 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Graph Convolutions for Mobile Vision
Jun 09, 2024



To compete with existing mobile architectures, MobileViG introduces Sparse Vision Graph Attention (SVGA), a fast token-mixing operator based on the principles of GNNs. However, MobileViG scales poorly with model size, falling at most 1% behind models with similar latency. This paper introduces Mobile Graph Convolution (MGC), a new vision graph neural network (ViG) module that solves this scaling problem. Our proposed mobile vision architecture, MobileViGv2, uses MGC to demonstrate the effectiveness of our approach. MGC improves on SVGA by increasing graph sparsity and introducing conditional positional encodings to the graph operation. Our smallest model, MobileViGv2-Ti, achieves a 77.7% top-1 accuracy on ImageNet-1K, 2% higher than MobileViG-Ti, with 0.9 ms inference latency on the iPhone 13 Mini NPU. Our largest model, MobileViGv2-B, achieves an 83.4% top-1 accuracy, 0.8% higher than MobileViG-B, with 2.7 ms inference latency. Besides image classification, we show that MobileViGv2 generalizes well to other tasks. For object detection and instance segmentation on MS COCO 2017, MobileViGv2-M outperforms MobileViG-M by 1.2 $AP^{box}$ and 0.7 $AP^{mask}$, and MobileViGv2-B outperforms MobileViG-B by 1.0 $AP^{box}$ and 0.7 $AP^{mask}$. For semantic segmentation on ADE20K, MobileViGv2-M achieves 42.9% $mIoU$ and MobileViGv2-B achieves 44.3% $mIoU$. Our code can be found at \url{https://github.com/SLDGroup/MobileViGv2}.
GreedyViG: Dynamic Axial Graph Construction for Efficient Vision GNNs
May 10, 2024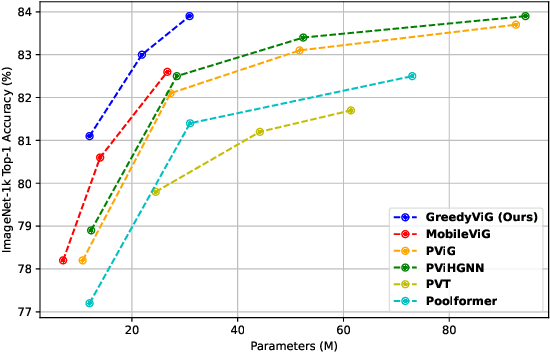
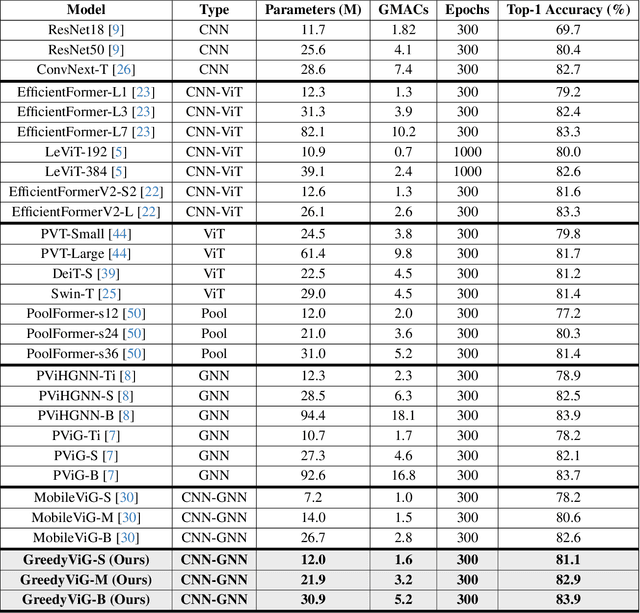

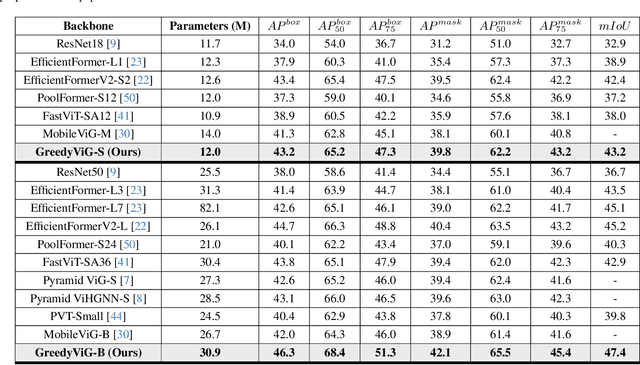
Vision graph neural networks (ViG) offer a new avenue for exploration in computer vision. A major bottleneck in ViGs is the inefficient k-nearest neighbor (KNN) operation used for graph construction. To solve this issue, we propose a new method for designing ViGs, Dynamic Axial Graph Construction (DAGC), which is more efficient than KNN as it limits the number of considered graph connections made within an image. Additionally, we propose a novel CNN-GNN architecture, GreedyViG, which uses DAGC. Extensive experiments show that GreedyViG beats existing ViG, CNN, and ViT architectures in terms of accuracy, GMACs, and parameters on image classification, object detection, instance segmentation, and semantic segmentation tasks. Our smallest model, GreedyViG-S, achieves 81.1% top-1 accuracy on ImageNet-1K, 2.9% higher than Vision GNN and 2.2% higher than Vision HyperGraph Neural Network (ViHGNN), with less GMACs and a similar number of parameters. Our largest model, GreedyViG-B obtains 83.9% top-1 accuracy, 0.2% higher than Vision GNN, with a 66.6% decrease in parameters and a 69% decrease in GMACs. GreedyViG-B also obtains the same accuracy as ViHGNN with a 67.3% decrease in parameters and a 71.3% decrease in GMACs. Our work shows that hybrid CNN-GNN architectures not only provide a new avenue for designing efficient models, but that they can also exceed the performance of current state-of-the-art models.
MobileViG: Graph-Based Sparse Attention for Mobile Vision Applications
Jul 01, 2023



Traditionally, convolutional neural networks (CNN) and vision transformers (ViT) have dominated computer vision. However, recently proposed vision graph neural networks (ViG) provide a new avenue for exploration. Unfortunately, for mobile applications, ViGs are computationally expensive due to the overhead of representing images as graph structures. In this work, we propose a new graph-based sparse attention mechanism, Sparse Vision Graph Attention (SVGA), that is designed for ViGs running on mobile devices. Additionally, we propose the first hybrid CNN-GNN architecture for vision tasks on mobile devices, MobileViG, which uses SVGA. Extensive experiments show that MobileViG beats existing ViG models and existing mobile CNN and ViT architectures in terms of accuracy and/or speed on image classification, object detection, and instance segmentation tasks. Our fastest model, MobileViG-Ti, achieves 75.7% top-1 accuracy on ImageNet-1K with 0.78 ms inference latency on iPhone 13 Mini NPU (compiled with CoreML), which is faster than MobileNetV2x1.4 (1.02 ms, 74.7% top-1) and MobileNetV2x1.0 (0.81 ms, 71.8% top-1). Our largest model, MobileViG-B obtains 82.6% top-1 accuracy with only 2.30 ms latency, which is faster and more accurate than the similarly sized EfficientFormer-L3 model (2.77 ms, 82.4%). Our work proves that well designed hybrid CNN-GNN architectures can be a new avenue of exploration for designing models that are extremely fast and accurate on mobile devices. Our code is publicly available at https://github.com/SLDGroup/MobileViG.