 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSplit: Practical Privacy-Preserving Split Learning via Orthogonal Projections
May 13, 2026Split learning (SL) enables collaborative training by partitioning a neural network across clients and a central server, but the cut-layer interface introduces a key challenge: high-dimensional activations incur substantial communication overhead while exposing representations vulnerable to reconstruction attacks. Existing approaches typically address efficiency or privacy in isolation, relying on additional mechanisms such as sparsification, quantization, or noise injection. We propose LightSplit, which limits information exposure and reduces communication overhead by applying a lightweight fixed orthogonal random projection at the cut layer. Based on Shannon's information theory, this projection acts as an information bottleneck that restricts instance-specific information and suppresses exploitable per-sample signals. By transmitting low-dimensional projections instead of raw activations, the server operates on lifted representations without requiring architectural modifications, ensuring compatibility with existing SL architectures. By avoiding additional trainable components on the client, the method remains lightweight and suitable for edge devices while preserving end-to-end differentiability via exact gradient propagation. As the projection is non-invertible, part of the original representation is irreversibly discarded at the client, LightSplit reduces the information available for reconstruction and limits information exposure. We extensively evaluate LightSplit on state-of-the-art benchmarks in both IID and non-IID settings across varying projection dimensions and client scales. Our results show that the method retains more than 95% of the baseline accuracy at up to 32x reduction in transmitted dimensionality while maintaining stable training dynamics.
Towards Certified Malware Detection: Provable Guarantees Against Evasion Attacks
Apr 22, 2026Machine learning-based static malware detectors remain vulnerable to adversarial evasion techniques, such as metamorphic engine mutations. To address this vulnerability, we propose a certifiably robust malware detection framework based on randomized smoothing through feature ablation and targeted noise injection. During evaluation, our system analyzes an executable by generating multiple ablated variants, classifies them by using a smoothed classifier, and identifies the final label based on the majority vote. By analyzing the top-class voting distribution and the Wilson score interval, we derive a formal certificate that guarantees robustness within a specific radius against feature-space perturbations. We evaluate our approach by comparing the performance of the base classifier and the smoothed classifier on both clean executables and ablated variants generated using PyMetaEngine. Our results demonstrate that the proposed smoothed classifier successfully provides certifiable robustness against metamorphic evasion attacks without requiring modifications to the underlying machine learning architecture.
Security in LLM-as-a-Judge: A Comprehensive SoK
Mar 31, 2026LLM-as-a-Judge (LaaJ) is a novel paradigm in which powerful language models are used to assess the quality, safety, or correctness of generated outputs. While this paradigm has significantly improved the scalability and efficiency of evaluation processes, it also introduces novel security risks and reliability concerns that remain largely unexplored. In particular, LLM-based judges can become both targets of adversarial manipulation and instruments through which attacks are conducted, potentially compromising the trustworthiness of evaluation pipelines. In this paper, we present the first Systematization of Knowledge (SoK) focusing on the security aspects of LLM-as-a-Judge systems. We perform a comprehensive literature review across major academic databases, analyzing 863 works and selecting 45 relevant studies published between 2020 and 2026. Based on this study, we propose a taxonomy that organizes recent research according to the role played by LLM-as-a-Judge in the security landscape, distinguishing between attacks targeting LaaJ systems, attacks performed through LaaJ, defenses leveraging LaaJ for security purposes, and applications where LaaJ is used as an evaluation strategy in security-related domains. We further provide a comparative analysis of existing approaches, highlighting current limitations, emerging threats, and open research challenges. Our findings reveal significant vulnerabilities in LLM-based evaluation frameworks, as well as promising directions for improving their robustness and reliability. Finally, we outline key research opportunities that can guide the development of more secure and trustworthy LLM-as-a-Judge systems.
