 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Class-Attention with Cascaded Feature Drift Compensation for Exemplar-free Continual Learning of Vision Transformers
Nov 22, 2022In this paper we propose a new method for exemplar-free class incremental training of ViTs. The main challenge of exemplar-free continual learning is maintaining plasticity of the learner without causing catastrophic forgetting of previously learned tasks. This is often achieved via exemplar replay which can help recalibrate previous task classifiers to the feature drift which occurs when learning new tasks. Exemplar replay, however, comes at the cost of retaining samples from previous tasks which for some applications may not be possible. To address the problem of continual ViT training, we first propose gated class-attention to minimize the drift in the final ViT transformer block. This mask-based gating is applied to class-attention mechanism of the last transformer block and strongly regulates the weights crucial for previous tasks. Secondly, we propose a new method of feature drift compensation that accommodates feature drift in the backbone when learning new tasks. The combination of gated class-attention and cascaded feature drift compensation allows for plasticity towards new tasks while limiting forgetting of previous ones. Extensive experiments performed on CIFAR-100, Tiny-ImageNet and ImageNet100 demonstrate that our method outperforms existing exemplar-free state-of-the-art methods without the need to store any representative exemplars of past tasks.
Explaining Image Enhancement Black-Box Methods through a Path Planning Based Algorithm
Jul 14, 2022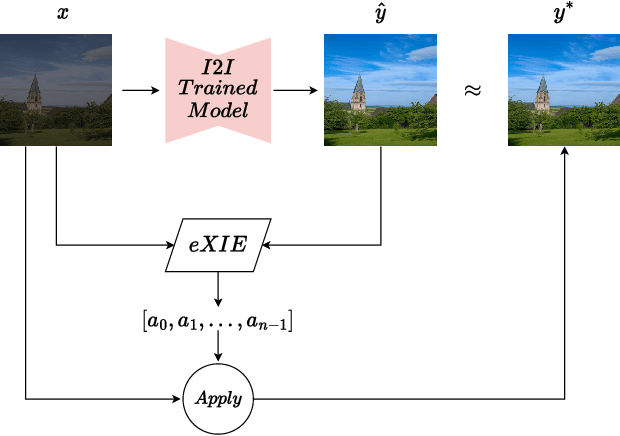
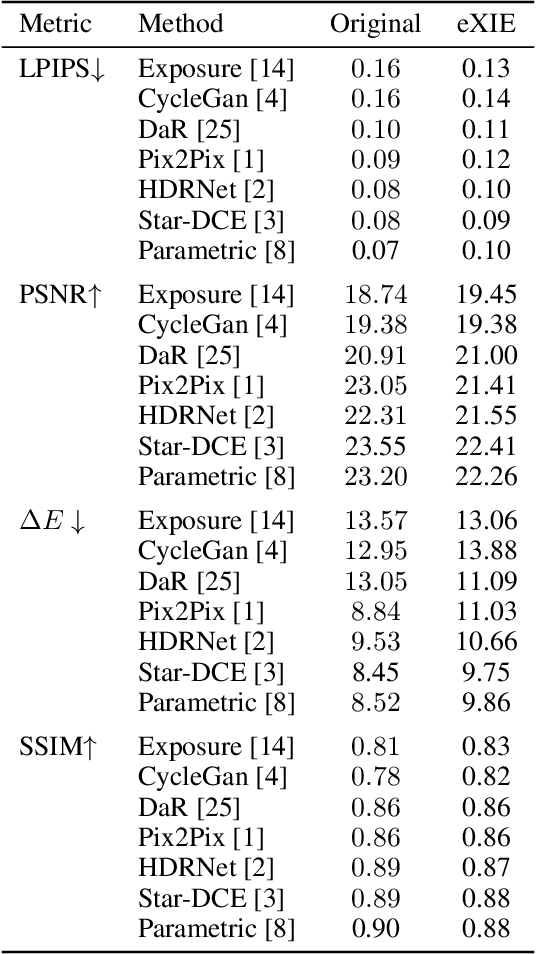
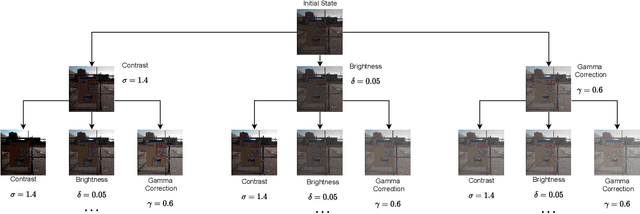
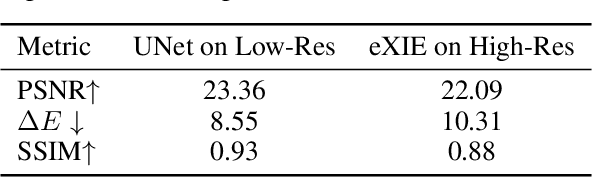
