Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbout Test-time training for outlier detection
Paper and Code
Apr 04, 2024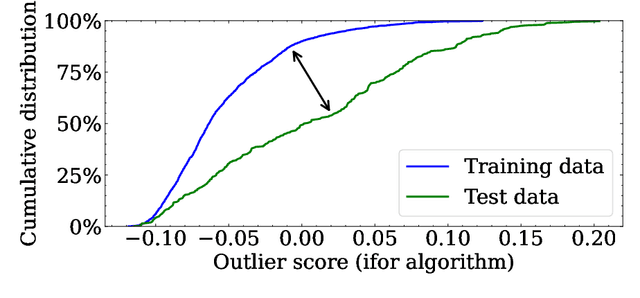
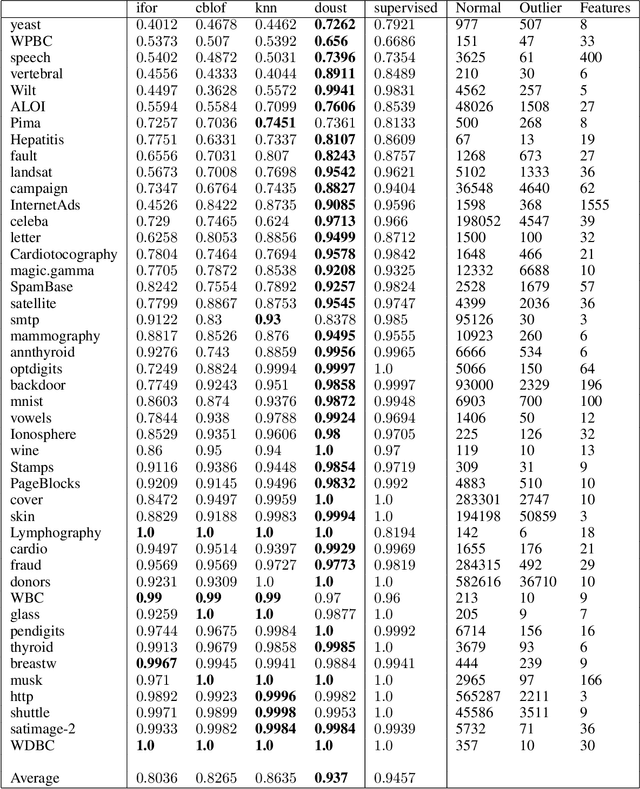

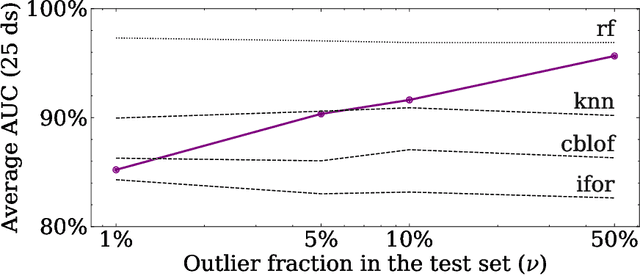
In this paper, we introduce DOUST, our method applying test-time training for outlier detection, significantly improving the detection performance. After thoroughly evaluating our algorithm on common benchmark datasets, we discuss a common problem and show that it disappears with a large enough test set. Thus, we conclude that under reasonable conditions, our algorithm can reach almost supervised performance even when no labeled outliers are given.
View paper on