 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion
Paper and Code
Jul 15, 2024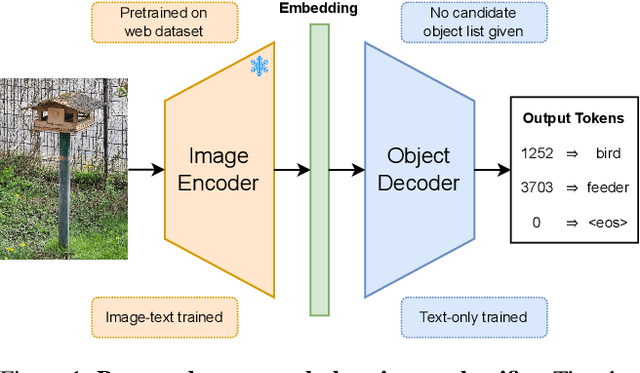
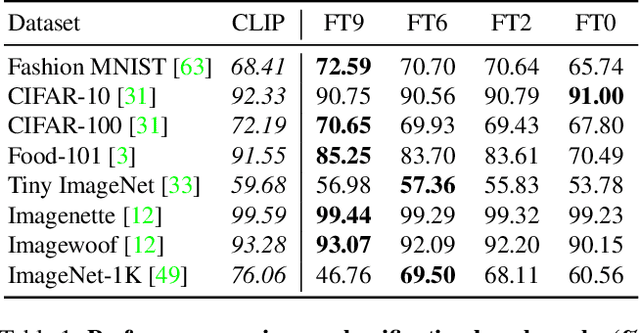
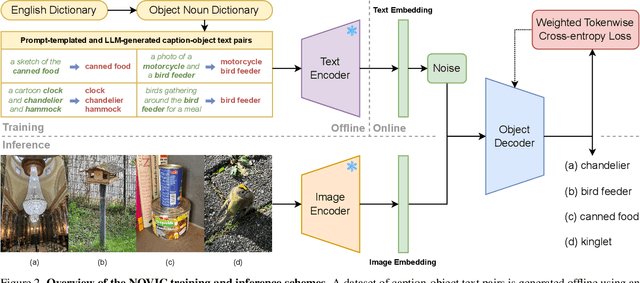
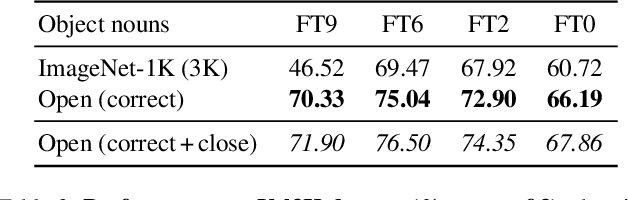
We introduce NOVIC, an innovative uNconstrained Open Vocabulary Image Classifier that uses an autoregressive transformer to generatively output classification labels as language. Leveraging the extensive knowledge of CLIP models, NOVIC harnesses the embedding space to enable zero-shot transfer from pure text to images. Traditional CLIP models, despite their ability for open vocabulary classification, require an exhaustive prompt of potential class labels, restricting their application to images of known content or context. To address this, we propose an "object decoder" model that is trained on a large-scale 92M-target dataset of templated object noun sets and LLM-generated captions to always output the object noun in question. This effectively inverts the CLIP text encoder and allows textual object labels to be generated directly from image-derived embedding vectors, without requiring any a priori knowledge of the potential content of an image. The trained decoders are tested on a mix of manually and web-curated datasets, as well as standard image classification benchmarks, and achieve fine-grained prompt-free prediction scores of up to 87.5%, a strong result considering the model must work for any conceivable image and without any contextual clues.