Nowadays, image-to-image translation methods, are the state of the art for the enhancement of natural images. Even if they usually show high performance in terms of accuracy, they often suffer from several limitations such as the generation of artifacts and the scalability to high resolutions. Moreover, their main drawback is the completely black-box approach that does not allow to provide the final user with any insight about the enhancement processes applied. In this paper we present a path planning algorithm which provides a step-by-step explanation of the output produced by state of the art enhancement methods, overcoming black-box limitation. This algorithm, called eXIE, uses a variant of the A* algorithm to emulate the enhancement process of another method through the application of an equivalent sequence of enhancing operators. We applied eXIE to explain the output of several state-of-the-art models trained on the Five-K dataset, obtaining sequences of enhancing operators able to produce very similar results in terms of performance and overcoming the huge limitation of poor interpretability of the best performing algorithms.
Offset equivariant networks and their applications
Jul 01, 2022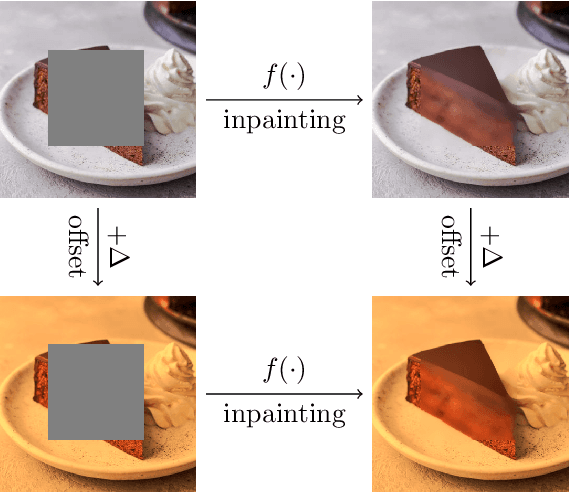
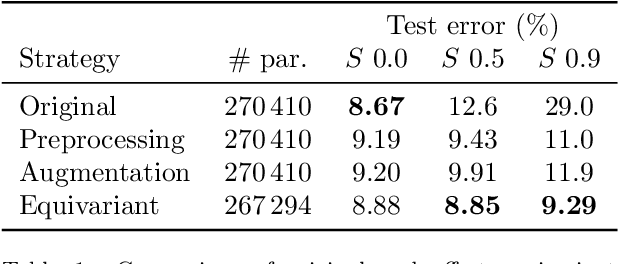

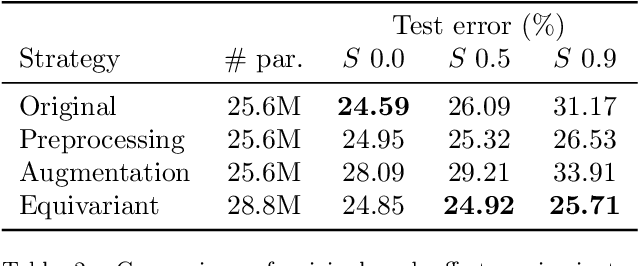
In this paper we present a framework for the design and implementation of offset equivariant networks, that is, neural networks that preserve in their output uniform increments in the input. In a suitable color space this kind of networks achieves equivariance with respect to the photometric transformations that characterize changes in the lighting conditions. We verified the framework on three different problems: image recognition, illuminant estimation, and image inpainting. Our experiments show that the performance of offset equivariant networks are comparable to those in the state of the art on regular data. Differently from conventional networks, however, equivariant networks do behave consistently well when the color of the illuminant changes.
