 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion
Jul 15, 2024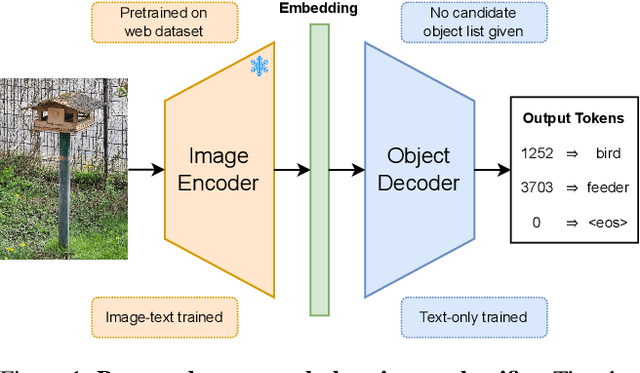
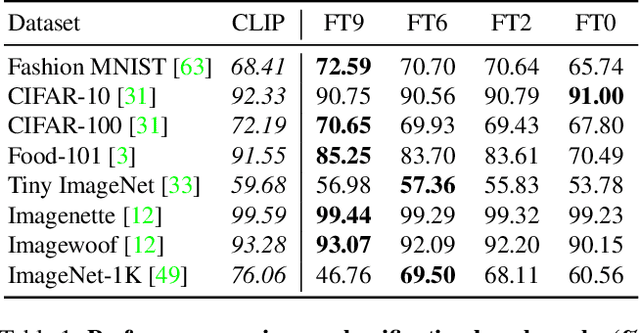
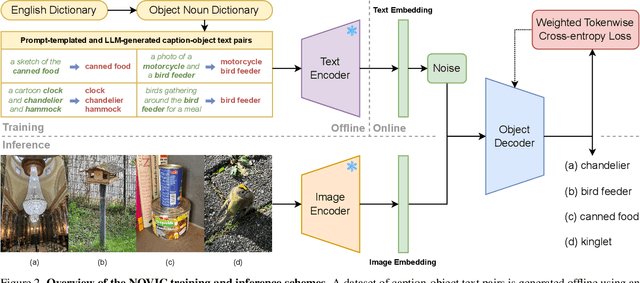
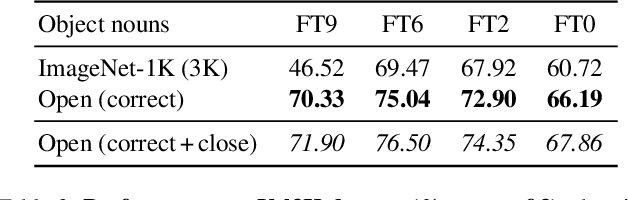
We introduce NOVIC, an innovative uNconstrained Open Vocabulary Image Classifier that uses an autoregressive transformer to generatively output classification labels as language. Leveraging the extensive knowledge of CLIP models, NOVIC harnesses the embedding space to enable zero-shot transfer from pure text to images. Traditional CLIP models, despite their ability for open vocabulary classification, require an exhaustive prompt of potential class labels, restricting their application to images of known content or context. To address this, we propose an "object decoder" model that is trained on a large-scale 92M-target dataset of templated object noun sets and LLM-generated captions to always output the object noun in question. This effectively inverts the CLIP text encoder and allows textual object labels to be generated directly from image-derived embedding vectors, without requiring any a priori knowledge of the potential content of an image. The trained decoders are tested on a mix of manually and web-curated datasets, as well as standard image classification benchmarks, and achieve fine-grained prompt-free prediction scores of up to 87.5%, a strong result considering the model must work for any conceivable image and without any contextual clues.
