 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Preserving and Robust Aggregation for Cross-Silo Federated Learning in Non-IID Settings
Mar 06, 2025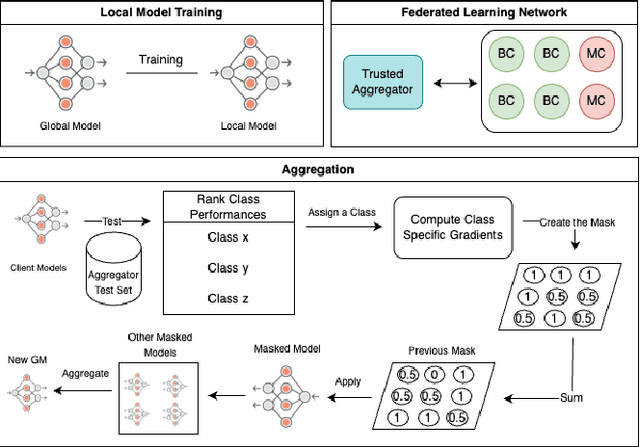


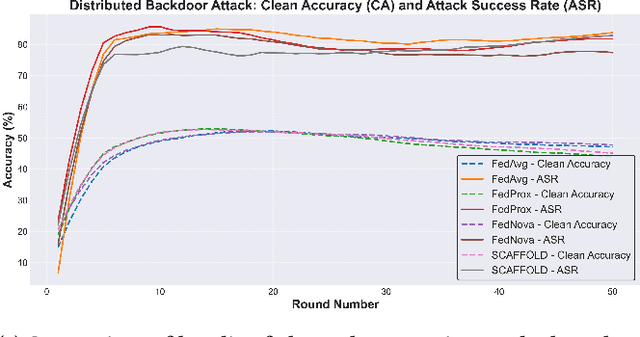
Federated Averaging remains the most widely used aggregation strategy in federated learning due to its simplicity and scalability. However, its performance degrades significantly in non-IID data settings, where client distributions are highly imbalanced or skewed. Additionally, it relies on clients transmitting metadata, specifically the number of training samples, which introduces privacy risks and may conflict with regulatory frameworks like the European GDPR. In this paper, we propose a novel aggregation strategy that addresses these challenges by introducing class-aware gradient masking. Unlike traditional approaches, our method relies solely on gradient updates, eliminating the need for any additional client metadata, thereby enhancing privacy protection. Furthermore, our approach validates and dynamically weights client contributions based on class-specific importance, ensuring robustness against non-IID distributions, convergence prevention, and backdoor attacks. Extensive experiments on benchmark datasets demonstrate that our method not only outperforms FedAvg and other widely accepted aggregation strategies in non-IID settings but also preserves model integrity in adversarial scenarios. Our results establish the effectiveness of gradient masking as a practical and secure solution for federated learning.
Secure Federated Data Distillation
Feb 19, 2025
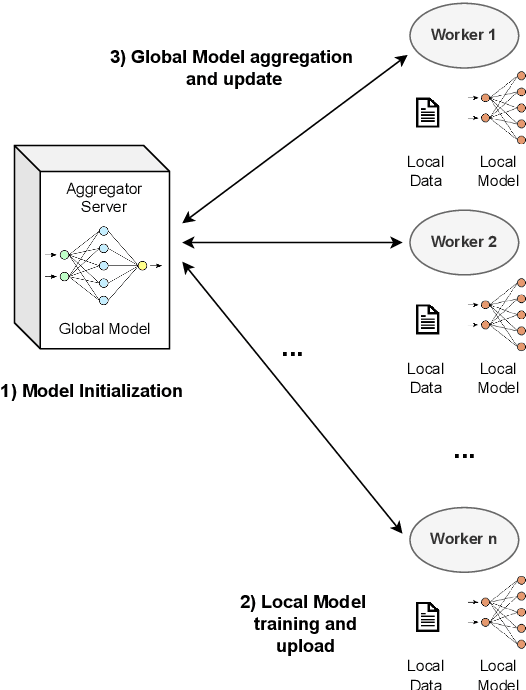
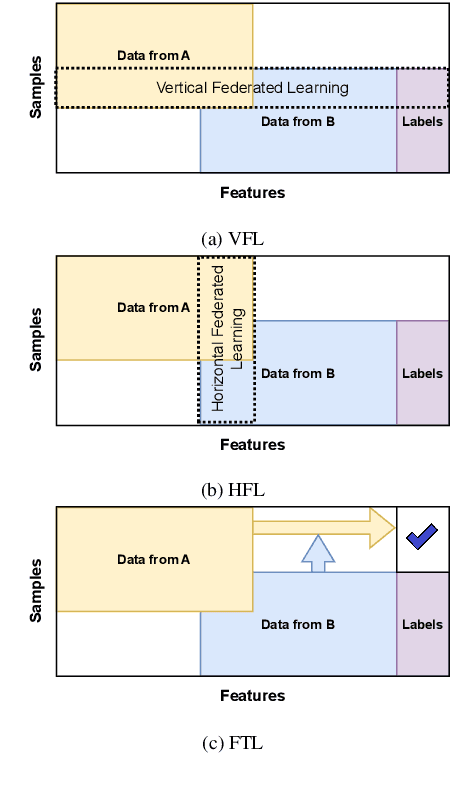

Dataset Distillation (DD) is a powerful technique for reducing large datasets into compact, representative synthetic datasets, accelerating Machine Learning training. However, traditional DD methods operate in a centralized manner, which poses significant privacy threats and reduces its applicability. To mitigate these risks, we propose a Secure Federated Data Distillation framework (SFDD) to decentralize the distillation process while preserving privacy.Unlike existing Federated Distillation techniques that focus on training global models with distilled knowledge, our approach aims to produce a distilled dataset without exposing local contributions. We leverage the gradient-matching-based distillation method, adapting it for a distributed setting where clients contribute to the distillation process without sharing raw data. The central aggregator iteratively refines a synthetic dataset by integrating client-side updates while ensuring data confidentiality. To make our approach resilient to inference attacks perpetrated by the server that could exploit gradient updates to reconstruct private data, we create an optimized Local Differential Privacy approach, called LDPO-RLD (Label Differential Privacy Obfuscation via Randomized Linear Dispersion). Furthermore, we assess the framework's resilience against malicious clients executing backdoor attacks and demonstrate robustness under the assumption of a sufficient number of participating clients. Our experimental results demonstrate the effectiveness of SFDD and that the proposed defense concretely mitigates the identified vulnerabilities, with minimal impact on the performance of the distilled dataset. By addressing the interplay between privacy and federation in dataset distillation, this work advances the field of privacy-preserving Machine Learning making our SFDD framework a viable solution for sensitive data-sharing applications.