 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-Domain Speech-to-Speech Conversion with Time-Frequency Consistency
May 19, 2020
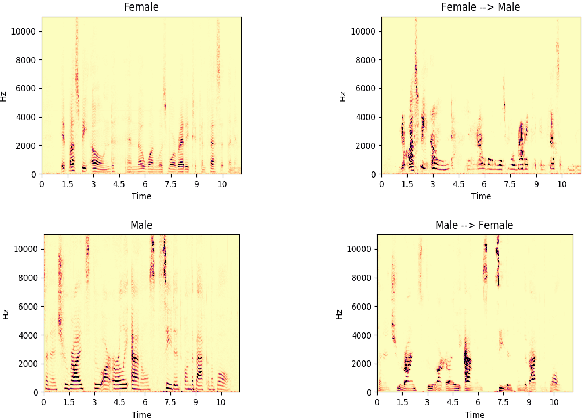

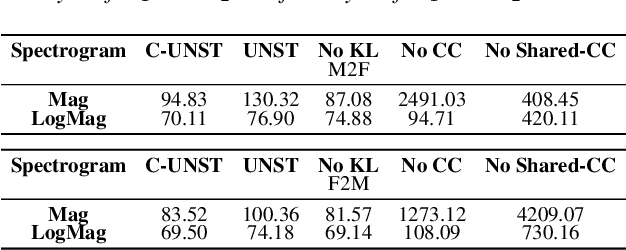
In recent years generative adversarial network (GAN) based models have been successfully applied for unsupervised speech-to-speech conversion.The rich compact harmonic view of the magnitude spectrogram is considered a suitable choice for training these models with audio data. To reconstruct the speech signal first a magnitude spectrogram is generated by the neural network, which is then utilized by methods like the Griffin-Lim algorithm to reconstruct a phase spectrogram. This procedure bears the problem that the generated magnitude spectrogram may not be consistent, which is required for finding a phase such that the full spectrogram has a natural-sounding speech waveform. In this work, we approach this problem by proposing a condition encouraging spectrogram consistency during the adversarial training procedure. We demonstrate our approach on the task of translating the voice of a male speaker to that of a female speaker, and vice versa. Our experimental results on the Librispeech corpus show that the model trained with the TF consistency provides a perceptually better quality of speech-to-speech conversion.
Utilizing Temporal Information in Deep Convolutional Network for Efficient Soccer Ball Detection and Tracking
Sep 06, 2019

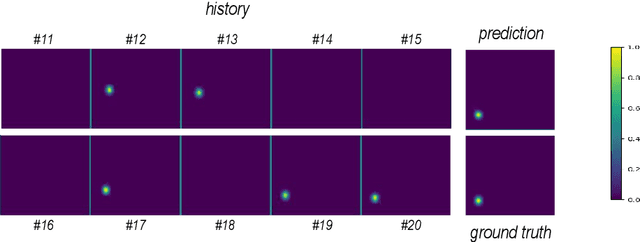
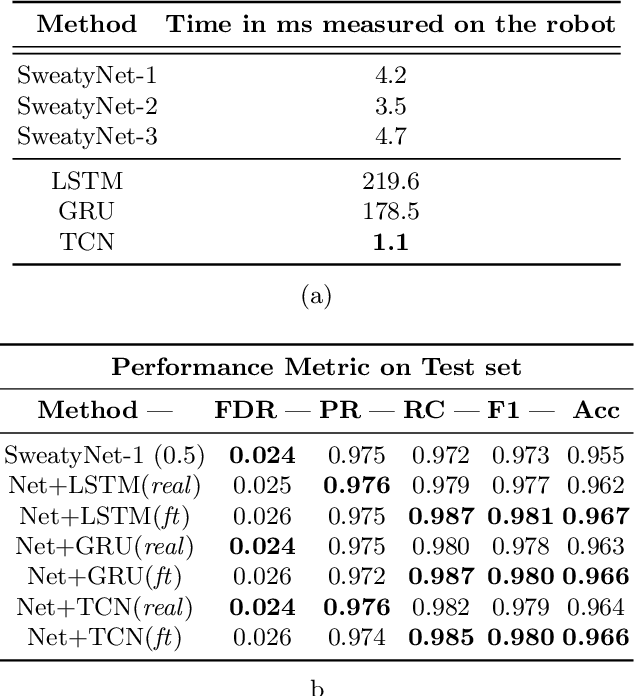
Soccer ball detection is identified as one of the critical challenges in the RoboCup competition. It requires an efficient vision system capable of handling the task of detection with high precision and recall and providing robust and low inference time. In this work, we present a novel convolutional neural network (CNN) approach to detect the soccer ball in an image sequence. In contrast to the existing methods where only the current frame or an image is used for the detection, we make use of the history of frames. Using history allows to efficiently track the ball in situations where the ball