 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Model for Polarization Imaging on Projective Cameras
Nov 29, 2022The vast majority of Shape-from-Polarization (SfP) methods work under the oversimplified assumption of using orthographic cameras. Indeed, it is still not well understood how to project the Stokes vectors when the incoming rays are not orthogonal to the image plane. We try to answer this question presenting a geometric model describing how a general projective camera captures the light polarization state. Based on the optical properties of a tilted polarizer, our model is implemented as a pre-processing operation acting on raw images, followed by a per-pixel rotation of the reconstructed normal field. In this way, all the existing SfP methods assuming orthographic cameras can behave like they were designed for projective ones. Moreover, our model is consistent with state-of-the-art forward and inverse renderers (like Mitsuba3 and ART), intrinsically enforces physical constraints among the captured channels, and handles demosaicing of DoFP sensors. Experiments on existing and new datasets demonstrate the accuracy of the model when applied to commercially available polarimetric cameras.
Deep Demosaicing for Polarimetric Filter Array Cameras
Nov 24, 2022Polarisation Filter Array (PFA) cameras allow the analysis of light polarisation state in a simple and cost-effective manner. Such filter arrays work as the Bayer pattern for colour cameras, sharing similar advantages and drawbacks. Among the others, the raw image must be demosaiced considering the local variations of the PFA and the characteristics of the imaged scene. Non-linear effects, like the cross-talk among neighbouring pixels, are difficult to explicitly model and suggest the potential advantage of a data-driven learning approach. However, the PFA cannot be removed from the sensor, making it difficult to acquire the ground-truth polarization state for training. In this work we propose a novel CNN-based model which directly demosaics the raw camera image to a per-pixel Stokes vector. Our contribution is twofold. First, we propose a network architecture composed by a sequence of Mosaiced Convolutions operating coherently with the local arrangement of the different filters. Second, we introduce a new method, employing a consumer LCD screen, to effectively acquire real-world data for training. The process is designed to be invariant by monitor gamma and external lighting conditions. We extensively compared our method against algorithmic and learning-based demosaicing techniques, obtaining a consistently lower error especially in terms of polarisation angle.
On-the-go Reflectance Transformation Imaging with Ordinary Smartphones
Oct 18, 2022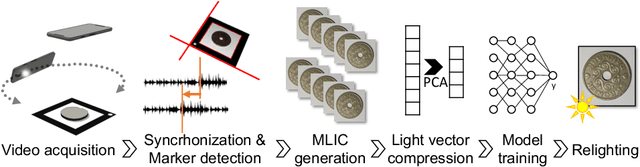
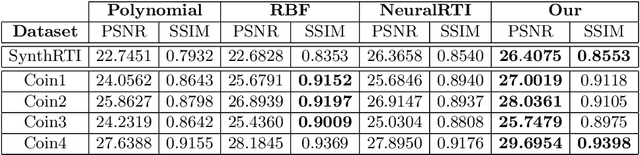
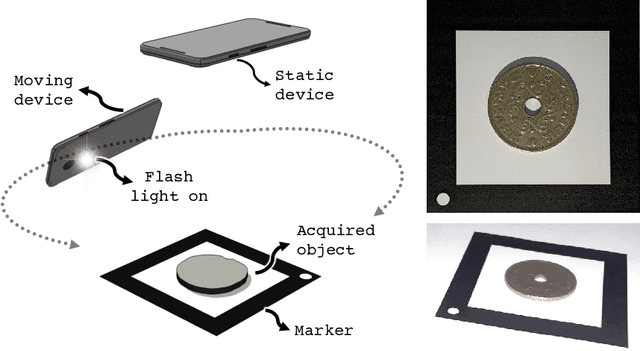
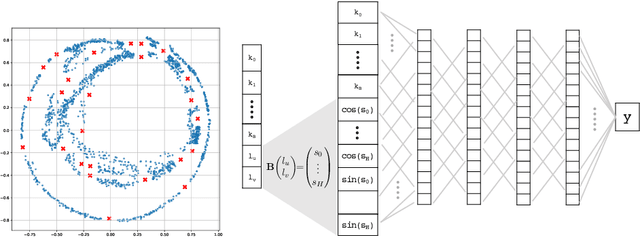
Reflectance Transformation Imaging (RTI) is a popular technique that allows the recovery of per-pixel reflectance information by capturing an object under different light conditions. This can be later used to reveal surface details and interactively relight the subject. Such process, however, typically requires dedicated hardware setups to recover the light direction from multiple locations, making the process tedious when performed outside the lab. We propose a novel RTI method that can be carried out by recording videos with two ordinary smartphones. The flash led-light of one device is used to illuminate the subject while the other captures the reflectance. Since the led is mounted close to the camera lenses, we can infer the light direction for thousands of images by freely moving the illuminating device while observing a fiducial marker surrounding the subject. To deal with such amount of data, we propose a neural relighting model that reconstructs object appearance for arbitrary light directions from extremely compact reflectance distribution data compressed via Principal Components Analysis (PCA). Experiments shows that the proposed technique can be easily performed on the field with a resulting RTI model that can outperform state-of-the-art approaches involving dedicated hardware setups.