 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-responsive Object Retrieval with Memory-augmented Student-Teacher Learning
May 04, 2025Building models responsive to input prompts represents a transformative shift in machine learning. This paradigm holds significant potential for robotics problems, such as targeted manipulation amidst clutter. In this work, we present a novel approach to combine promptable foundation models with reinforcement learning (RL), enabling robots to perform dexterous manipulation tasks in a prompt-responsive manner. Existing methods struggle to link high-level commands with fine-grained dexterous control. We address this gap with a memory-augmented student-teacher learning framework. We use the Segment-Anything 2 (SAM 2) model as a perception backbone to infer an object of interest from user prompts. While detections are imperfect, their temporal sequence provides rich information for implicit state estimation by memory-augmented models. Our approach successfully learns prompt-responsive policies, demonstrated in picking objects from cluttered scenes. Videos and code are available at https://memory-student-teacher.github.io
SOLD: Reinforcement Learning with Slot Object-Centric Latent Dynamics
Oct 11, 2024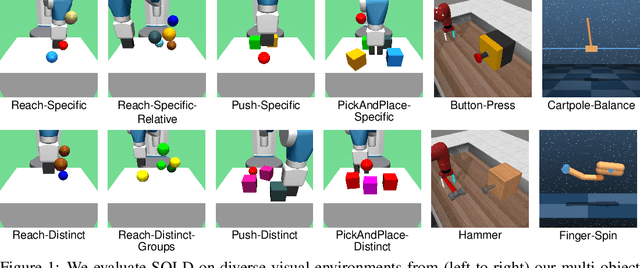

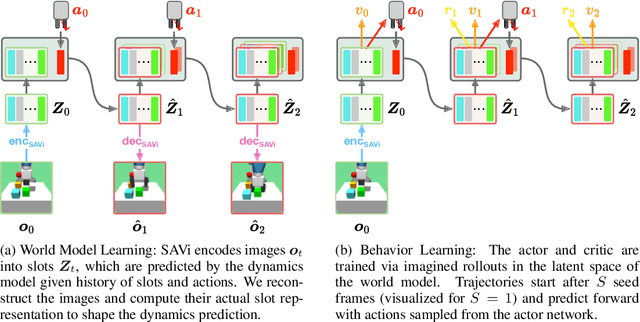

Learning a latent dynamics model provides a task-agnostic representation of an agent's understanding of its environment. Leveraging this knowledge for model-based reinforcement learning holds the potential to improve sample efficiency over model-free methods by learning inside imagined rollouts. Furthermore, because the latent space serves as input to behavior models, the informative representations learned by the world model facilitate efficient learning of desired skills. Most existing methods rely on holistic representations of the environment's state. In contrast, humans reason about objects and their interactions, forecasting how actions will affect specific parts of their surroundings. Inspired by this, we propose Slot-Attention for Object-centric Latent Dynamics (SOLD), a novel algorithm that learns object-centric dynamics models in an unsupervised manner from pixel inputs. We demonstrate that the structured latent space not only improves model interpretability but also provides a valuable input space for behavior models to reason over. Our results show that SOLD outperforms DreamerV3, a state-of-the-art model-based RL algorithm, across a range of benchmark robotic environments that evaluate for both relational reasoning and low-level manipulation capabilities. Videos are available at https://slot-latent-dynamics.github.io/.
Grasp Anything: Combining Teacher-Augmented Policy Gradient Learning with Instance Segmentation to Grasp Arbitrary Objects
Mar 15, 2024



