 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvPoseCNN: Dense Convolutional 6D Object Pose Estimation
Paper and Code

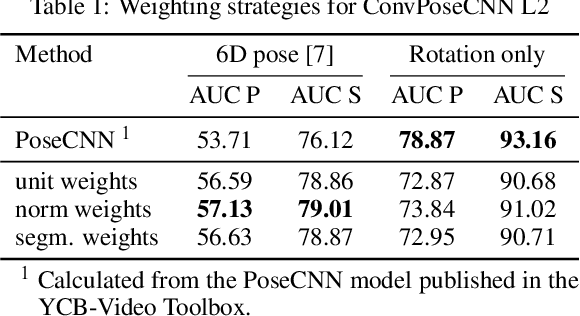

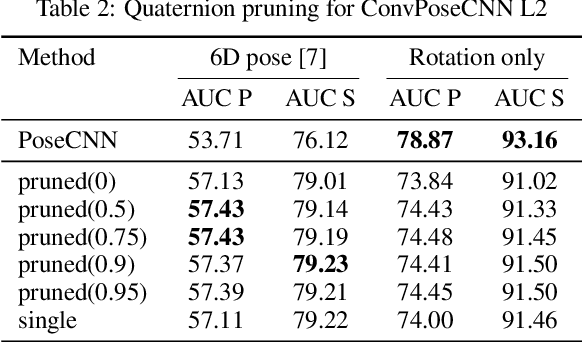
6D object pose estimation is a prerequisite for many applications. In recent years, monocular pose estimation has attracted much research interest because it does not need depth measurements. In this work, we introduce ConvPoseCNN, a fully convolutional architecture that avoids cutting out individual objects. Instead we propose pixel-wise, dense prediction of both translation and orientation components of the object pose, where the dense orientation is represented in Quaternion form. We present different approaches for aggregation of the dense orientation predictions, including averaging and clustering schemes. We evaluate ConvPoseCNN on the challenging YCB-Video Dataset, where we show that the approach has far fewer parameters and trains faster than comparable methods without sacrificing accuracy. Furthermore, our results indicate that the dense orientation prediction implicitly learns to attend to trustworthy, occlusion-free, and feature-rich object regions.