 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Prediction: Which One Should Come First, Recognition or Prediction?
Oct 06, 2021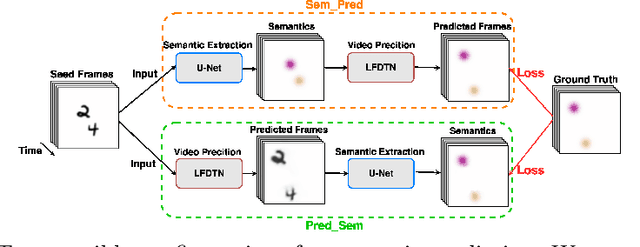
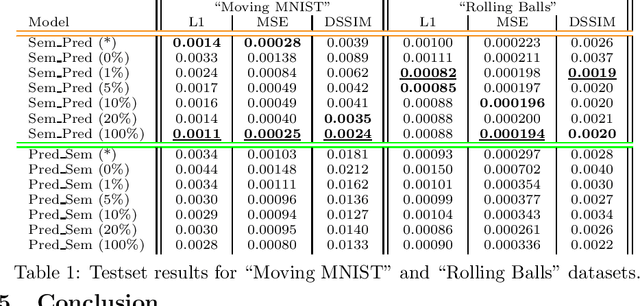
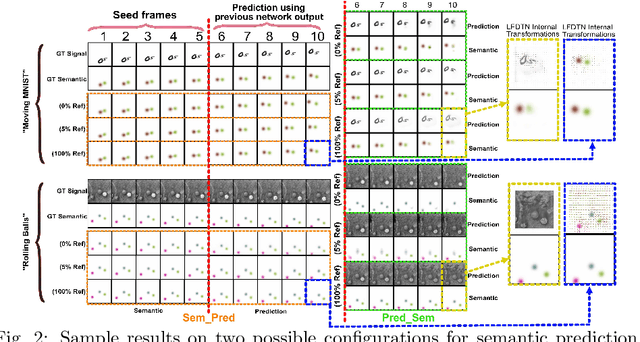
The ultimate goal of video prediction is not forecasting future pixel-values given some previous frames. Rather, the end goal of video prediction is to discover valuable internal representations from the vast amount of available unlabeled video data in a self-supervised fashion for downstream tasks. One of the primary downstream tasks is interpreting the scene's semantic composition and using it for decision-making. For example, by predicting human movements, an observer can anticipate human activities and collaborate in a shared workspace. There are two main ways to achieve the same outcome, given a pre-trained video prediction and pre-trained semantic extraction model; one can first apply predictions and then extract semantics or first extract semantics and then predict. We investigate these configurations using the Local Frequency Domain Transformer Network (LFDTN) as the video prediction model and U-Net as the semantic extraction model on synthetic and real datasets.
Real-time Pose Estimation from Images for Multiple Humanoid Robots
Jul 06, 2021
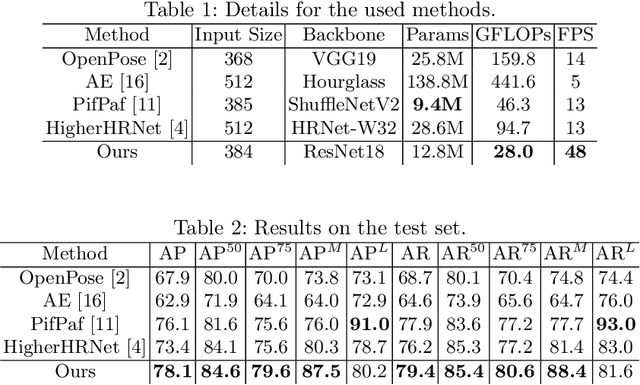

Pose estimation commonly refers to computer vision methods that recognize people's body postures in images or videos. With recent advancements in deep learning, we now have compelling models to tackle the problem in real-time. Since these models are usually designed for human images, one needs to adapt existing models to work on other creatures, including robots. This paper examines different state-of-the-art pose estimation models and proposes a lightweight model that can work in real-time on humanoid robots in the RoboCup Humanoid League environment. Additionally, we present a novel dataset called the HumanoidRobotPose dataset. The results of this work have the potential to enable many advanced behaviors for soccer-playing robots.
