 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-Domain Speech-to-Speech Conversion with Time-Frequency Consistency
Paper and Code
May 19, 2020
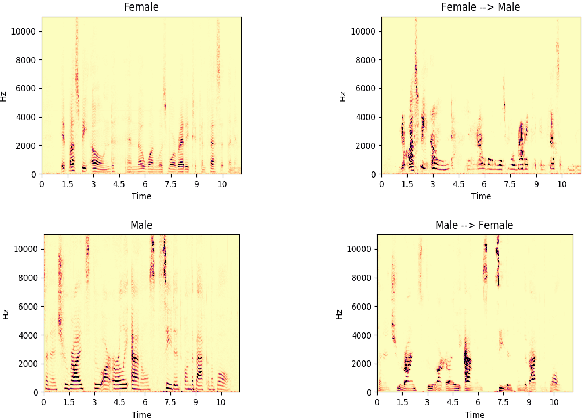

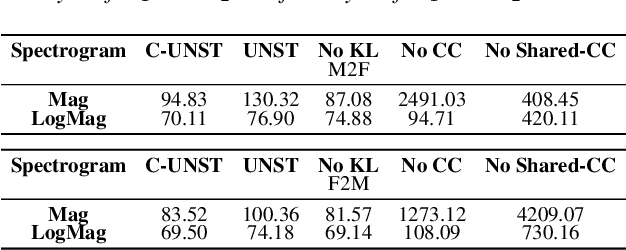
In recent years generative adversarial network (GAN) based models have been successfully applied for unsupervised speech-to-speech conversion.The rich compact harmonic view of the magnitude spectrogram is considered a suitable choice for training these models with audio data. To reconstruct the speech signal first a magnitude spectrogram is generated by the neural network, which is then utilized by methods like the Griffin-Lim algorithm to reconstruct a phase spectrogram. This procedure bears the problem that the generated magnitude spectrogram may not be consistent, which is required for finding a phase such that the full spectrogram has a natural-sounding speech waveform. In this work, we approach this problem by proposing a condition encouraging spectrogram consistency during the adversarial training procedure. We demonstrate our approach on the task of translating the voice of a male speaker to that of a female speaker, and vice versa. Our experimental results on the Librispeech corpus show that the model trained with the TF consistency provides a perceptually better quality of speech-to-speech conversion.