 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRangeAD: Fast On-Model Anomaly Detection
Mar 18, 2026In practice, machine learning methods commonly require anomaly detection (AD) to filter inputs or detect distributional shifts. Typically, this is implemented by running a separate AD model alongside the primary model. However, this separation ignores the fact that the primary model already encodes substantial information about the target distribution. In this paper, we introduce On-Model AD, a setting for anomaly detection that explicitly leverages access to a related machine learning model. Within this setting, we propose RangeAD, an algorithm that utilizes neuron-wise output ranges derived from the primary model. RangeAD achieves superior performance even on high-dimensional tasks while incurring substantially lower inference costs. Our results demonstrate the potential of the On-Model AD setting as a practical framework for efficient anomaly detection.
FoMo X: Modular Explainability Signals for Outlier Detection Foundation Models
Mar 18, 2026Tabular foundation models, specifically Prior-Data Fitted Networks (PFNs), have revolutionized outlier detection (OD) by enabling unsupervised zero-shot adaptation to new datasets without training. However, despite their predictive power, these models typically function as opaque black boxes, outputting scalar outlier scores that lack the operational context required for safety-critical decision-making. Existing post-hoc explanation methods are often computationally prohibitive for real-time deployment or fail to capture the epistemic uncertainty inherent in zero-shot inference. In this work, we introduce FoMo-X, a modular framework that equips OD foundation models with intrinsic, lightweight diagnostic capabilities. We leverage the insight that the frozen embeddings of a pretrained PFN backbone already encode rich, context-conditioned relational information. FoMo-X attaches auxiliary diagnostic heads to these embeddings, trained offline using the same generative simulator prior as the backbone. This allows us to distill computationally expensive properties, such as Monte Carlo dropout based epistemic uncertainty, into a deterministic, single-pass inference. We instantiate FoMo-X with two novel heads: a Severity Head that discretizes deviations into interpretable risk tiers, and an Uncertainty Head that provides calibrated confidence measures. Extensive evaluation on synthetic and real-world benchmarks (ADBench) demonstrates that FoMo-X recovers ground-truth diagnostic signals with high fidelity and negligible inference overhead. By bridging the gap between foundation model performance and operational explainability, FoMo-X offers a scalable path toward trustworthy, zero-shot outlier detection.
Unsupervised Symbolic Anomaly Detection
Mar 18, 2026We propose SYRAN, an unsupervised anomaly detection method based on symbolic regression. Instead of encoding normal patterns in an opaque, high-dimensional model, our method learns an ensemble of human-readable equations that describe symbolic invariants: functions that are approximately constant on normal data. Deviations from these invariants yield anomaly scores, so that the detection logic is interpretable by construction, rather than via post-hoc explanation. Experimental results demonstrate that SYRAN is highly interpretable, providing equations that correspond to known scientific or medical relationships, and maintains strong anomaly detection performance comparable to that of state-of-the-art methods.
Towards Foundation Models for Consensus Rank Aggregation
Mar 16, 2026Aggregating a consensus ranking from multiple input rankings is a fundamental problem with applications in recommendation systems, search engines, job recruitment, and elections. Despite decades of research in consensus ranking aggregation, minimizing the Kemeny distance remains computationally intractable. Specifically, determining an optimal aggregation of rankings with respect to the Kemeny distance is an NP-hard problem, limiting its practical application to relatively small-scale instances. We propose the Kemeny Transformer, a novel Transformer-based algorithm trained via reinforcement learning to efficiently approximate the Kemeny optimal ranking. Experimental results demonstrate that our model outperforms classical majority-heuristic and Markov-chain approaches, achieving substantially faster inference than integer linear programming solvers. Our approach thus offers a practical, scalable alternative for real-world ranking-aggregation tasks.