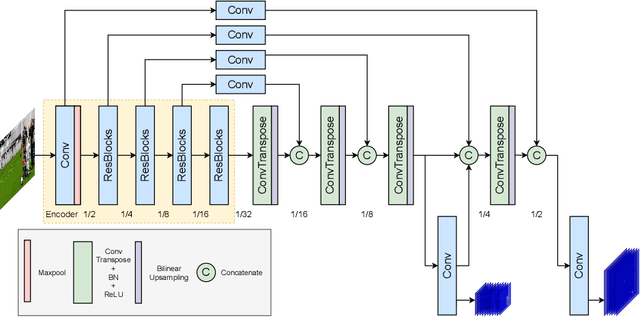
Local Frequency Domain Transformer Networks for Video Prediction
May 10, 2021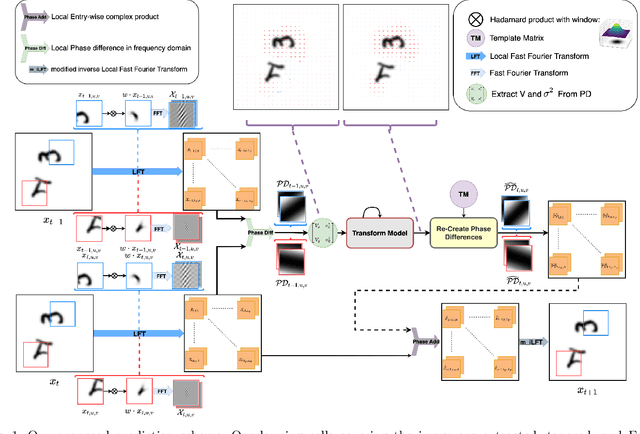

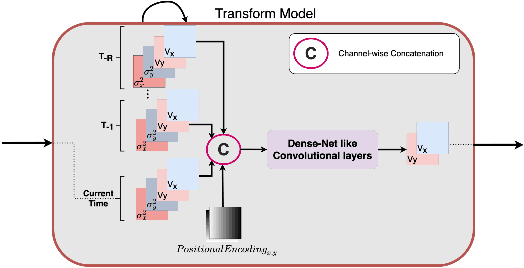
Video prediction is commonly referred to as forecasting future frames of a video sequence provided several past frames thereof. It remains a challenging domain as visual scenes evolve according to complex underlying dynamics, such as the camera's egocentric motion or the distinct motility per individual object viewed. These are mostly hidden from the observer and manifest as often highly non-linear transformations between consecutive video frames. Therefore, video prediction is of interest not only in anticipating visual changes in the real world but has, above all, emerged as an unsupervised learning rule targeting the formation and dynamics of the observed environment. Many of the deep learning-based state-of-the-art models for video prediction utilize some form of recurrent layers like Long Short-Term Memory (LSTMs) or Gated Recurrent Units (GRUs) at the core of their models. Although these models can predict the future frames, they rely entirely on these recurrent structures to simultaneously perform three distinct tasks: extracting transformations, projecting them into the future, and transforming the current frame. In order to completely interpret the formed internal representations, it is crucial to disentangle these tasks. This paper proposes a fully differentiable building block that can perform all of those tasks separately while maintaining interpretability. We derive the relevant theoretical foundations and showcase results on synthetic as well as real data. We demonstrate that our method is readily extended to perform motion segmentation and account for the scene's composition, and learns to produce reliable predictions in an entirely interpretable manner by only observing unlabeled video data.