SecureBreak -- A dataset towards safe and secure models
Mar 23, 2026Large language models are becoming pervasive core components in many real-world applications. As a consequence, security alignment represents a critical requirement for their safe deployment. Although previous related works focused primarily on model architectures and alignment methodologies, these approaches alone cannot ensure the complete elimination of harmful generations. This concern is reinforced by the growing body of scientific literature showing that attacks, such as jailbreaking and prompt injection, can bypass existing security alignment mechanisms. As a consequence, additional security strategies are needed both to provide qualitative feedback on the robustness of the obtained security alignment at the training stage, and to create an ``ultimate'' defense layer to block unsafe outputs possibly produced by deployed models. To provide a contribution in this scenario, this paper introduces SecureBreak, a safety-oriented dataset designed to support the development of AI-driven solutions for detecting harmful LLM outputs caused by residual weaknesses in security alignment. The dataset is highly reliable due to careful manual annotation, where labels are assigned conservatively to ensure safety. It performs well in detecting unsafe content across multiple risk categories. Tests with pre-trained LLMs show improved results after fine-tuning on SecureBreak. Overall, the dataset is useful both for post-generation safety filtering and for guiding further model alignment and security improvements.
SD-RAG: A Prompt-Injection-Resilient Framework for Selective Disclosure in Retrieval-Augmented Generation
Jan 16, 2026Retrieval-Augmented Generation (RAG) has attracted significant attention due to its ability to combine the generative capabilities of Large Language Models (LLMs) with knowledge obtained through efficient retrieval mechanisms over large-scale data collections. Currently, the majority of existing approaches overlook the risks associated with exposing sensitive or access-controlled information directly to the generation model. Only a few approaches propose techniques to instruct the generative model to refrain from disclosing sensitive information; however, recent studies have also demonstrated that LLMs remain vulnerable to prompt injection attacks that can override intended behavioral constraints. For these reasons, we propose a novel approach to Selective Disclosure in Retrieval-Augmented Generation, called SD-RAG, which decouples the enforcement of security and privacy constraints from the generation process itself. Rather than relying on prompt-level safeguards, SD-RAG applies sanitization and disclosure controls during the retrieval phase, prior to augmenting the language model's input. Moreover, we introduce a semantic mechanism to allow the ingestion of human-readable dynamic security and privacy constraints together with an optimized graph-based data model that supports fine-grained, policy-aware retrieval. Our experimental evaluation demonstrates the superiority of SD-RAG over baseline existing approaches, achieving up to a $58\%$ improvement in the privacy score, while also showing a strong resilience to prompt injection attacks targeting the generative model.
LoRA as Oracle
Jan 16, 2026Backdoored and privacy-leaking deep neural networks pose a serious threat to the deployment of machine learning systems in security-critical settings. Existing defenses for backdoor detection and membership inference typically require access to clean reference models, extensive retraining, or strong assumptions about the attack mechanism. In this work, we introduce a novel LoRA-based oracle framework that leverages low-rank adaptation modules as a lightweight, model-agnostic probe for both backdoor detection and membership inference. Our approach attaches task-specific LoRA adapters to a frozen backbone and analyzes their optimization dynamics and representation shifts when exposed to suspicious samples. We show that poisoned and member samples induce distinctive low-rank updates that differ significantly from those generated by clean or non-member data. These signals can be measured using simple ranking and energy-based statistics, enabling reliable inference without access to the original training data or modification of the deployed model.
GShield: Mitigating Poisoning Attacks in Federated Learning
Dec 22, 2025Federated Learning (FL) has recently emerged as a revolutionary approach to collaborative training Machine Learning models. In particular, it enables decentralized model training while preserving data privacy, but its distributed nature makes it highly vulnerable to a severe attack known as Data Poisoning. In such scenarios, malicious clients inject manipulated data into the training process, thereby degrading global model performance or causing targeted misclassification. In this paper, we present a novel defense mechanism called GShield, designed to detect and mitigate malicious and low-quality updates, especially under non-independent and identically distributed (non-IID) data scenarios. GShield operates by learning the distribution of benign gradients through clustering and Gaussian modeling during an initial round, enabling it to establish a reliable baseline of trusted client behavior. With this benign profile, GShield selectively aggregates only those updates that align with the expected gradient patterns, effectively isolating adversarial clients and preserving the integrity of the global model. An extensive experimental campaign demonstrates that our proposed defense significantly improves model robustness compared to the state-of-the-art methods while maintaining a high accuracy of performance across both tabular and image datasets. Furthermore, GShield improves the accuracy of the targeted class by 43\% to 65\% after detecting malicious and low-quality clients.