MacrOData: New Benchmarks of Thousands of Datasets for Tabular Outlier Detection
Feb 10, 2026Quality benchmarks are essential for fairly and accurately tracking scientific progress and enabling practitioners to make informed methodological choices. Outlier detection (OD) on tabular data underpins numerous real-world applications, yet existing OD benchmarks remain limited. The prominent OD benchmark AdBench is the de facto standard in the literature, yet comprises only 57 datasets. In addition to other shortcomings discussed in this work, its small scale severely restricts diversity and statistical power. We introduce MacrOData, a large-scale benchmark suite for tabular OD comprising three carefully curated components: OddBench, with 790 datasets containing real-world semantic anomalies; OvrBench, with 856 datasets featuring real-world statistical outliers; and SynBench, with 800 synthetically generated datasets spanning diverse data priors and outlier archetypes. Owing to its scale and diversity, MacrOData enables comprehensive and statistically robust evaluation of tabular OD methods. Our benchmarks further satisfy several key desiderata: We provide standardized train/test splits for all datasets, public/private benchmark partitions with held-out test labels for the latter reserved toward an online leaderboard, and annotate our datasets with semantic metadata. We conduct extensive experiments across all benchmarks, evaluating a broad range of OD methods comprising classical, deep, and foundation models, over diverse hyperparameter configurations. We report detailed empirical findings, practical guidelines, as well as individual performances as references for future research. All benchmarks containing 2,446 datasets combined are open-sourced, along with a publicly accessible leaderboard hosted at https://huggingface.co/MacrOData-CMU.
Towards Evolutionary Optimization Using the Ising Model
Nov 19, 2025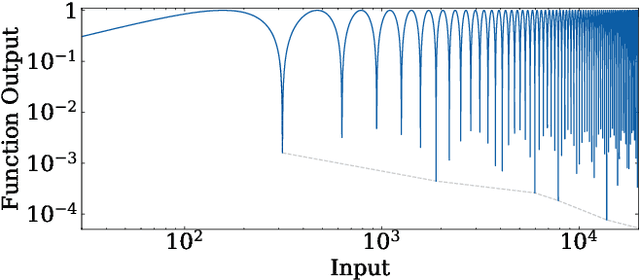
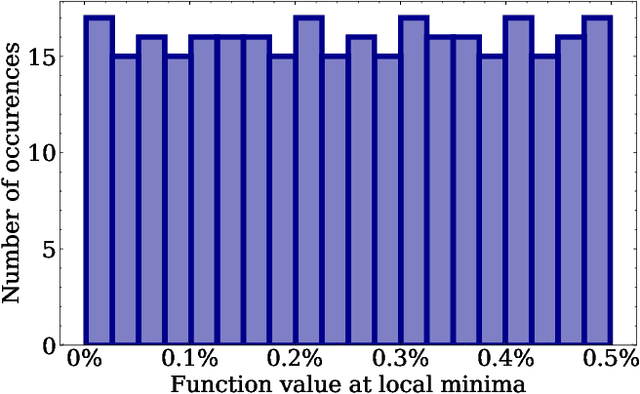
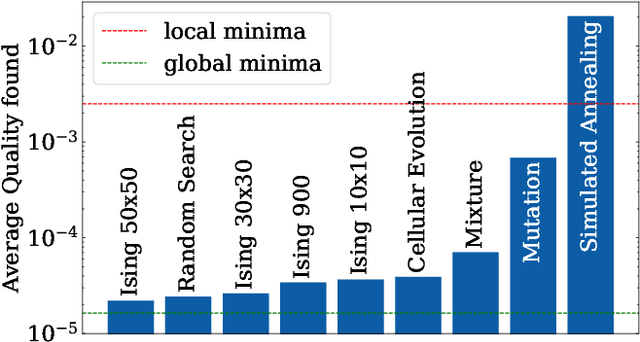
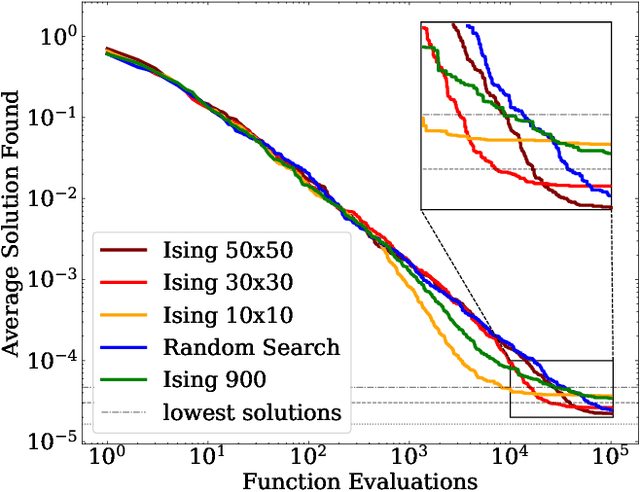
In this paper, we study the problem of finding the global minima of a given function. Specifically, we consider complicated functions with numerous local minima, as is often the case for real-world data mining losses. We do so by applying a model from theoretical physics to create an Ising model-based evolutionary optimization algorithm. Our algorithm creates stable regions of local optima and a high potential for improvement between these regions. This enables the accurate identification of global minima, surpassing comparable methods, and has promising applications to ensembles.
