 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing Earlier what Right Means to You: A Comprehensive VQA Dataset for Grounding Relative Directions via Multi-Task Learning
Paper and Code
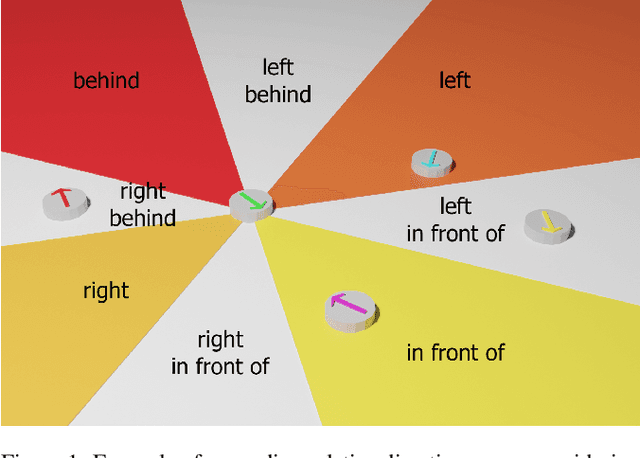
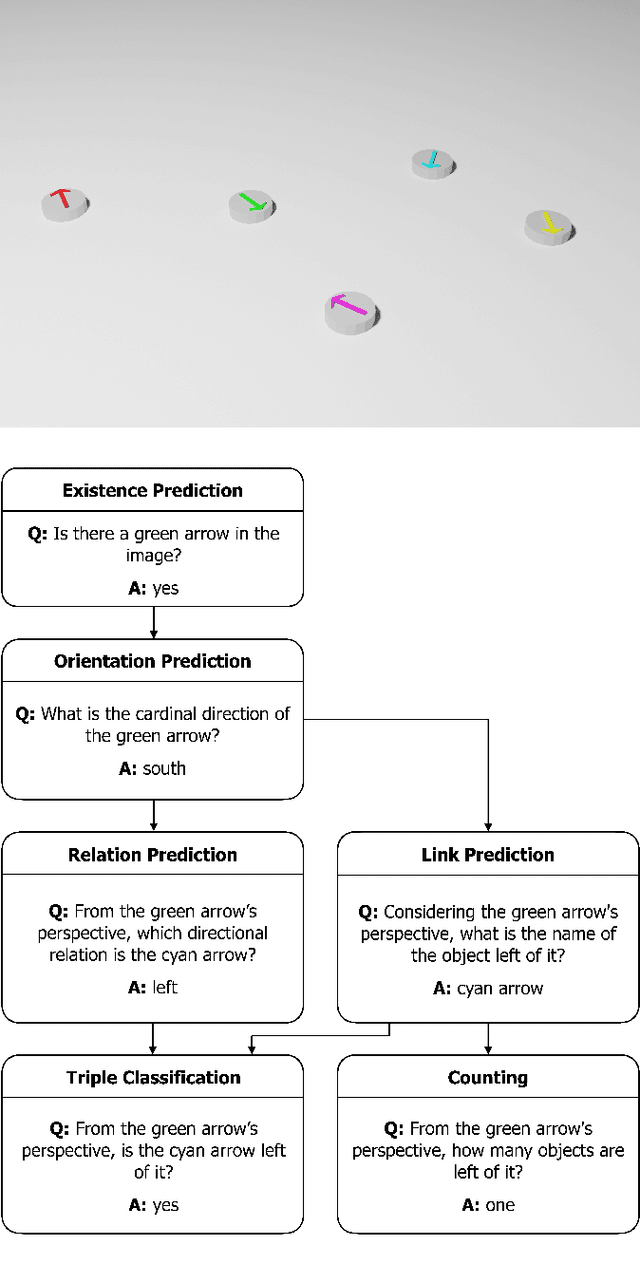

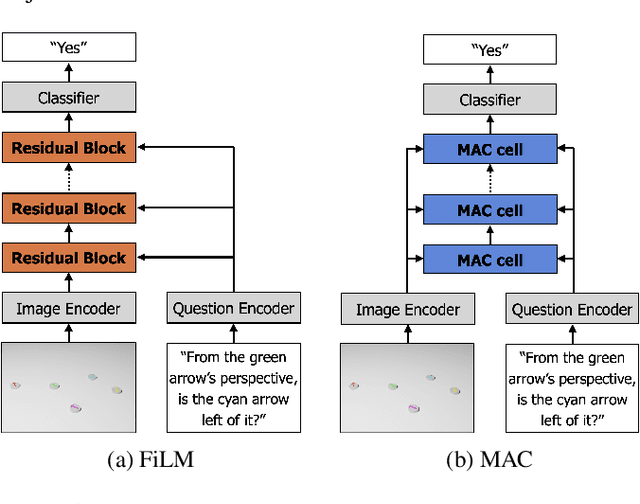
Spatial reasoning poses a particular challenge for intelligent agents and is at the same time a prerequisite for their successful interaction and communication in the physical world. One such reasoning task is to describe the position of a target object with respect to the intrinsic orientation of some reference object via relative directions. In this paper, we introduce GRiD-A-3D, a novel diagnostic visual question-answering (VQA) dataset based on abstract objects. Our dataset allows for a fine-grained analysis of end-to-end VQA models' capabilities to ground relative directions. At the same time, model training requires considerably fewer computational resources compared with existing datasets, yet yields a comparable or even higher performance. Along with the new dataset, we provide a thorough evaluation based on two widely known end-to-end VQA architectures trained on GRiD-A-3D. We demonstrate that within a few epochs, the subtasks required to reason over relative directions, such as recognizing and locating objects in a scene and estimating their intrinsic orientations, are learned in the order in which relative directions are intuitively processed.