 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointing-Guided Target Estimation via Transformer-Based Attention
Sep 05, 2025Deictic gestures, like pointing, are a fundamental form of non-verbal communication, enabling humans to direct attention to specific objects or locations. This capability is essential in Human-Robot Interaction (HRI), where robots should be able to predict human intent and anticipate appropriate responses. In this work, we propose the Multi-Modality Inter-TransFormer (MM-ITF), a modular architecture to predict objects in a controlled tabletop scenario with the NICOL robot, where humans indicate targets through natural pointing gestures. Leveraging inter-modality attention, MM-ITF maps 2D pointing gestures to object locations, assigns a likelihood score to each, and identifies the most likely target. Our results demonstrate that the method can accurately predict the intended object using monocular RGB data, thus enabling intuitive and accessible human-robot collaboration. To evaluate the performance, we introduce a patch confusion matrix, providing insights into the model's predictions across candidate object locations. Code available at: https://github.com/lucamuellercode/MMITF.
Keypoint-based Diffusion for Robotic Motion Planning on the NICOL Robot
Sep 04, 2025We propose a novel diffusion-based action model for robotic motion planning. Commonly, established numerical planning approaches are used to solve general motion planning problems, but have significant runtime requirements. By leveraging the power of deep learning, we are able to achieve good results in a much smaller runtime by learning from a dataset generated by these planners. While our initial model uses point cloud embeddings in the input to predict keypoint-based joint sequences in its output, we observed in our ablation study that it remained challenging to condition the network on the point cloud embeddings. We identified some biases in our dataset and refined it, which improved the model's performance. Our model, even without the use of the point cloud encodings, outperforms numerical models by an order of magnitude regarding the runtime, while reaching a success rate of up to 90% of collision free solutions on the test set.
Balancing long- and short-term dynamics for the modeling of saliency in videos
Apr 08, 2025The role of long- and short-term dynamics towards salient object detection in videos is under-researched. We present a Transformer-based approach to learn a joint representation of video frames and past saliency information. Our model embeds long- and short-term information to detect dynamically shifting saliency in video. We provide our model with a stream of video frames and past saliency maps, which acts as a prior for the next prediction, and extract spatiotemporal tokens from both modalities. The decomposition of the frame sequence into tokens lets the model incorporate short-term information from within the token, while being able to make long-term connections between tokens throughout the sequence. The core of the system consists of a dual-stream Transformer architecture to process the extracted sequences independently before fusing the two modalities. Additionally, we apply a saliency-based masking scheme to the input frames to learn an embedding that facilitates the recognition of deviations from previous outputs. We observe that the additional prior information aids in the first detection of the salient location. Our findings indicate that the ratio of spatiotemporal long- and short-term features directly impacts the model's performance. While increasing the short-term context is beneficial up to a certain threshold, the model's performance greatly benefits from an expansion of the long-term context.
Robots Can Multitask Too: Integrating a Memory Architecture and LLMs for Enhanced Cross-Task Robot Action Generation
Jul 18, 2024Large Language Models (LLMs) have been recently used in robot applications for grounding LLM common-sense reasoning with the robot's perception and physical abilities. In humanoid robots, memory also plays a critical role in fostering real-world embodiment and facilitating long-term interactive capabilities, especially in multi-task setups where the robot must remember previous task states, environment states, and executed actions. In this paper, we address incorporating memory processes with LLMs for generating cross-task robot actions, while the robot effectively switches between tasks. Our proposed dual-layered architecture features two LLMs, utilizing their complementary skills of reasoning and following instructions, combined with a memory model inspired by human cognition. Our results show a significant improvement in performance over a baseline of five robotic tasks, demonstrating the potential of integrating memory with LLMs for combining the robot's action and perception for adaptive task execution.
Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion
Jul 15, 2024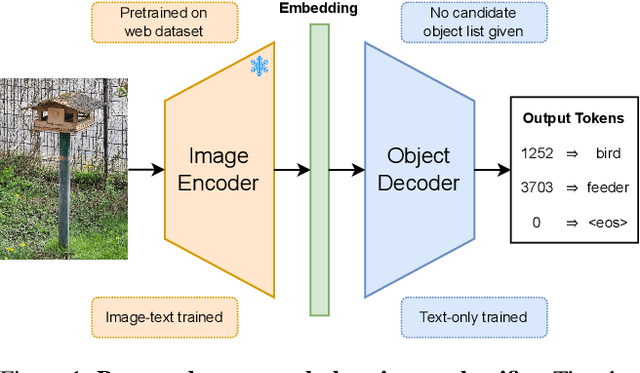
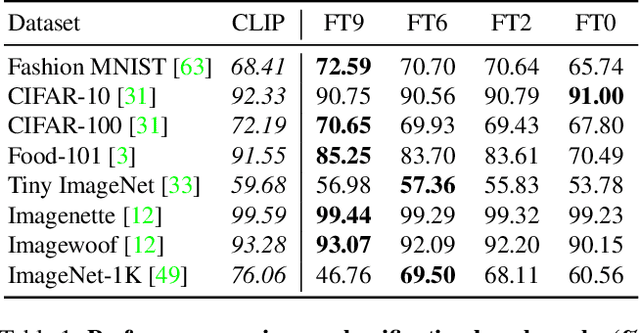
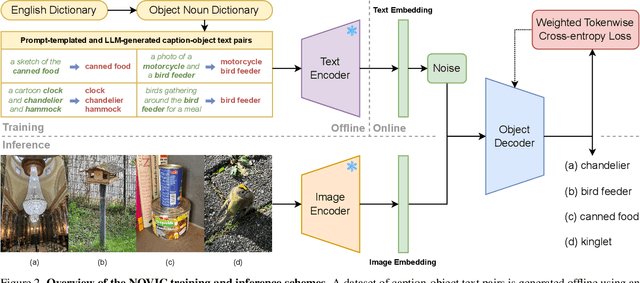
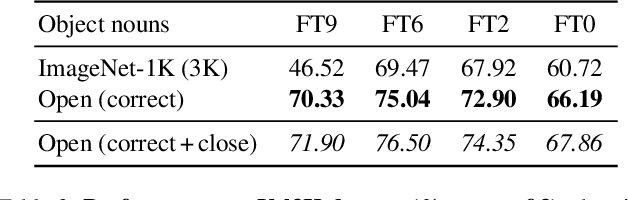
We introduce NOVIC, an innovative uNconstrained Open Vocabulary Image Classifier that uses an autoregressive transformer to generatively output classification labels as language. Leveraging the extensive knowledge of CLIP models, NOVIC harnesses the embedding space to enable zero-shot transfer from pure text to images. Traditional CLIP models, despite their ability for open vocabulary classification, require an exhaustive prompt of potential class labels, restricting their application to images of known content or context. To address this, we propose an "object decoder" model that is trained on a large-scale 92M-target dataset of templated object noun sets and LLM-generated captions to always output the object noun in question. This effectively inverts the CLIP text encoder and allows textual object labels to be generated directly from image-derived embedding vectors, without requiring any a priori knowledge of the potential content of an image. The trained decoders are tested on a mix of manually and web-curated datasets, as well as standard image classification benchmarks, and achieve fine-grained prompt-free prediction scores of up to 87.5%, a strong result considering the model must work for any conceivable image and without any contextual clues.
When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration
Jun 29, 2024
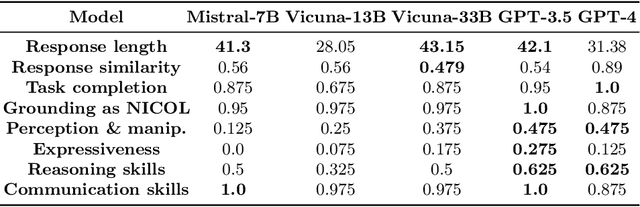
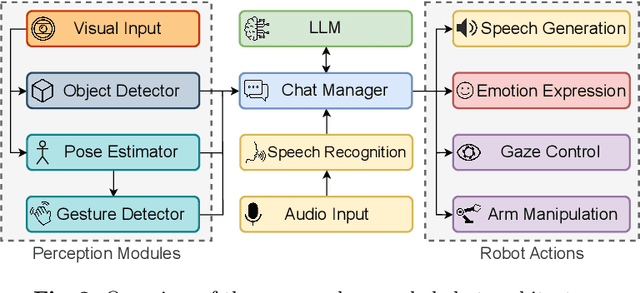
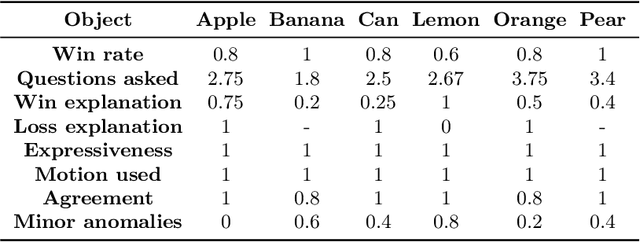
We investigate the use of Large Language Models (LLMs) to equip neural robotic agents with human-like social and cognitive competencies, for the purpose of open-ended human-robot conversation and collaboration. We introduce a modular and extensible methodology for grounding an LLM with the sensory perceptions and capabilities of a physical robot, and integrate multiple deep learning models throughout the architecture in a form of system integration. The integrated models encompass various functions such as speech recognition, speech generation, open-vocabulary object detection, human pose estimation, and gesture detection, with the LLM serving as the central text-based coordinating unit. The qualitative and quantitative results demonstrate the huge potential of LLMs in providing emergent cognition and interactive language-oriented control of robots in a natural and social manner.
