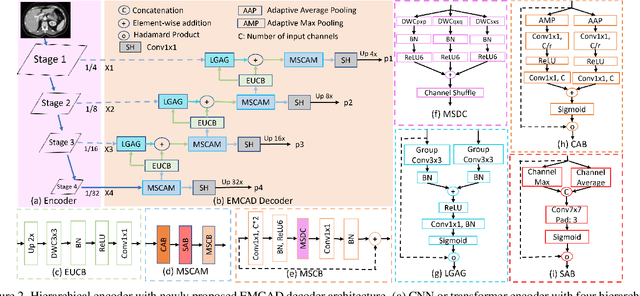
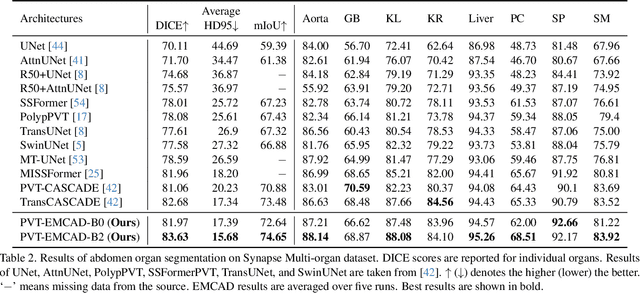
An efficient and effective decoding mechanism is crucial in medical image segmentation, especially in scenarios with limited computational resources. However, these decoding mechanisms usually come with high computational costs. To address this concern, we introduce EMCAD, a new efficient multi-scale convolutional attention decoder, designed to optimize both performance and computational efficiency. EMCAD leverages a unique multi-scale depth-wise convolution block, significantly enhancing feature maps through multi-scale convolutions. EMCAD also employs channel, spatial, and grouped (large-kernel) gated attention mechanisms, which are highly effective at capturing intricate spatial relationships while focusing on salient regions. By employing group and depth-wise convolution, EMCAD is very efficient and scales well (e.g., only 1.91M parameters and 0.381G FLOPs are needed when using a standard encoder). Our rigorous evaluations across 12 datasets that belong to six medical image segmentation tasks reveal that EMCAD achieves state-of-the-art (SOTA) performance with 79.4% and 80.3% reduction in #Params and #FLOPs, respectively. Moreover, EMCAD's adaptability to different encoders and versatility across segmentation tasks further establish EMCAD as a promising tool, advancing the field towards more efficient and accurate medical image analysis. Our implementation is available at https://github.com/SLDGroup/EMCAD.