disappears or gets partially occluded in some of the frames. Our approach exploits spatio-temporal correlation and detects the ball based on the trajectory of its movements. We present our results with three convolutional methods, namely temporal convolutional networks (TCN), ConvLSTM, and ConvGRU. We first solve the detection task for an image using fully convolutional encoder-decoder architecture, and later, we use it as an input to our temporal models and jointly learn the detection task in sequences of images. We evaluate all our experiments on a novel dataset prepared as a part of this work. Furthermore, we present empirical results to support the effectiveness of using the history of the ball in challenging scenarios.
Incorporating Literals into Knowledge Graph Embeddings
May 25, 2018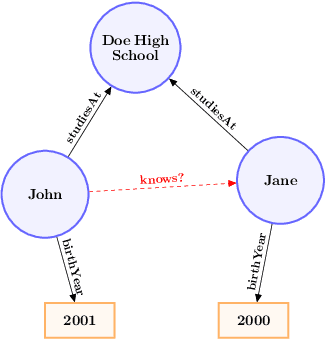
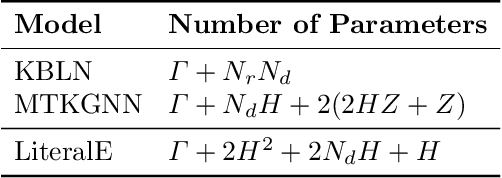
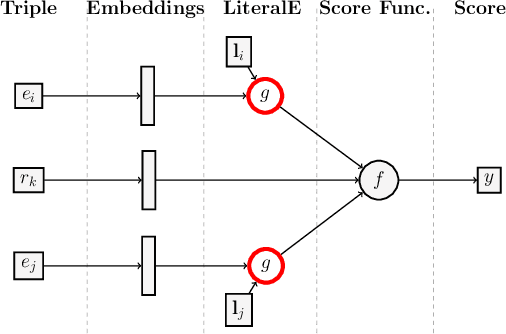
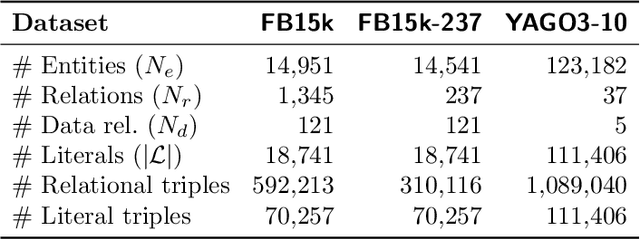
Knowledge graphs, on top of entities and their relationships, contain other important elements: literals. Literals encode interesting properties (e.g. the height) of entities that are not captured by links between entities alone. Most of the existing work on embedding (or latent feature) based knowledge graph analysis focuses mainly on the relations between entities. In this work, we study the effect of incorporating literal information into existing link prediction methods. Our approach, which we name LiteralE, is an extension that can be plugged into existing latent feature methods. LiteralE merges entity embeddings with their literal information using a learnable, parametrized function, such as a simple linear or nonlinear transformation, or a multilayer neural network. We extend several popular embedding models based on LiteralE and evaluate their performance on the task of link prediction. Despite its simplicity, LiteralE proves to be an effective way to incorporate literal information into existing embedding based methods, improving their performance on different standard datasets, which we augmented with their literals and provide as testbed for further research.