* 13 pages
TreEnhance: An Automatic Tree-Search Based Method for Low-Light Image Enhancement
May 25, 2022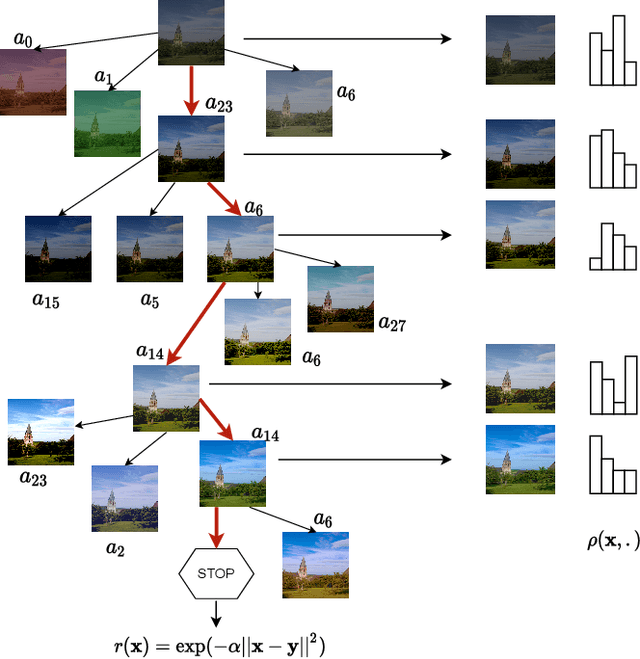
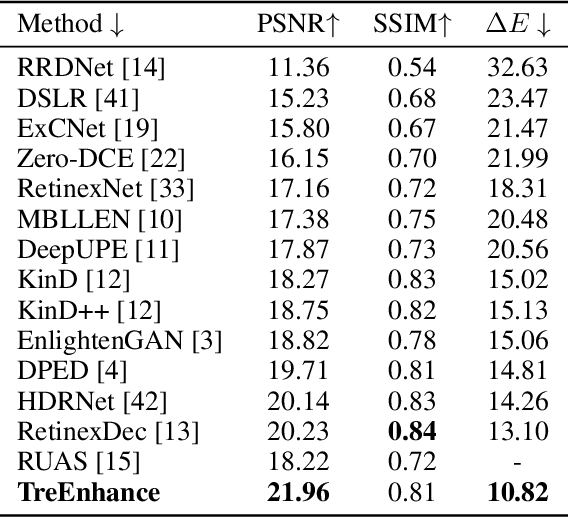

In this paper we present TreEnhance, an automatic method for low-light image enhancement capable of improving the quality of digital images. The method combines tree search theory, and in particular the Monte Carlo Tree Search (MCTS) algorithm, with deep reinforcement learning. Given as input a low-light image, TreEnhance produces as output its enhanced version together with the sequence of image editing operations used to obtain it. The method repeatedly alternates two main phases. In the generation phase a modified version of MCTS explores the space of image editing operations and selects the most promising sequence. In the optimization phase the parameters of a neural network, implementing the enhancement policy, are updated. After training, two different inference solutions are proposed for the enhancement of new images: one is based on MCTS and is more accurate but more time and memory consuming; the other directly applies the learned policy and is faster but slightly less precise. Unlike other methods from the state of the art, TreEnhance does not pose any constraint on the image resolution and can be used in a variety of scenarios with minimal tuning. We tested the method on two datasets: the Low-Light dataset and the Adobe Five-K dataset obtaining good results from both a qualitative and a quantitative point of view.
Single and Multiple Illuminant Estimation Using Convolutional Neural Networks
Dec 11, 2015
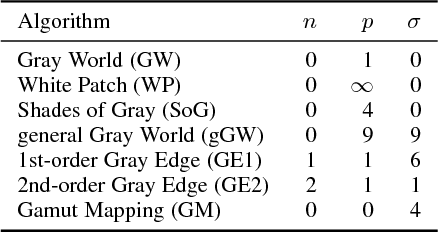

In this paper we present a method for the estimation of the color of the illuminant in RAW images. The method includes a Convolutional Neural Network that has been specially designed to produce multiple local estimates. A multiple illuminant detector determines whether or not the local outputs of the network must be aggregated into a single estimate. We evaluated our method on standard datasets with single and multiple illuminants, obtaining lower estimation errors with respect to those obtained by other general purpose methods in the state of the art.