NimbRo-OP2X: Affordable Adult-sized 3D-printed Open-Source Humanoid Robot for Research
Oct 19, 2020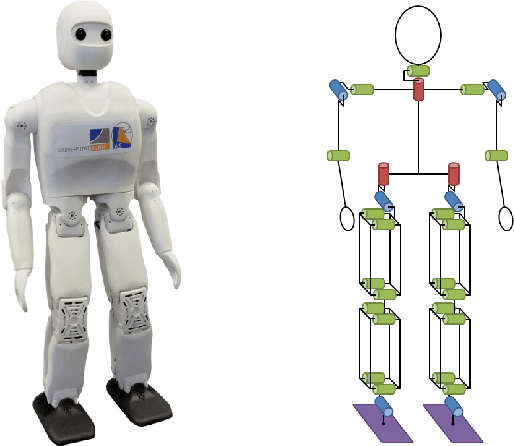
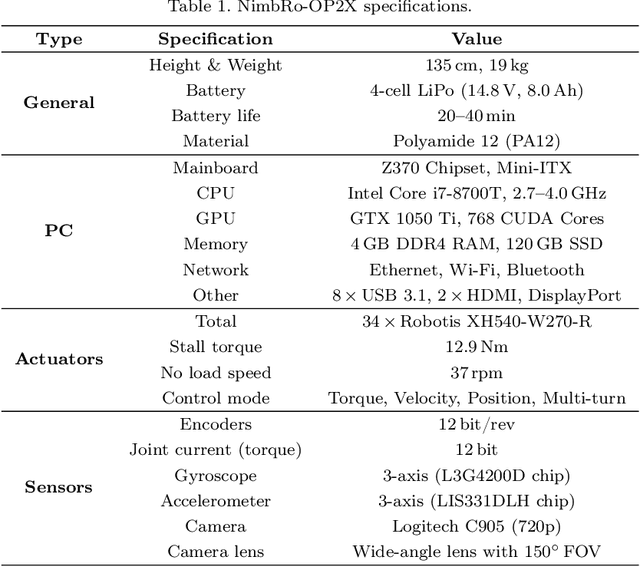
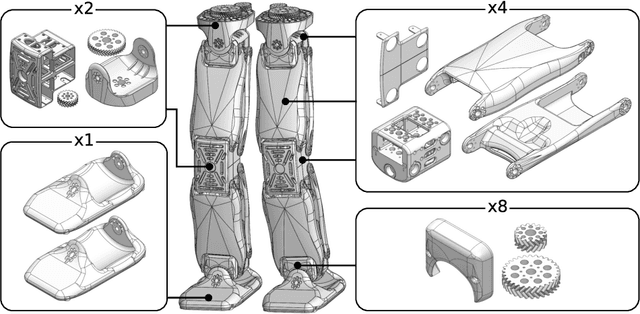
For several years, high development and production costs of humanoid robots restricted researchers interested in working in the field. To overcome this problem, several research groups have opted to work with simulated or smaller robots, whose acquisition costs are significantly lower. However, due to scale differences and imperfect simulation replicability, results may not be directly reproducible on real, adult-sized robots. In this paper, we present the NimbRo-OP2X, a capable and affordable adult-sized humanoid platform aiming to significantly lower the entry barrier for humanoid robot research. With a height of 135 cm and weight of only 19 kg, the robot can interact in an unmodified, human environment without special safety equipment. Modularity in hardware and software allow this platform enough flexibility to operate in different scenarios and applications with minimal effort. The robot is equipped with an on-board computer with GPU, which enables the implementation of state-of-the-art approaches for object detection and human perception demanded by areas such as manipulation and human-robot interaction. Finally, the capabilities of the NimbRo-OP2X, especially in terms of locomotion stability and visual perception, are evaluated. This includes the performance at RoboCup 2018, where NimbRo-OP2X won all possible awards in the AdultSize class.