Read Between the Layers: Leveraging Intra-Layer Representations for Rehearsal-Free Continual Learning with Pre-Trained Models
Dec 13, 2023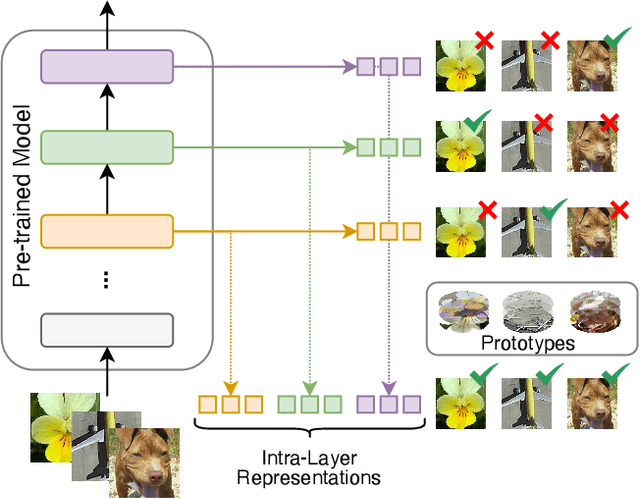
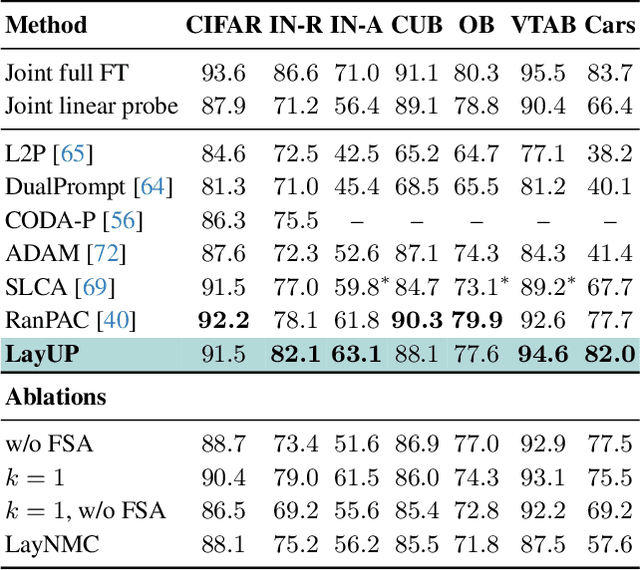
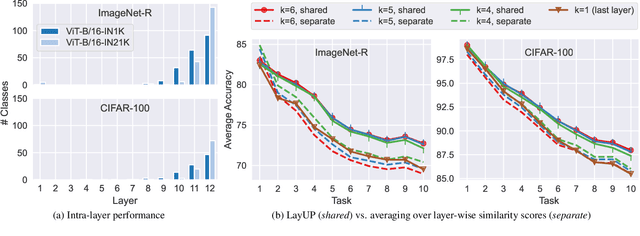
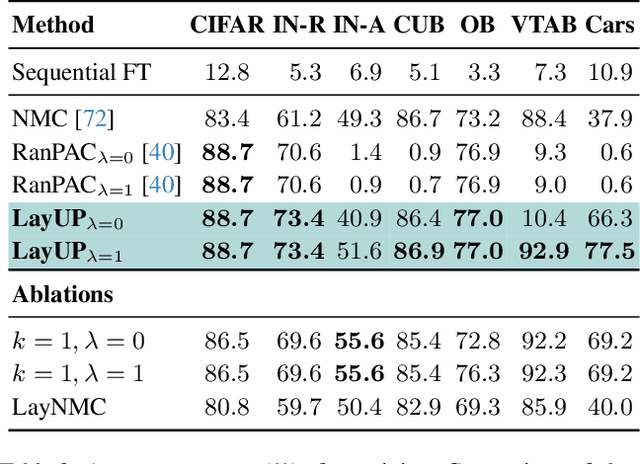
We address the Continual Learning (CL) problem, where a model has to learn a sequence of tasks from non-stationary distributions while preserving prior knowledge as it encounters new experiences. With the advancement of foundation models, CL research has shifted focus from the initial learning-from-scratch paradigm to the use of generic features from large-scale pre-training. However, existing approaches to CL with pre-trained models only focus on separating the class-specific features from the final representation layer and neglect the power of intermediate representations that capture low- and mid-level features naturally more invariant to domain shifts. In this work, we propose LayUP, a new class-prototype-based approach to continual learning that leverages second-order feature statistics from multiple intermediate layers of a pre-trained network. Our method is conceptually simple, does not require any replay buffer, and works out of the box with any foundation model. LayUP improves over the state-of-the-art on four of the seven class-incremental learning settings at a considerably reduced memory and computational footprint compared with the next best baseline. Our results demonstrate that fully exhausting the representational capacities of pre-trained models in CL goes far beyond their final embeddings.
