 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Certified Malware Detection: Provable Guarantees Against Evasion Attacks
Apr 22, 2026Machine learning-based static malware detectors remain vulnerable to adversarial evasion techniques, such as metamorphic engine mutations. To address this vulnerability, we propose a certifiably robust malware detection framework based on randomized smoothing through feature ablation and targeted noise injection. During evaluation, our system analyzes an executable by generating multiple ablated variants, classifies them by using a smoothed classifier, and identifies the final label based on the majority vote. By analyzing the top-class voting distribution and the Wilson score interval, we derive a formal certificate that guarantees robustness within a specific radius against feature-space perturbations. We evaluate our approach by comparing the performance of the base classifier and the smoothed classifier on both clean executables and ablated variants generated using PyMetaEngine. Our results demonstrate that the proposed smoothed classifier successfully provides certifiable robustness against metamorphic evasion attacks without requiring modifications to the underlying machine learning architecture.
Security in LLM-as-a-Judge: A Comprehensive SoK
Mar 31, 2026LLM-as-a-Judge (LaaJ) is a novel paradigm in which powerful language models are used to assess the quality, safety, or correctness of generated outputs. While this paradigm has significantly improved the scalability and efficiency of evaluation processes, it also introduces novel security risks and reliability concerns that remain largely unexplored. In particular, LLM-based judges can become both targets of adversarial manipulation and instruments through which attacks are conducted, potentially compromising the trustworthiness of evaluation pipelines. In this paper, we present the first Systematization of Knowledge (SoK) focusing on the security aspects of LLM-as-a-Judge systems. We perform a comprehensive literature review across major academic databases, analyzing 863 works and selecting 45 relevant studies published between 2020 and 2026. Based on this study, we propose a taxonomy that organizes recent research according to the role played by LLM-as-a-Judge in the security landscape, distinguishing between attacks targeting LaaJ systems, attacks performed through LaaJ, defenses leveraging LaaJ for security purposes, and applications where LaaJ is used as an evaluation strategy in security-related domains. We further provide a comparative analysis of existing approaches, highlighting current limitations, emerging threats, and open research challenges. Our findings reveal significant vulnerabilities in LLM-based evaluation frameworks, as well as promising directions for improving their robustness and reliability. Finally, we outline key research opportunities that can guide the development of more secure and trustworthy LLM-as-a-Judge systems.
GShield: Mitigating Poisoning Attacks in Federated Learning
Dec 22, 2025Federated Learning (FL) has recently emerged as a revolutionary approach to collaborative training Machine Learning models. In particular, it enables decentralized model training while preserving data privacy, but its distributed nature makes it highly vulnerable to a severe attack known as Data Poisoning. In such scenarios, malicious clients inject manipulated data into the training process, thereby degrading global model performance or causing targeted misclassification. In this paper, we present a novel defense mechanism called GShield, designed to detect and mitigate malicious and low-quality updates, especially under non-independent and identically distributed (non-IID) data scenarios. GShield operates by learning the distribution of benign gradients through clustering and Gaussian modeling during an initial round, enabling it to establish a reliable baseline of trusted client behavior. With this benign profile, GShield selectively aggregates only those updates that align with the expected gradient patterns, effectively isolating adversarial clients and preserving the integrity of the global model. An extensive experimental campaign demonstrates that our proposed defense significantly improves model robustness compared to the state-of-the-art methods while maintaining a high accuracy of performance across both tabular and image datasets. Furthermore, GShield improves the accuracy of the targeted class by 43\% to 65\% after detecting malicious and low-quality clients.
Protecting Deep Neural Network Intellectual Property with Chaos-Based White-Box Watermarking
Dec 18, 2025The rapid proliferation of deep neural networks (DNNs) across several domains has led to increasing concerns regarding intellectual property (IP) protection and model misuse. Trained DNNs represent valuable assets, often developed through significant investments. However, the ease with which models can be copied, redistributed, or repurposed highlights the urgent need for effective mechanisms to assert and verify model ownership. In this work, we propose an efficient and resilient white-box watermarking framework that embeds ownership information into the internal parameters of a DNN using chaotic sequences. The watermark is generated using a logistic map, a well-known chaotic function, producing a sequence that is sensitive to its initialization parameters. This sequence is injected into the weights of a chosen intermediate layer without requiring structural modifications to the model or degradation in predictive performance. To validate ownership, we introduce a verification process based on a genetic algorithm that recovers the original chaotic parameters by optimizing the similarity between the extracted and regenerated sequences. The effectiveness of the proposed approach is demonstrated through extensive experiments on image classification tasks using MNIST and CIFAR-10 datasets. The results show that the embedded watermark remains detectable after fine-tuning, with negligible loss in model accuracy. In addition to numerical recovery of the watermark, we perform visual analyses using weight density plots and construct activation-based classifiers to distinguish between original, watermarked, and tampered models. Overall, the proposed method offers a flexible and scalable solution for embedding and verifying model ownership in white-box settings well-suited for real-world scenarios where IP protection is critical.