Rare anomalies require large datasets: About proving the existence of anomalies
Aug 13, 2025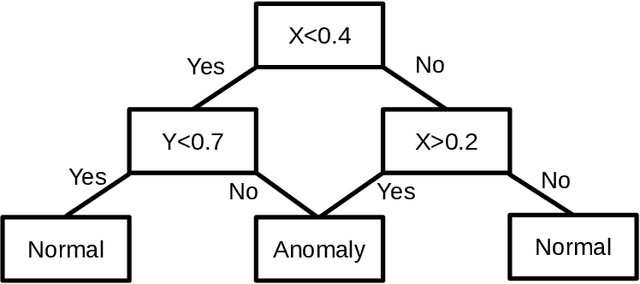
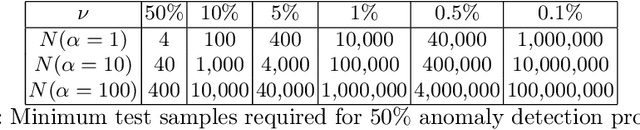
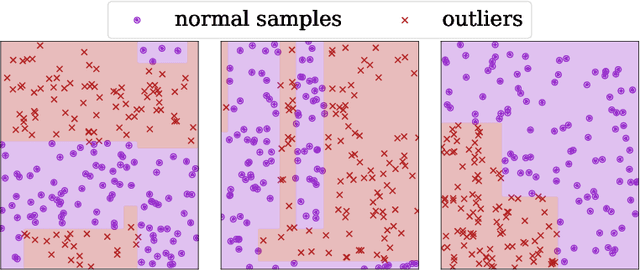
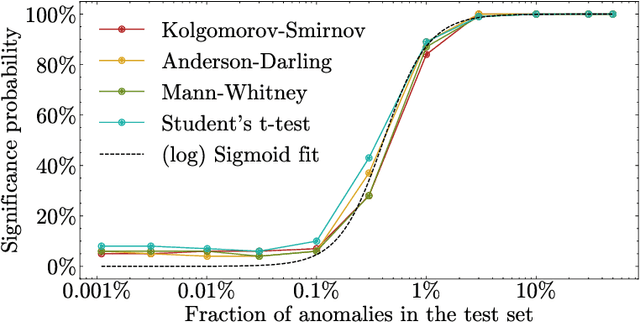
Detecting whether any anomalies exist within a dataset is crucial for effective anomaly detection, yet it remains surprisingly underexplored in anomaly detection literature. This paper presents a comprehensive study that addresses the fundamental question: When can we conclusively determine that anomalies are present? Through extensive experimentation involving over three million statistical tests across various anomaly detection tasks and algorithms, we identify a relationship between the dataset size, contamination rate, and an algorithm-dependent constant $ \alpha_{\text{algo}} $. Our results demonstrate that, for an unlabeled dataset of size $ N $ and contamination rate $ \nu $, the condition $ N \ge \frac{\alpha_{\text{algo}}}{\nu^2} $ represents a lower bound on the number of samples required to confirm anomaly existence. This threshold implies a limit to how rare anomalies can be before proving their existence becomes infeasible.
Polyra Swarms: A Shape-Based Approach to Machine Learning
Jun 16, 2025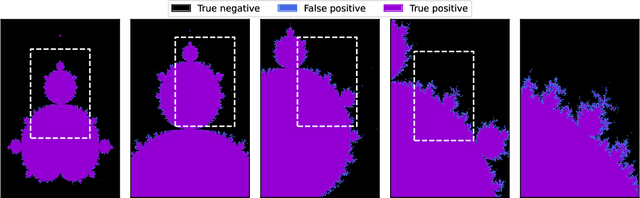



We propose Polyra Swarms, a novel machine-learning approach that approximates shapes instead of functions. Our method enables general-purpose learning with very low bias. In particular, we show that depending on the task, Polyra Swarms can be preferable compared to neural networks, especially for tasks like anomaly detection. We further introduce an automated abstraction mechanism that simplifies the complexity of a Polyra Swarm significantly, enhancing both their generalization and transparency. Since Polyra Swarms operate on fundamentally different principles than neural networks, they open up new research directions with distinct strengths and limitations.