Visually Grounded Continual Language Learning with Selective Specialization
Oct 24, 2023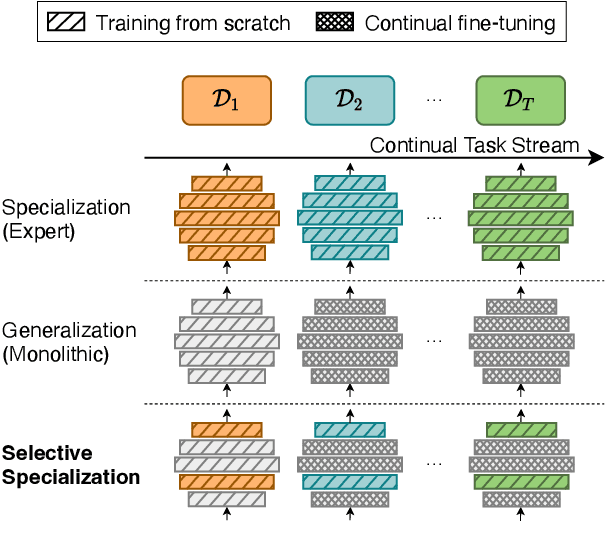
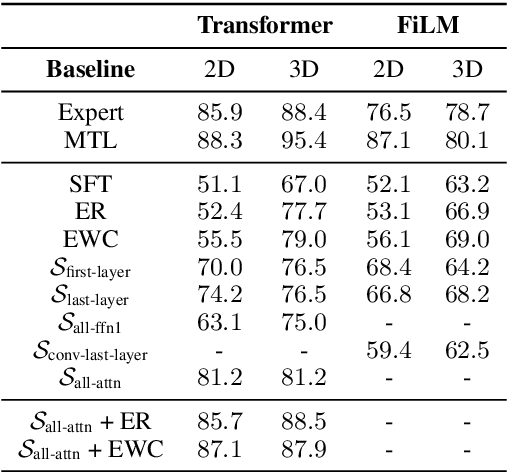
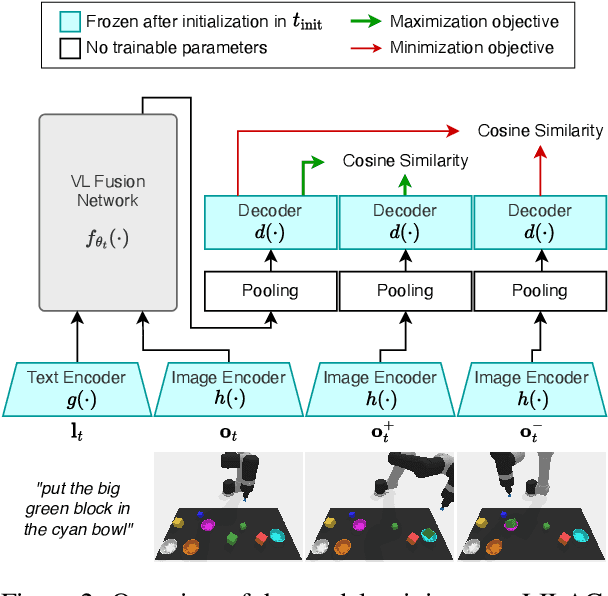
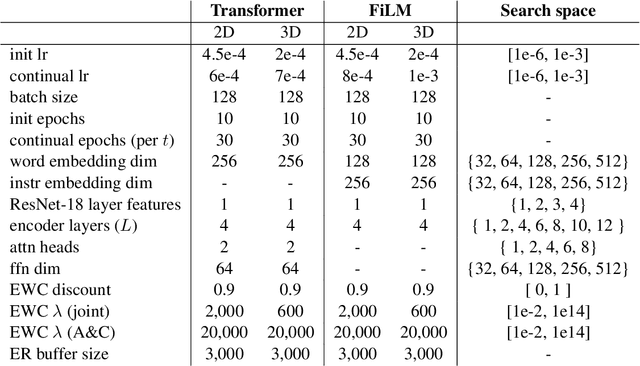
A desirable trait of an artificial agent acting in the visual world is to continually learn a sequence of language-informed tasks while striking a balance between sufficiently specializing in each task and building a generalized knowledge for transfer. Selective specialization, i.e., a careful selection of model components to specialize in each task, is a strategy to provide control over this trade-off. However, the design of selection strategies requires insights on the role of each model component in learning rather specialized or generalizable representations, which poses a gap in current research. Thus, our aim with this work is to provide an extensive analysis of selection strategies for visually grounded continual language learning. Due to the lack of suitable benchmarks for this purpose, we introduce two novel diagnostic datasets that provide enough control and flexibility for a thorough model analysis. We assess various heuristics for module specialization strategies as well as quantifiable measures for two different types of model architectures. Finally, we design conceptually simple approaches based on our analysis that outperform common continual learning baselines. Our results demonstrate the need for further efforts towards better aligning continual learning algorithms with the learning behaviors of individual model parts.