CURL: Co-trained Unsupervised Representation Learning for Image Classification
Sep 11, 2015

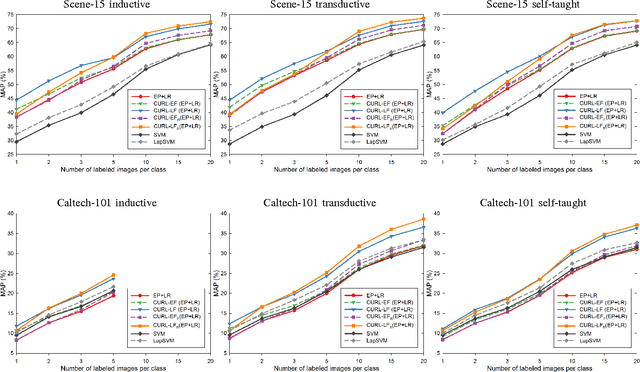

In this paper we propose a strategy for semi-supervised image classification that leverages unsupervised representation learning and co-training. The strategy, that is called CURL from Co-trained Unsupervised Representation Learning, iteratively builds two classifiers on two different views of the data. The two views correspond to different representations learned from both labeled and unlabeled data and differ in the fusion scheme used to combine the image features. To assess the performance of our proposal, we conducted several experiments on widely used data sets for scene and object recognition. We considered three scenarios (inductive, transductive and self-taught learning) that differ in the strategy followed to exploit the unlabeled data. As image features we considered a combination of GIST, PHOG, and LBP as well as features extracted from a Convolutional Neural Network. Moreover, two embodiments of CURL are investigated: one using Ensemble Projection as unsupervised representation learning coupled with Logistic Regression, and one based on LapSVM. The results show that CURL clearly outperforms other supervised and semi-supervised learning methods in the state of the art.
Remote sensing image classification exploiting multiple kernel learning
Sep 01, 2015
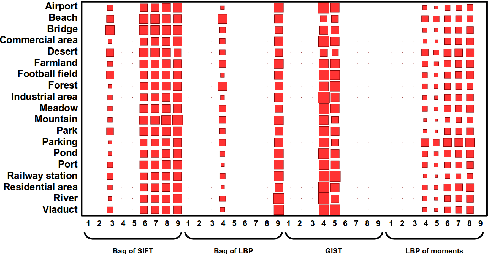
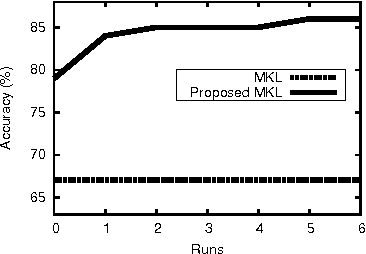
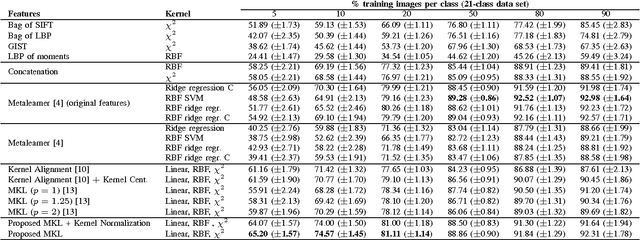
We propose a strategy for land use classification which exploits Multiple Kernel Learning (MKL) to automatically determine a suitable combination of a set of features without requiring any heuristic knowledge about the classification task. We present a novel procedure that allows MKL to achieve good performance in the case of small training sets. Experimental results on publicly available datasets demonstrate the feasibility of the proposed approach.