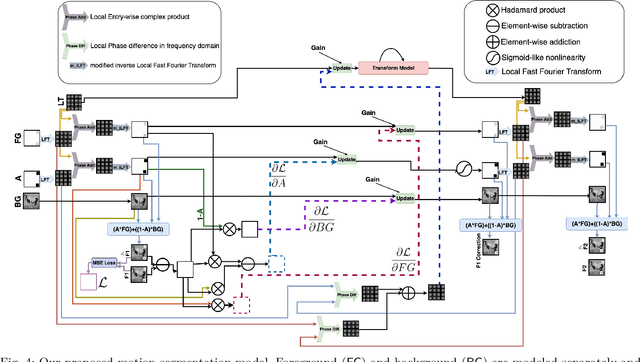
Motion Segmentation using Frequency Domain Transformer Networks
Apr 18, 2020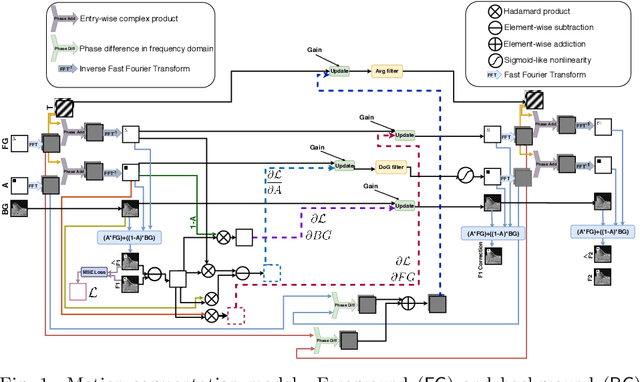


Self-supervised prediction is a powerful mechanism to learn representations that capture the underlying structure of the data. Despite recent progress, the self-supervised video prediction task is still challenging. One of the critical factors that make the task hard is motion segmentation, which is segmenting individual objects and the background and estimating their motion separately. In video prediction, the shape, appearance, and transformation of each object should be understood only by predicting the next frame in pixel space. To address this task, we propose a novel end-to-end learnable architecture that predicts the next frame by modeling foreground and background separately while simultaneously estimating and predicting the foreground motion using Frequency Domain Transformer Networks. Experimental evaluations show that this yields interpretable representations and that our approach can outperform some widely used video prediction methods like Video Ladder Network and Predictive Gated Pyramids on synthetic data.
RoboCup 2019 AdultSize Winner NimbRo: Deep Learning Perception, In-Walk Kick, Push Recovery, and Team Play Capabilities
Dec 17, 2019
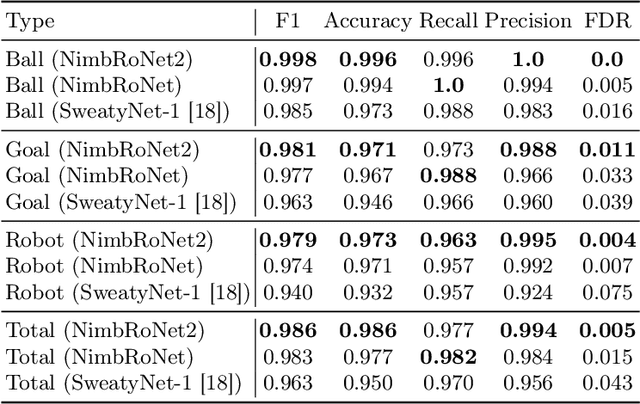
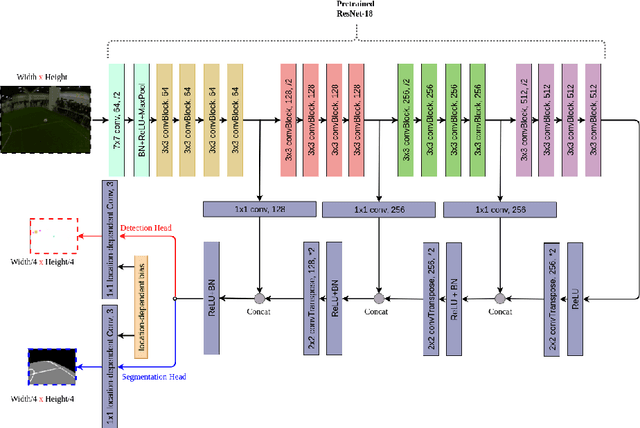
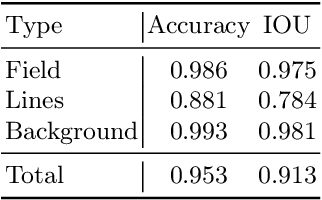
Individual and team capabilities are challenged every year by rule changes and the increasing performance of the soccer teams at RoboCup Humanoid League. For RoboCup 2019 in the AdultSize class, the number of players (2 vs. 2 games) and the field dimensions were increased, which demanded for team coordination and robust visual perception and localization modules. In this paper, we present the latest developments that lead team NimbRo to win the soccer tournament, drop-in games, technical challenges and the Best Humanoid Award of the RoboCup Humanoid League 2019 in Sydney. These developments include a deep learning vision system, in-walk kicks, step-based push-recovery, and team play strategies.