The Emotional Dilemma: Influence of a Human-like Robot on Trust and Cooperation
Jul 06, 2023Increasing anthropomorphic robot behavioral design could affect trust and cooperation positively. However, studies have shown contradicting results and suggest a task-dependent relationship between robots that display emotions and trust. Therefore, this study analyzes the effect of robots that display human-like emotions on trust, cooperation, and participants' emotions. In the between-group study, participants play the coin entrustment game with an emotional and a non-emotional robot. The results show that the robot that displays emotions induces more anxiety than the neutral robot. Accordingly, the participants trust the emotional robot less and are less likely to cooperate. Furthermore, the perceived intelligence of a robot increases trust, while a desire to outcompete the robot can reduce trust and cooperation. Thus, the design of robots expressing emotions should be task dependent to avoid adverse effects that reduce trust and cooperation.
Neuro-Symbolic Spatio-Temporal Reasoning
Nov 28, 2022Knowledge about space and time is necessary to solve problems in the physical world: An AI agent situated in the physical world and interacting with objects often needs to reason about positions of and relations between objects; and as soon as the agent plans its actions to solve a task, it needs to consider the temporal aspect (e.g., what actions to perform over time). Spatio-temporal knowledge, however, is required beyond interacting with the physical world, and is also often transferred to the abstract world of concepts through analogies and metaphors (e.g., "a threat that is hanging over our heads"). As spatial and temporal reasoning is ubiquitous, different attempts have been made to integrate this into AI systems. In the area of knowledge representation, spatial and temporal reasoning has been largely limited to modeling objects and relations and developing reasoning methods to verify statements about objects and relations. On the other hand, neural network researchers have tried to teach models to learn spatial relations from data with limited reasoning capabilities. Bridging the gap between these two approaches in a mutually beneficial way could allow us to tackle many complex real-world problems, such as natural language processing, visual question answering, and semantic image segmentation. In this chapter, we view this integration problem from the perspective of Neuro-Symbolic AI. Specifically, we propose a synergy between logical reasoning and machine learning that will be grounded on spatial and temporal knowledge. Describing some successful applications, remaining challenges, and evaluation datasets pertaining to this direction is the main topic of this contribution.