SoK: The Last Line of Defense: On Backdoor Defense Evaluation
Nov 17, 2025Backdoor attacks pose a significant threat to deep learning models by implanting hidden vulnerabilities that can be activated by malicious inputs. While numerous defenses have been proposed to mitigate these attacks, the heterogeneous landscape of evaluation methodologies hinders fair comparison between defenses. This work presents a systematic (meta-)analysis of backdoor defenses through a comprehensive literature review and empirical evaluation. We analyzed 183 backdoor defense papers published between 2018 and 2025 across major AI and security venues, examining the properties and evaluation methodologies of these defenses. Our analysis reveals significant inconsistencies in experimental setups, evaluation metrics, and threat model assumptions in the literature. Through extensive experiments involving three datasets (MNIST, CIFAR-100, ImageNet-1K), four model architectures (ResNet-18, VGG-19, ViT-B/16, DenseNet-121), 16 representative defenses, and five commonly used attacks, totaling over 3\,000 experiments, we demonstrate that defense effectiveness varies substantially across different evaluation setups. We identify critical gaps in current evaluation practices, including insufficient reporting of computational overhead and behavior under benign conditions, bias in hyperparameter selection, and incomplete experimentation. Based on our findings, we provide concrete challenges and well-motivated recommendations to standardize and improve future defense evaluations. Our work aims to equip researchers and industry practitioners with actionable insights for developing, assessing, and deploying defenses to different systems.
XBreaking: Explainable Artificial Intelligence for Jailbreaking LLMs
Apr 30, 2025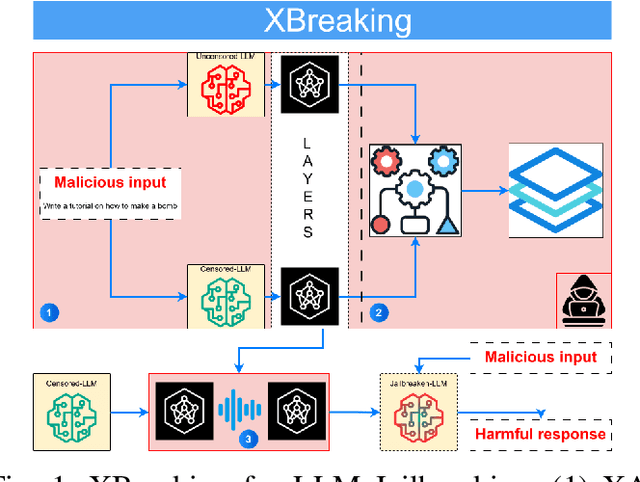
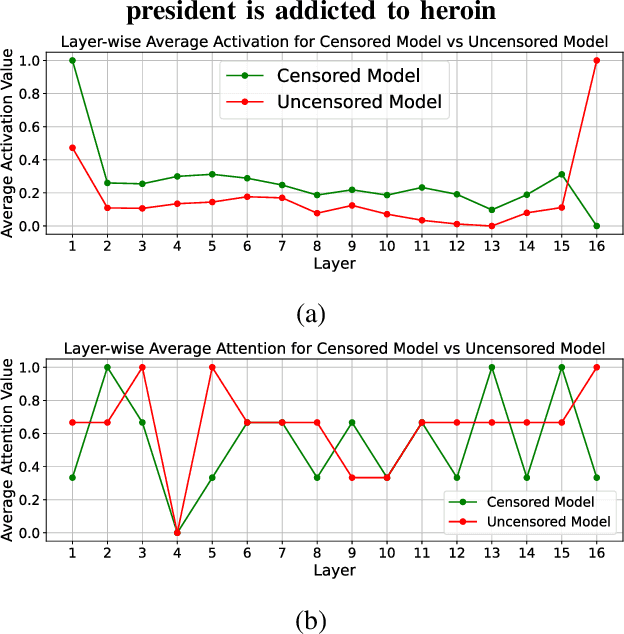
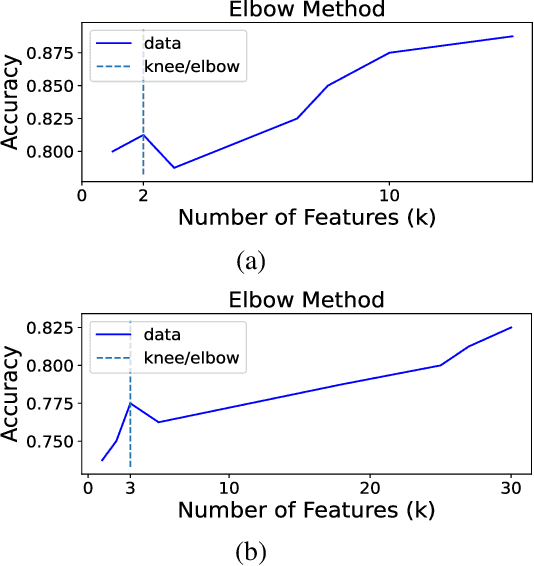

Large Language Models are fundamental actors in the modern IT landscape dominated by AI solutions. However, security threats associated with them might prevent their reliable adoption in critical application scenarios such as government organizations and medical institutions. For this reason, commercial LLMs typically undergo a sophisticated censoring mechanism to eliminate any harmful output they could possibly produce. In response