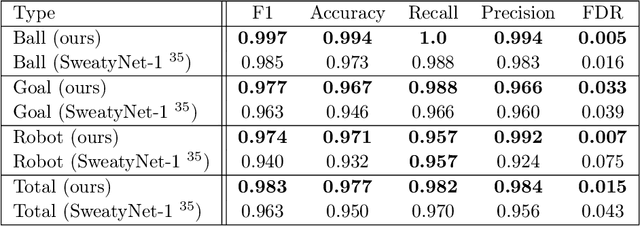
Utilizing Temporal Information in Deep Convolutional Network for Efficient Soccer Ball Detection and Tracking
Sep 06, 2019

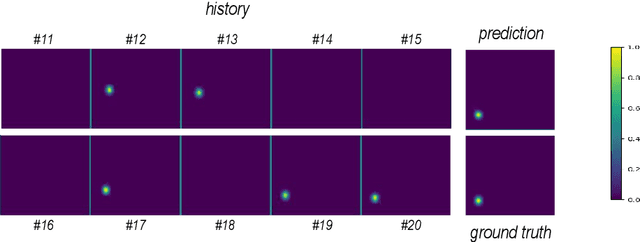
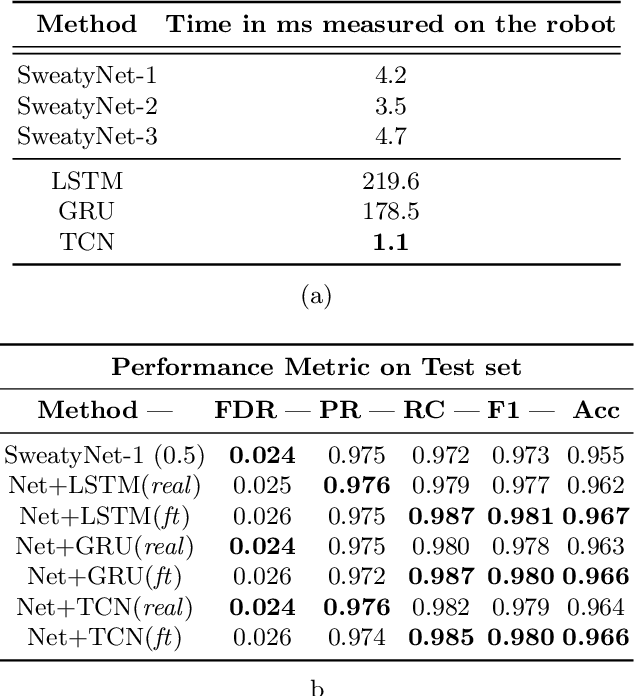
Soccer ball detection is identified as one of the critical challenges in the RoboCup competition. It requires an efficient vision system capable of handling the task of detection with high precision and recall and providing robust and low inference time. In this work, we present a novel convolutional neural network (CNN) approach to detect the soccer ball in an image sequence. In contrast to the existing methods where only the current frame or an image is used for the detection, we make use of the history of frames. Using history allows to efficiently track the ball in situations where the ball disappears or gets partially occluded in some of the frames. Our approach exploits spatio-temporal correlation and detects the ball based on the trajectory of its movements. We present our results with three convolutional methods, namely temporal convolutional networks (TCN), ConvLSTM, and ConvGRU. We first solve the detection task for an image using fully convolutional encoder-decoder architecture, and later, we use it as an input to our temporal models and jointly learn the detection task in sequences of images. We evaluate all our experiments on a novel dataset prepared as a part of this work. Furthermore, we present empirical results to support the effectiveness of using the history of the ball in challenging scenarios.