Knowing Earlier what Right Means to You: A Comprehensive VQA Dataset for Grounding Relative Directions via Multi-Task Learning
Jul 06, 2022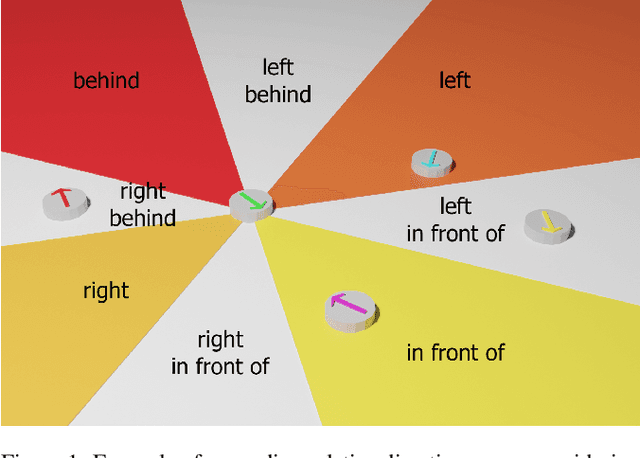
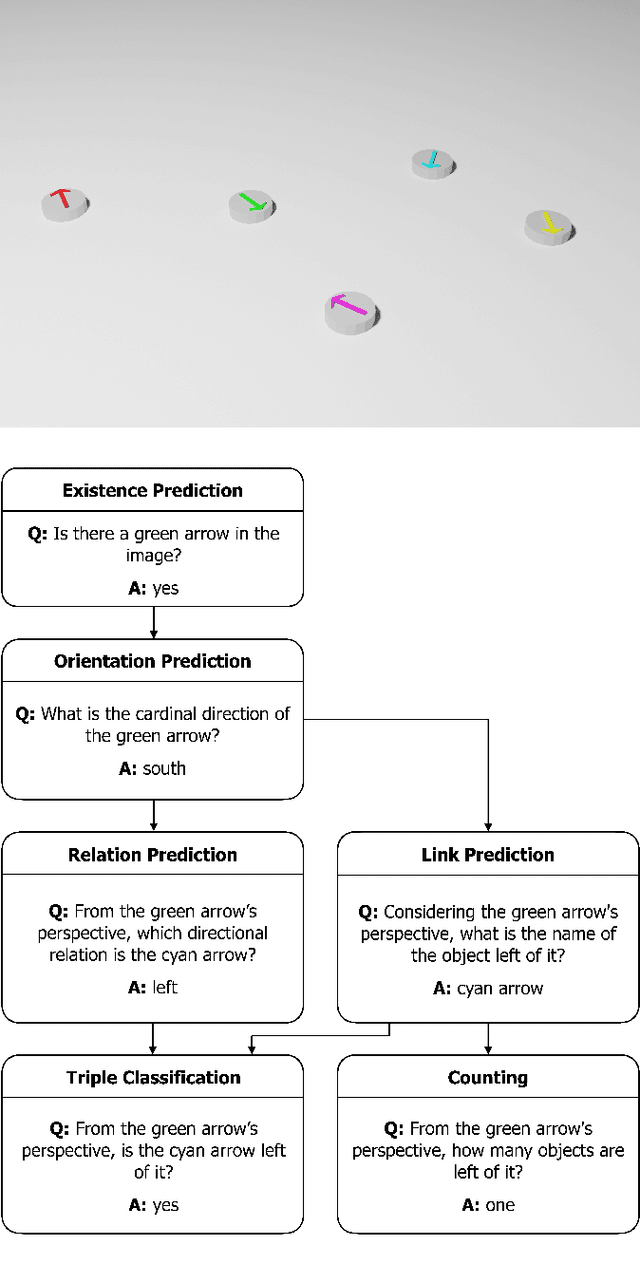

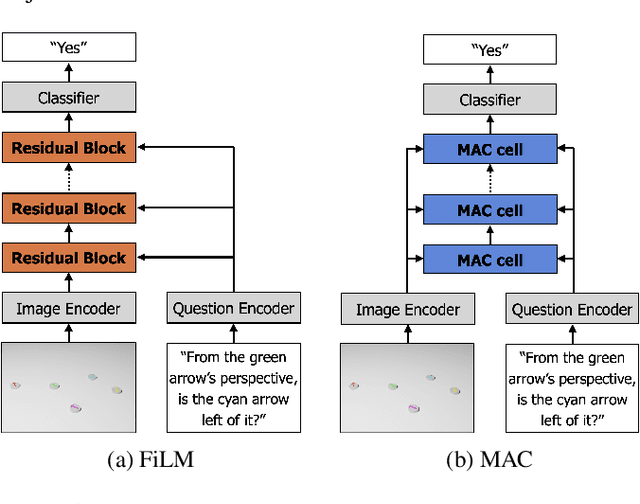
Spatial reasoning poses a particular challenge for intelligent agents and is at the same time a prerequisite for their successful interaction and communication in the physical world. One such reasoning task is to describe the position of a target object with respect to the intrinsic orientation of some reference object via relative directions. In this paper, we introduce GRiD-A-3D, a novel diagnostic visual question-answering (VQA) dataset based on abstract objects. Our dataset allows for a fine-grained analysis of end-to-end VQA models' capabilities to ground relative directions. At the same time, model training requires considerably fewer computational resources compared with existing datasets, yet yields a comparable or even higher performance. Along with the new dataset, we provide a thorough evaluation based on two widely known end-to-end VQA architectures trained on GRiD-A-3D. We demonstrate that within a few epochs, the subtasks required to reason over relative directions, such as recognizing and locating objects in a scene and estimating their intrinsic orientations, are learned in the order in which relative directions are intuitively processed.