Comparing Apples to Oranges: LLM-powered Multimodal Intention Prediction in an Object Categorization Task
Apr 12, 2024Intention-based Human-Robot Interaction (HRI) systems allow robots to perceive and interpret user actions to proactively interact with humans and adapt to their behavior. Therefore, intention prediction is pivotal in creating a natural interactive collaboration between humans and robots. In this paper, we examine the use of Large Language Models (LLMs) for inferring human intention during a collaborative object categorization task with a physical robot. We introduce a hierarchical approach for interpreting user non-verbal cues, like hand gestures, body poses, and facial expressions and combining them with environment states and user verbal cues captured using an existing Automatic Speech Recognition (ASR) system. Our evaluation demonstrates the potential of LLMs to interpret non-verbal cues and to combine them with their context-understanding capabilities and real-world knowledge to support intention prediction during human-robot interaction.
Inverse Kinematics for Neuro-Robotic Grasping with Humanoid Embodied Agents
Apr 12, 2024
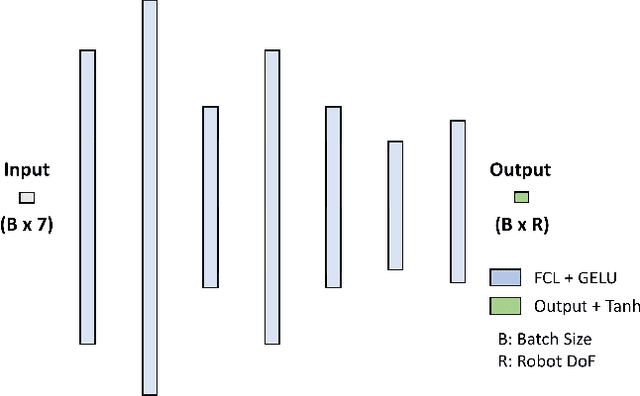
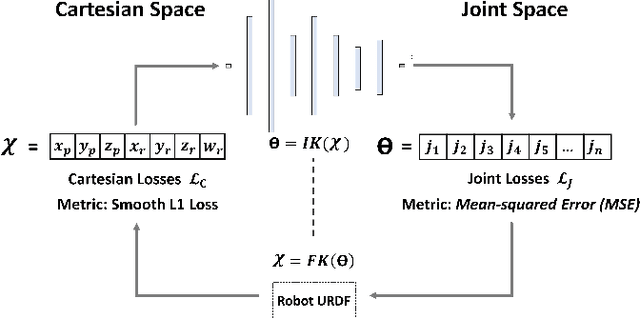
This paper introduces a novel zero-shot motion planning method that allows users to quickly design smooth robot motions in Cartesian space. A B\'ezier curve-based Cartesian plan is transformed into a joint space trajectory by our neuro-inspired inverse kinematics (IK) method CycleIK, for which we enable platform independence by scaling it to arbitrary robot designs. The motion planner is evaluated on the physical hardware of the two humanoid robots NICO and NICOL in a human-in-the-loop grasping scenario. Our method is deployed with an embodied agent that is a large language model (LLM) at its core. We generalize the embodied agent, that was introduced for NICOL, to also be embodied by NICO. The agent can execute a discrete set of physical actions and allows the user to verbally instruct various different robots. We contribute a grasping primitive to its action space that allows for precise manipulation of household objects. The new CycleIK method is compared to popular numerical IK solvers and state-of-the-art neural IK methods in simulation and is shown to be competitive with or outperform all evaluated methods when the algorithm runtime is very short. The grasping primitive is evaluated on both NICOL and NICO robots with a reported grasp success of 72% to 82% for each robot, respectively.
