 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-form merging of parameter-efficient modules for Federated Continual Learning
Oct 23, 2024



Model merging has emerged as a crucial technique in Deep Learning, enabling the integration of multiple models into a unified system while preserving performance and scalability. In this respect, the compositional properties of low-rank adaptation techniques (e.g., LoRA) have proven beneficial, as simple averaging LoRA modules yields a single model that mostly integrates the capabilities of all individual modules. Building on LoRA, we take a step further by imposing that the merged model matches the responses of all learned modules. Solving this objective in closed form yields an indeterminate system with A and B as unknown variables, indicating the existence of infinitely many closed-form solutions. To address this challenge, we introduce LoRM, an alternating optimization strategy that trains one LoRA matrix at a time. This allows solving for each unknown variable individually, thus finding a unique solution. We apply our proposed methodology to Federated Class-Incremental Learning (FCIL), ensuring alignment of model responses both between clients and across tasks. Our method demonstrates state-of-the-art performance across a range of FCIL scenarios.
Mask and Compress: Efficient Skeleton-based Action Recognition in Continual Learning
Jul 01, 2024



The use of skeletal data allows deep learning models to perform action recognition efficiently and effectively. Herein, we believe that exploring this problem within the context of Continual Learning is crucial. While numerous studies focus on skeleton-based action recognition from a traditional offline perspective, only a handful venture into online approaches. In this respect, we introduce CHARON (Continual Human Action Recognition On skeletoNs), which maintains consistent performance while operating within an efficient framework. Through techniques like uniform sampling, interpolation, and a memory-efficient training stage based on masking, we achieve improved recognition accuracy while minimizing computational overhead. Our experiments on Split NTU-60 and the proposed Split NTU-120 datasets demonstrate that CHARON sets a new benchmark in this domain. The code is available at https://github.com/Sperimental3/CHARON.
Is Retain Set All You Need in Machine Unlearning? Restoring Performance of Unlearned Models with Out-Of-Distribution Images
Apr 19, 2024



In this paper, we introduce Selective-distillation for Class and Architecture-agnostic unleaRning (SCAR), a novel approximate unlearning method. SCAR efficiently eliminates specific information while preserving the model's test accuracy without using a retain set, which is a key component in state-of-the-art approximate unlearning algorithms. Our approach utilizes a modified Mahalanobis distance to guide the unlearning of the feature vectors of the instances to be forgotten, aligning them to the nearest wrong class distribution. Moreover, we propose a distillation-trick mechanism that distills the knowledge of the original model into the unlearning model with out-of-distribution images for retaining the original model's test performance without using any retain set. Importantly, we propose a self-forget version of SCAR that unlearns without having access to the forget set. We experimentally verified the effectiveness of our method, on three public datasets, comparing it with state-of-the-art methods. Our method obtains performance higher than methods that operate without the retain set and comparable w.r.t the best methods that rely on the retain set.
MIND: Multi-Task Incremental Network Distillation
Dec 20, 2023
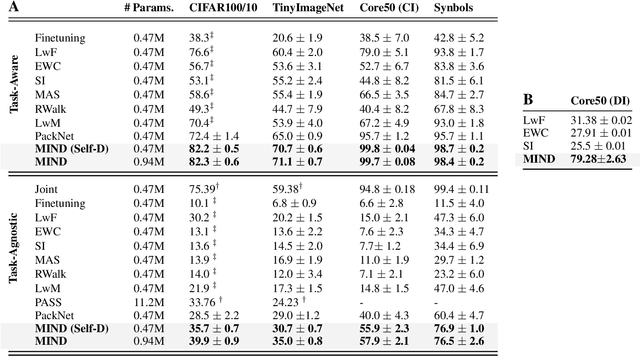


The recent surge of pervasive devices that generate dynamic data streams has underscored the necessity for learning systems to adapt continually to data distributional shifts. To tackle this challenge, the research community has put forth a spectrum of methodologies, including the demanding pursuit of class-incremental learning without replay data. In this study, we present MIND, a parameter isolation method that aims to significantly enhance the performance of replay-free solutions and achieve state-of-the-art results on several widely studied datasets. Our approach introduces two main contributions: two alternative distillation procedures that significantly improve the efficiency of MIND increasing the accumulated knowledge of each sub-network, and the optimization of the BachNorm layers across tasks inside the sub-networks. Overall, MIND outperforms all the state-of-the-art methods for rehearsal-free Class-Incremental learning (with an increment in classification accuracy of approx. +6% on CIFAR-100/10 and +10% on TinyImageNet/10) reaching up to approx. +40% accuracy in Domain-Incremental scenarios. Moreover, we ablated each contribution to demonstrate its impact on performance improvement. Our results showcase the superior performance of MIND indicating its potential for addressing the challenges posed by Class-incremental and Domain-Incremental learning in resource-constrained environments.
DUCK: Distance-based Unlearning via Centroid Kinematics
Dec 04, 2023



Machine Unlearning is rising as a new field, driven by the pressing necessity of ensuring privacy in modern artificial intelligence models. This technique primarily aims to eradicate any residual influence of a specific subset of data from the knowledge acquired by a neural model during its training. This work introduces a novel unlearning algorithm, denoted as Distance-based Unlearning via Centroid Kinematics (DUCK), which employs metric learning to guide the removal of samples matching the nearest incorrect centroid in the embedding space. Evaluation of the algorithm's performance is conducted across various benchmark datasets in two distinct scenarios, class removal, and homogeneous sampling removal, obtaining state-of-the-art performance. We introduce a novel metric, called Adaptive Unlearning Score (AUS), encompassing not only the efficacy of the unlearning process in forgetting target data but also quantifying the performance loss relative to the original model. Moreover, we propose a novel membership inference attack to assess the algorithm's capacity to erase previously acquired knowledge, designed to be adaptable to future methodologies.