What is Right for Me is Not Yet Right for You: A Dataset for Grounding Relative Directions via Multi-Task Learning
May 05, 2022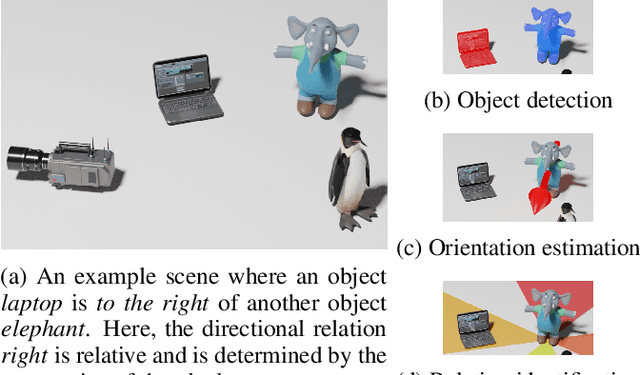


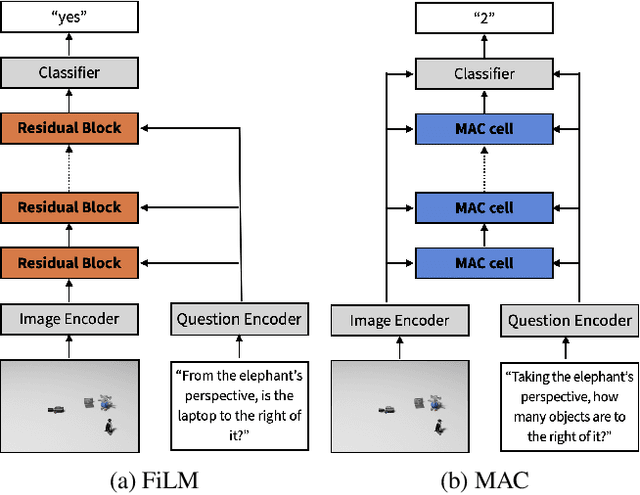
Understanding spatial relations is essential for intelligent agents to act and communicate in the physical world. Relative directions are spatial relations that describe the relative positions of target objects with regard to the intrinsic orientation of reference objects. Grounding relative directions is more difficult than grounding absolute directions because it not only requires a model to detect objects in the image and to identify spatial relation based on this information, but it also needs to recognize the orientation of objects and integrate this information into the reasoning process. We investigate the challenging problem of grounding relative directions with end-to-end neural networks. To this end, we provide GRiD-3D, a novel dataset that features relative directions and complements existing visual question answering (VQA) datasets, such as CLEVR, that involve only absolute directions. We also provide baselines for the dataset with two established end-to-end VQA models. Experimental evaluations show that answering questions on relative directions is feasible when questions in the dataset simulate the necessary subtasks for grounding relative directions. We discover that those subtasks are learned in an order that reflects the steps of an intuitive pipeline for processing relative directions.
