 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvPoseCNN2: Prediction and Refinement of Dense 6D Object Poses
May 23, 2022Object pose estimation is a key perceptual capability in robotics. We propose a fully-convolutional extension of the PoseCNN method, which densely predicts object translations and orientations. This has several advantages such as improving the spatial resolution of the orientation predictions -- useful in highly-cluttered arrangements, significant reduction in parameters by avoiding full connectivity, and fast inference. We propose and discuss several aggregation methods for dense orientation predictions that can be applied as a post-processing step, such as averaging and clustering techniques. We demonstrate that our method achieves the same accuracy as PoseCNN on the challenging YCB-Video dataset and provide a detailed ablation study of several variants of our method. Finally, we demonstrate that the model can be further improved by inserting an iterative refinement module into the middle of the network, which enforces consistency of the prediction.
ConvPoseCNN: Dense Convolutional 6D Object Pose Estimation
Dec 16, 2019
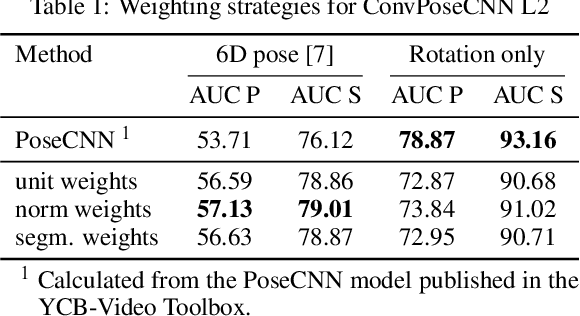

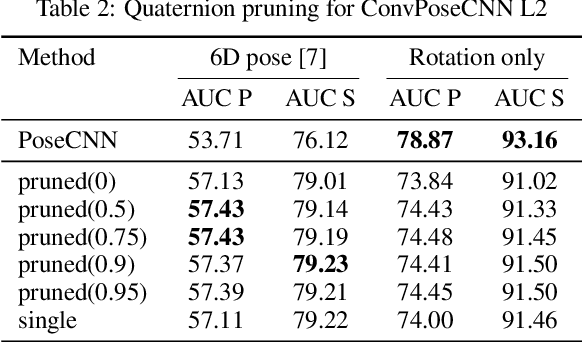
6D object pose estimation is a prerequisite for many applications. In recent years, monocular pose estimation has attracted much research interest because it does not need depth measurements. In this work, we introduce ConvPoseCNN, a fully convolutional architecture that avoids cutting out individual objects. Instead we propose pixel-wise, dense prediction of both translation and orientation components of the object pose, where the dense orientation is represented in Quaternion form. We present different approaches for aggregation of the dense orientation predictions, including averaging and clustering schemes. We evaluate ConvPoseCNN on the challenging YCB-Video Dataset, where we show that the approach has far fewer parameters and trains faster than comparable methods without sacrificing accuracy. Furthermore, our results indicate that the dense orientation prediction implicitly learns to attend to trustworthy, occlusion-free, and feature-rich object regions.