Unsupervised Surrogate Anomaly Detection
Apr 29, 2025In this paper, we study unsupervised anomaly detection algorithms that learn a neural network representation, i.e. regular patterns of normal data, which anomalies are deviating from. Inspired by a similar concept in engineering, we refer to our methodology as surrogate anomaly detection. We formalize the concept of surrogate anomaly detection into a set of axioms required for optimal surrogate models and propose a new algorithm, named DEAN (Deep Ensemble ANomaly detection), designed to fulfill these criteria. We evaluate DEAN on 121 benchmark datasets, demonstrating its competitive performance against 19 existing methods, as well as the scalability and reliability of our method.
Exploring the Impact of Outlier Variability on Anomaly Detection Evaluation Metrics
Sep 24, 2024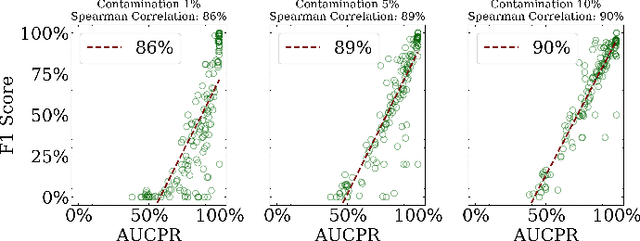
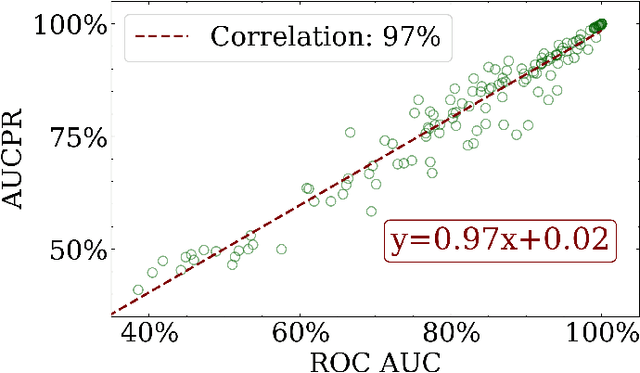
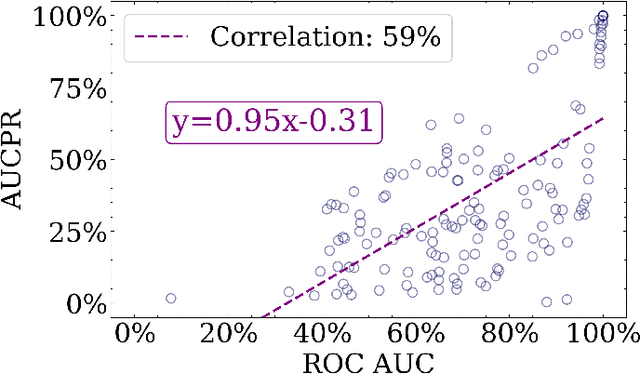
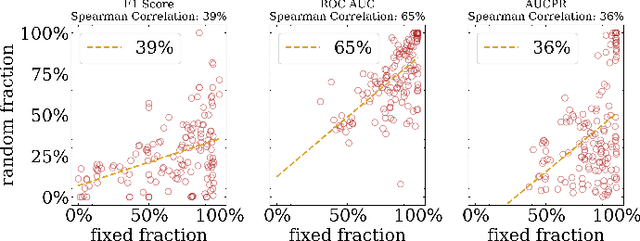
Anomaly detection is a dynamic field, in which the evaluation of models plays a critical role in understanding their effectiveness. The selection and interpretation of the evaluation metrics are pivotal, particularly in scenarios with varying amounts of anomalies. This study focuses on examining the behaviors of three widely used anomaly detection metrics under different conditions: F1 score, Receiver Operating Characteristic Area Under Curve (ROC AUC), and Precision-Recall Curve Area Under Curve (AUCPR). Our study critically analyzes the extent to which these metrics provide reliable and distinct insights into model performance, especially considering varying levels of outlier fractions and contamination thresholds in datasets. Through a comprehensive experimental setup involving widely recognized algorithms for anomaly detection, we present findings that challenge the conventional understanding of these metrics and reveal nuanced behaviors under varying conditions. We demonstrated that while the F1 score and AUCPR are sensitive to outlier fractions, the ROC AUC maintains consistency and is unaffected by such variability. Additionally, under conditions of a fixed outlier fraction in the test set, we observe an alignment between ROC AUC and AUCPR, indicating that the choice between these two metrics may be less critical in such scenarios. The results of our study contribute to a more refined understanding of metric selection and interpretation in anomaly detection, offering valuable insights for both researchers and practitioners in the field.