Evaluating color texture descriptors under large variations of controlled lighting conditions
Aug 05, 2015
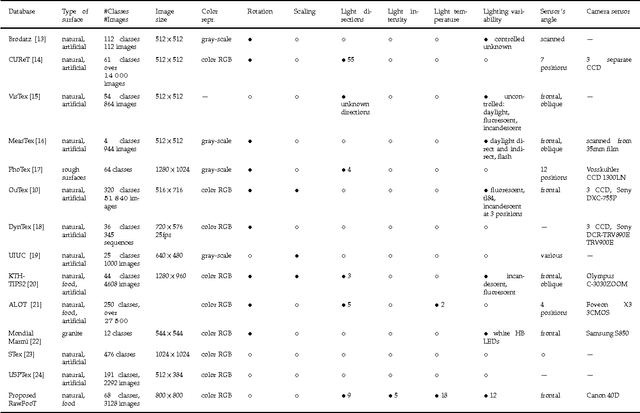

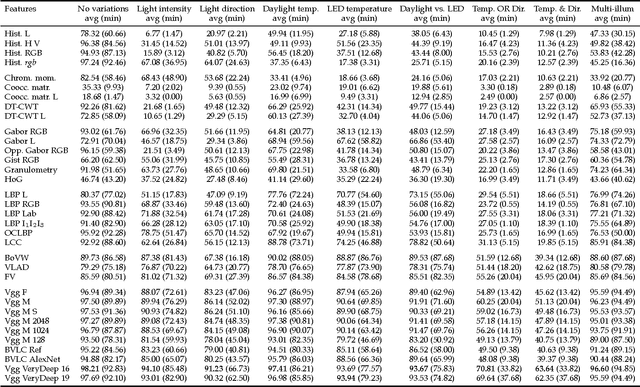
The recognition of color texture under varying lighting conditions is still an open issue. Several features have been proposed for this purpose, ranging from traditional statistical descriptors to features extracted with neural networks. Still, it is not completely clear under what circumstances a feature performs better than the others. In this paper we report an extensive comparison of old and new texture features, with and without a color normalization step, with a particular focus on how they are affected by small and large variation in the lighting conditions. The evaluation is performed on a new texture database including 68 samples of raw food acquired under 46 conditions that present single and combined variations of light color, direction and intensity. The database allows to systematically investigate the robustness of texture descriptors across a large range of variations of imaging conditions.
Color Constancy Using CNNs
Apr 17, 2015
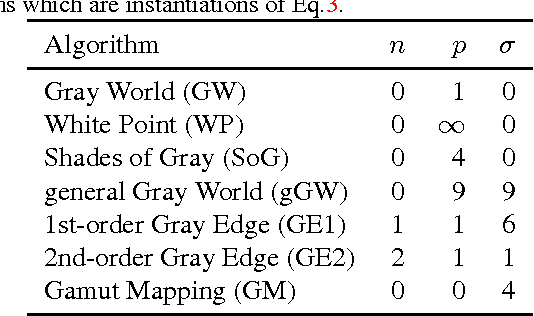

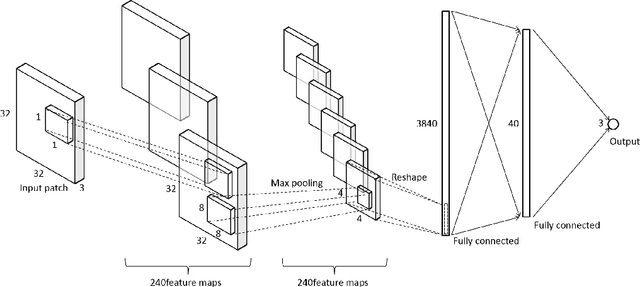
In this work we describe a Convolutional Neural Network (CNN) to accurately predict the scene illumination. Taking image patches as input, the CNN works in the spatial domain without using hand-crafted features that are employed by most previous methods. The network consists of one convolutional layer with max pooling, one fully connected layer and three output nodes. Within the network structure, feature learning and regression are integrated into one optimization process, which leads to a more effective model for estimating scene illumination. This approach achieves state-of-the-art performance on a standard dataset of RAW images. Preliminary experiments on images with spatially varying illumination demonstrate the stability of the local illuminant estimation ability of our CNN.