Interactive grasping from clutter, akin to human dexterity, is one of the longest-standing problems in robot learning. Challenges stem from the intricacies of visual perception, the demand for precise motor skills, and the complex interplay between the two. In this work, we present Teacher-Augmented Policy Gradient (TAPG), a novel two-stage learning framework that synergizes reinforcement learning and policy distillation. After training a teacher policy to master the motor control based on object pose information, TAPG facilitates guided, yet adaptive, learning of a sensorimotor policy, based on object segmentation. We zero-shot transfer from simulation to a real robot by using Segment Anything Model for promptable object segmentation. Our trained policies adeptly grasp a wide variety of objects from cluttered scenarios in simulation and the real world based on human-understandable prompts. Furthermore, we show robust zero-shot transfer to novel objects. Videos of our experiments are available at \url{https://maltemosbach.github.io/grasp_anything}.
Learning Generalizable Tool Use with Non-rigid Grasp-pose Registration
Aug 01, 2023Tool use, a hallmark feature of human intelligence, remains a challenging problem in robotics due the complex contacts and high-dimensional action space. In this work, we present a novel method to enable reinforcement learning of tool use behaviors. Our approach provides a scalable way to learn the operation of tools in a new category using only a single demonstration. To this end, we propose a new method for generalizing grasping configurations of multi-fingered robotic hands to novel objects. This is used to guide the policy search via favorable initializations and a shaped reward signal. The learned policies solve complex tool use tasks and generalize to unseen tools at test time. Visualizations and videos of the trained policies are available at https://maltemosbach.github.io/generalizable_tool_use.
Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations
Dec 05, 2022Dexterous manipulation with anthropomorphic robot hands remains a challenging problem in robotics because of the high-dimensional state and action spaces and complex contacts. Nevertheless, skillful closed-loop manipulation is required to enable humanoid robots to operate in unstructured real-world environments. Reinforcement learning (RL) has traditionally imposed enormous interaction data requirements for optimizing such complex control problems. We introduce a new framework that leverages recent advances in GPU-based simulation along with the strength of imitation learning in guiding policy search towards promising behaviors to make RL training feasible in these domains. To this end, we present an immersive virtual reality teleoperation interface designed for interactive human-like manipulation on contact rich tasks and a suite of manipulation environments inspired by tasks of daily living. Finally, we demonstrate the complementary strengths of massively parallel RL and imitation learning, yielding robust and natural behaviors. Videos of trained policies, our source code, and the collected demonstration datasets are available at https://maltemosbach.github.io/interactive_ human_like_manipulation/.
Efficient Representations of Object Geometry for Reinforcement Learning of Interactive Grasping Policies
Nov 20, 2022Grasping objects of different shapes and sizes - a foundational, effortless skill for humans - remains a challenging task in robotics. Although model-based approaches can predict stable grasp configurations for known object models, they struggle to generalize to novel objects and often operate in a non-interactive open-loop manner. In this work, we present a reinforcement learning framework that learns the interactive grasping of various geometrically distinct real-world objects by continuously controlling an anthropomorphic robotic hand. We explore several explicit representations of object geometry as input to the policy. Moreover, we propose to inform the policy implicitly through signed distances and show that this is naturally suited to guide the search through a shaped reward component. Finally, we demonstrate that the proposed framework is able to learn even in more challenging conditions, such as targeted grasping from a cluttered bin. Necessary pre-grasping behaviors such as object reorientation and utilization of environmental constraints emerge in this case. Videos of learned interactive policies are available at https://maltemosbach.github. io/geometry_aware_grasping_policies.
Fourier-based Video Prediction through Relational Object Motion
Oct 12, 2021


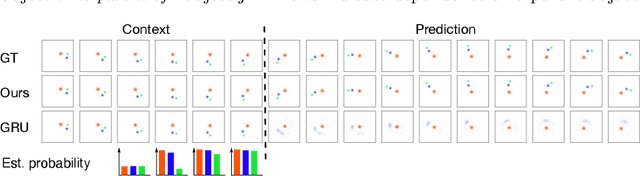
The ability to predict future outcomes conditioned on observed video frames is crucial for intelligent decision-making in autonomous systems. Recently, deep recurrent architectures have been applied to the task of video prediction. However, this often results in blurry predictions and requires tedious training on large datasets. Here, we explore a different approach by (1) using frequency-domain approaches for video prediction and (2) explicitly inferring object-motion relationships in the observed scene. The resulting predictions are consistent with the observed dynamics in a scene and do not suffer from blur.