NimbRo Robots Winning RoboCup 2018 Humanoid AdultSize Soccer Competitions
Sep 05, 2019
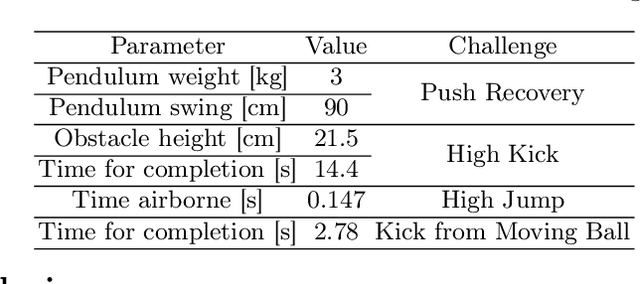

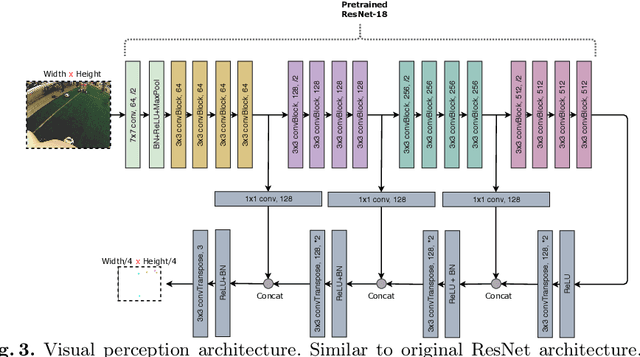
Over the past few years, the Humanoid League rules have changed towards more realistic and challenging game environments, which encourage teams to advance their robot soccer performances. In this paper, we present the software and hardware designs that led our team NimbRo to win the competitions in the AdultSize league -- including the soccer tournament, the drop-in games, and the technical challenges at RoboCup 2018 in Montreal. Altogether, this resulted in NimbRo winning the Best Humanoid Award. In particular, we describe our deep-learning approaches for visual perception and our new fully 3D printed robot NimbRo-OP2X.
Frequency Domain Transformer Networks for Video Prediction
Mar 01, 2019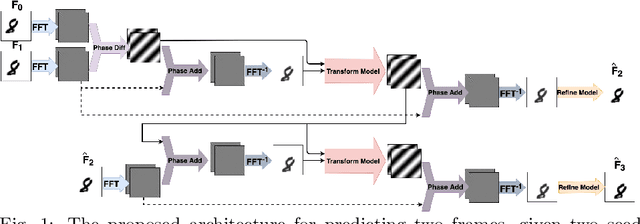



The task of video prediction is forecasting the next frames given some previous frames. Despite much recent progress, this task is still challenging mainly due to high nonlinearity in the spatial domain. To address this issue, we propose a novel architecture, Frequency Domain Transformer Network (FDTN), which is an end-to-end learnable model that estimates and uses the transformations of the signal in the frequency domain. Experimental evaluations show that this approach can outperform some widely used video prediction methods like Video Ladder Network (VLN) and Predictive Gated Pyramids (PGP).
NimbRo-OP2X: Adult-sized Open-source 3D Printed Humanoid Robot
Oct 19, 2018


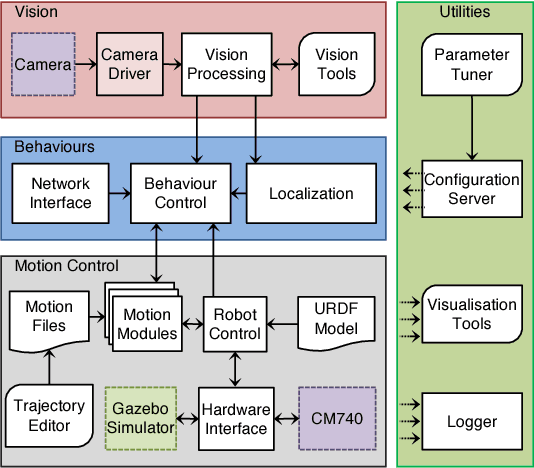
Humanoid robotics research depends on capable robot platforms, but recently developed advanced platforms are often not available to other research groups, expensive, dangerous to operate, or closed-source. The lack of available platforms forces researchers to work with smaller robots, which have less strict dynamic constraints or with simulations, which lack many real-world effects. We developed NimbRo-OP2X to address this need. At a height of 135 cm our robot is large enough to interact in a human environment. Its low weight of only 19 kg makes the operation of the robot safe and easy, as no special operational equipment is necessary. Our robot is equipped with a fast onboard computer and a GPU to accelerate parallel computations. We extend our already open-source software by a deep-learning based vision system and gait parameter optimisation. The NimbRo-OP2X was evaluated during RoboCup 2018 in Montr\'eal, Canada, where it won all possible awards in the Humanoid AdultSize class.