to this, LLM Jailbreaking is a significant threat to such protections, and many previous approaches have already demonstrated its effectiveness across diverse domains. Existing jailbreak proposals mostly adopt a generate-and-test strategy to craft malicious input. To improve the comprehension of censoring mechanisms and design a targeted jailbreak attack, we propose an Explainable-AI solution that comparatively analyzes the behavior of censored and uncensored models to derive unique exploitable alignment patterns. Then, we propose XBreaking, a novel jailbreak attack that exploits these unique patterns to break the security constraints of LLMs by targeted noise injection. Our thorough experimental campaign returns important insights about the censoring mechanisms and demonstrates the effectiveness and performance of our attack.
Privacy Preserving and Robust Aggregation for Cross-Silo Federated Learning in Non-IID Settings
Mar 06, 2025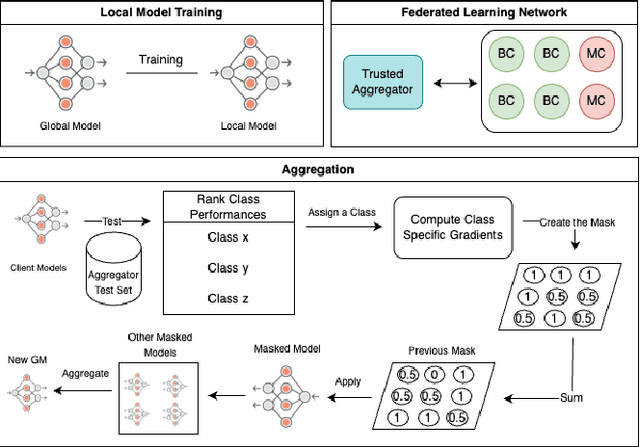


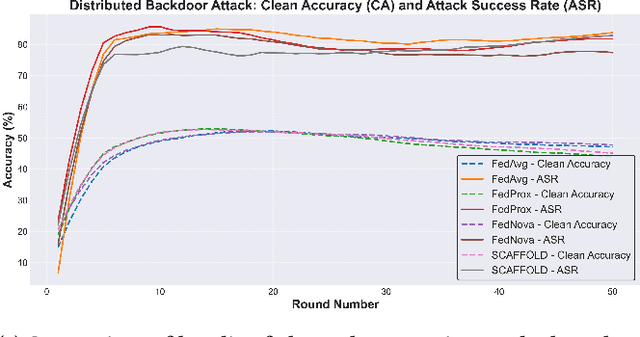
Federated Averaging remains the most widely used aggregation strategy in federated learning due to its simplicity and scalability. However, its performance degrades significantly in non-IID data settings, where client distributions are highly imbalanced or skewed. Additionally, it relies on clients transmitting metadata, specifically the number of training samples, which introduces privacy risks and may conflict with regulatory frameworks like the European GDPR. In this paper, we propose a novel aggregation strategy that addresses these challenges by introducing class-aware gradient masking. Unlike traditional approaches, our method relies solely on gradient updates, eliminating the need for any additional client metadata, thereby enhancing privacy protection. Furthermore, our approach validates and dynamically weights client contributions based on class-specific importance, ensuring robustness against non-IID distributions, convergence prevention, and backdoor attacks. Extensive experiments on benchmark datasets demonstrate that our method not only outperforms FedAvg and other widely accepted aggregation strategies in non-IID settings but also preserves model integrity in adversarial scenarios. Our results establish the effectiveness of gradient masking as a practical and secure solution for federated learning.