Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier-based Video Prediction through Relational Object Motion
Paper and Code
Oct 12, 2021


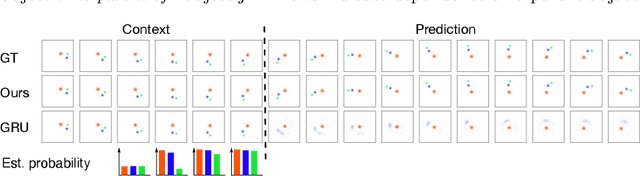
The ability to predict future outcomes conditioned on observed video frames is crucial for intelligent decision-making in autonomous systems. Recently, deep recurrent architectures have been applied to the task of video prediction. However, this often results in blurry predictions and requires tedious training on large datasets. Here, we explore a different approach by (1) using frequency-domain approaches for video prediction and (2) explicitly inferring object-motion relationships in the observed scene. The resulting predictions are consistent with the observed dynamics in a scene and do not suffer from blur.
View paper on