 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
Paper and Code
Jun 07, 2024
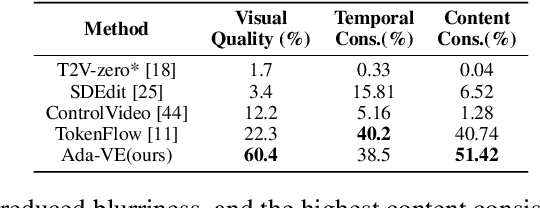
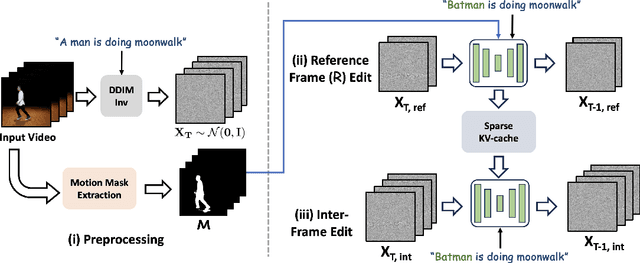

Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.