Human Impression of Humanoid Robots Mirroring Social Cues
Jan 22, 2024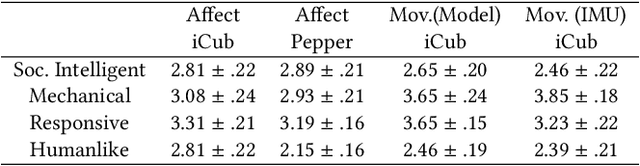

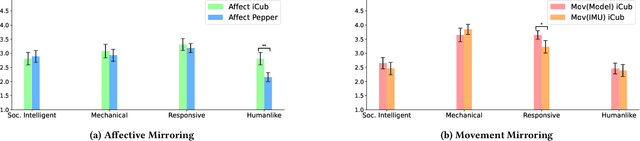
Mirroring non-verbal social cues such as affect or movement can enhance human-human and human-robot interactions in the real world. The robotic platforms and control methods also impact people's perception of human-robot interaction. However, limited studies have compared robot imitation across different platforms and control methods. Our research addresses this gap by conducting two experiments comparing people's perception of affective mirroring between the iCub and Pepper robots and movement mirroring between vision-based iCub control and Inertial Measurement Unit (IMU)-based iCub control. We discovered that the iCub robot was perceived as more humanlike than the Pepper robot when mirroring affect. A vision-based controlled iCub outperformed the IMU-based controlled one in the movement mirroring task. Our findings suggest that different robotic platforms impact people's perception of robots' mirroring during HRI. The control method also contributes to the robot's mirroring performance. Our work sheds light on the design and application of different humanoid robots in the real world.
CycleIK: Neuro-inspired Inverse Kinematics
Jul 21, 2023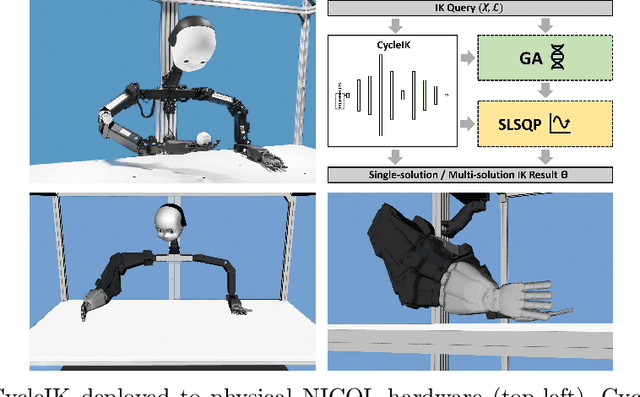

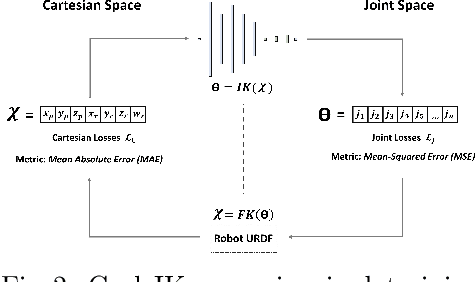
The paper introduces CycleIK, a neuro-robotic approach that wraps two novel neuro-inspired methods for the inverse kinematics (IK) task, a Generative Adversarial Network (GAN), and a Multi-Layer Perceptron architecture. These methods can be used in a standalone fashion, but we also show how embedding these into a hybrid neuro-genetic IK pipeline allows for further optimization via sequential least-squares programming (SLSQP) or a genetic algorithm (GA). The models are trained and tested on dense datasets that were collected from random robot configurations of the new Neuro-Inspired COLlaborator (NICOL), a semi-humanoid robot with two redundant 8-DoF manipulators. We utilize the weighted multi-objective function from the state-of-the-art BioIK method to support the training process and our hybrid neuro-genetic architecture. We show that the neural models can compete with state-of-the-art IK approaches, which allows for deployment directly to robotic hardware. Additionally, it is shown that the incorporation of the genetic algorithm improves the precision while simultaneously reducing the overall runtime.