Explain yourself! Effects of Explanations in Human-Robot Interaction
Apr 09, 2022

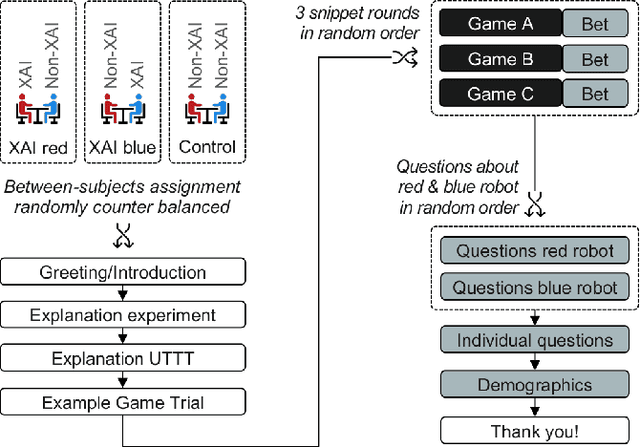
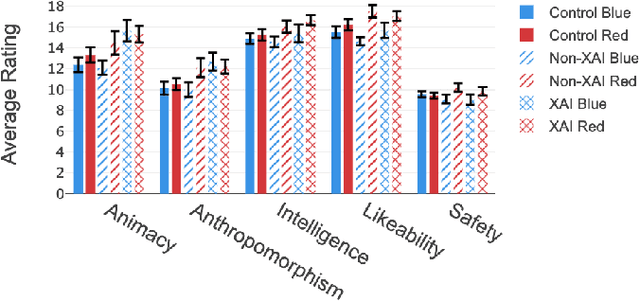
Recent developments in explainable artificial intelligence promise the potential to transform human-robot interaction: Explanations of robot decisions could affect user perceptions, justify their reliability, and increase trust. However, the effects on human perceptions of robots that explain their decisions have not been studied thoroughly. To analyze the effect of explainable robots, we conduct a study in which two simulated robots play a competitive board game. While one robot explains its moves, the other robot only announces them. Providing explanations for its actions was not sufficient to change the perceived competence, intelligence, likeability or safety ratings of the robot. However, the results show that the robot that explains its moves is perceived as more lively and human-like. This study demonstrates the need for and potential of explainable human-robot interaction and the wider assessment of its effects as a novel research direction.
DRILL: Dynamic Representations for Imbalanced Lifelong Learning
May 18, 2021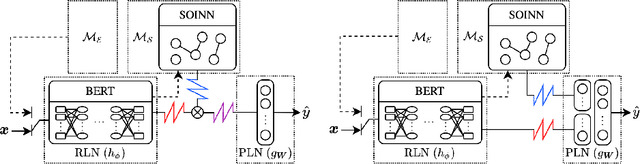
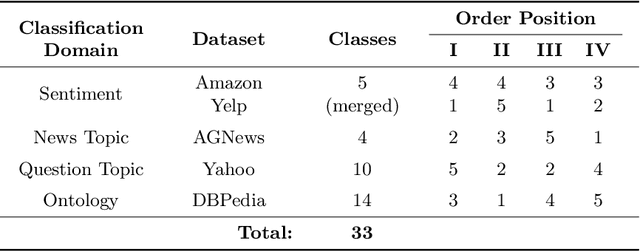
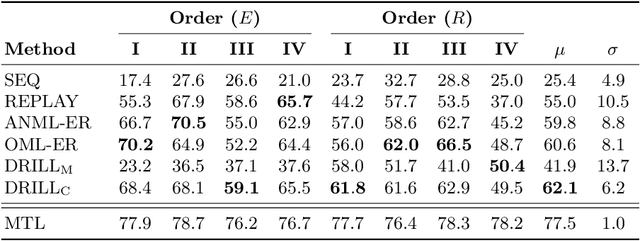
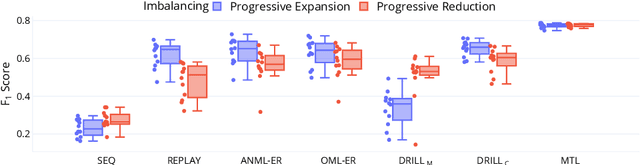
Continual or lifelong learning has been a long-standing challenge in machine learning to date, especially in natural language processing (NLP). Although state-of-the-art language models such as BERT have ushered in a new era in this field due to their outstanding performance in multitask learning scenarios, they suffer from forgetting when being exposed to a continuous stream of data with shifting data distributions. In this paper, we introduce DRILL, a novel continual learning architecture for open-domain text classification. DRILL leverages a biologically inspired self-organizing neural architecture to selectively gate latent language representations from BERT in a task-incremental manner. We demonstrate in our experiments that DRILL outperforms current methods in a realistic scenario of imbalanced, non-stationary data without prior knowledge about task boundaries. To the best of our knowledge, DRILL is the first of its kind to use a self-organizing neural architecture for open-domain lifelong learning in NLP.