Secure Federated Data Distillation
Feb 19, 2025
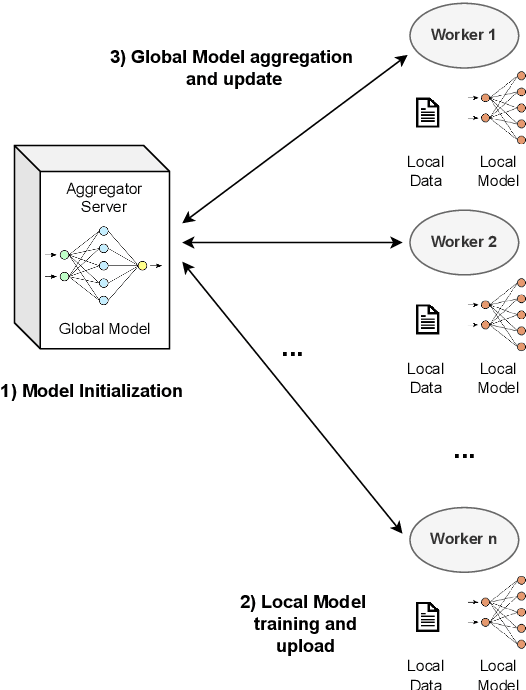

Dataset Distillation (DD) is a powerful technique for reducing large datasets into compact, representative synthetic datasets, accelerating Machine Learning training. However, traditional DD methods operate in a centralized manner, which poses significant privacy threats and reduces its applicability. To mitigate these risks, we propose a Secure Federated Data Distillation framework (SFDD) to decentralize the distillation process while preserving privacy.Unlike existing Federated Distillation techniques that focus on training global models with distilled knowledge, our approach aims to produce a distilled dataset without exposing local contributions. We leverage the gradient-matching-based distillation method, adapting it for a distributed setting where clients contribute to the distillation process without sharing raw data. The central aggregator iteratively refines a synthetic dataset by integrating client-side updates while ensuring data confidentiality. To make our approach resilient to inference attacks perpetrated by the server that could exploit gradient updates to reconstruct private data, we create an optimized Local Differential Privacy approach, called LDPO-RLD (Label Differential Privacy Obfuscation via Randomized Linear Dispersion). Furthermore, we assess the framework's resilience against malicious clients executing backdoor attacks and demonstrate robustness under the assumption of a sufficient number of participating clients. Our experimental results demonstrate the effectiveness of SFDD and that the proposed defense concretely mitigates the identified vulnerabilities, with minimal impact on the performance of the distilled dataset. By addressing the interplay between privacy and federation in dataset distillation, this work advances the field of privacy-preserving Machine Learning making our SFDD framework a viable solution for sensitive data-sharing applications.
Augmented Knowledge Graph Querying leveraging LLMs
Feb 03, 2025



Adopting Knowledge Graphs (KGs) as a structured, semantic-oriented, data representation model has significantly improved data integration, reasoning, and querying capabilities across different domains. This is especially true in modern scenarios such as Industry 5.0, in which the integration of data produced by humans, smart devices, and production processes plays a crucial role. However, the management, retrieval, and visualization of data from a KG using formal query languages can be difficult for non-expert users due to their technical complexity, thus limiting their usage inside industrial environments. For this reason, we introduce SparqLLM, a framework that utilizes a Retrieval-Augmented Generation (RAG) solution, to enhance the querying of Knowledge Graphs (KGs). SparqLLM executes the Extract, Transform, and Load (ETL) pipeline to construct KGs from raw data. It also features a natural language interface powered by Large Language Models (LLMs) to enable automatic SPARQL query generation. By integrating template-based methods as retrieved-context for the LLM, SparqLLM enhances query reliability and reduces semantic errors, ensuring more accurate and efficient KG interactions. Moreover, to improve usability, the system incorporates a dynamic visualization dashboard that adapts to the structure of the retrieved data, presenting the query results in an intuitive format. Rigorous experimental evaluations demonstrate that SparqLLM achieves high query accuracy, improved robustness, and user-friendly interaction with KGs, establishing it as a scalable solution to access semantic data.
KDk: A Defense Mechanism Against Label Inference Attacks in Vertical Federated Learning
Apr 18, 2024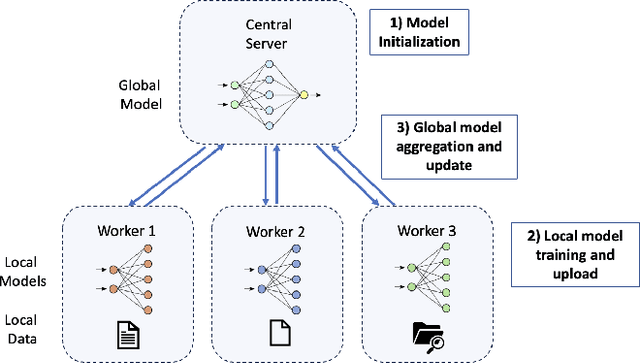
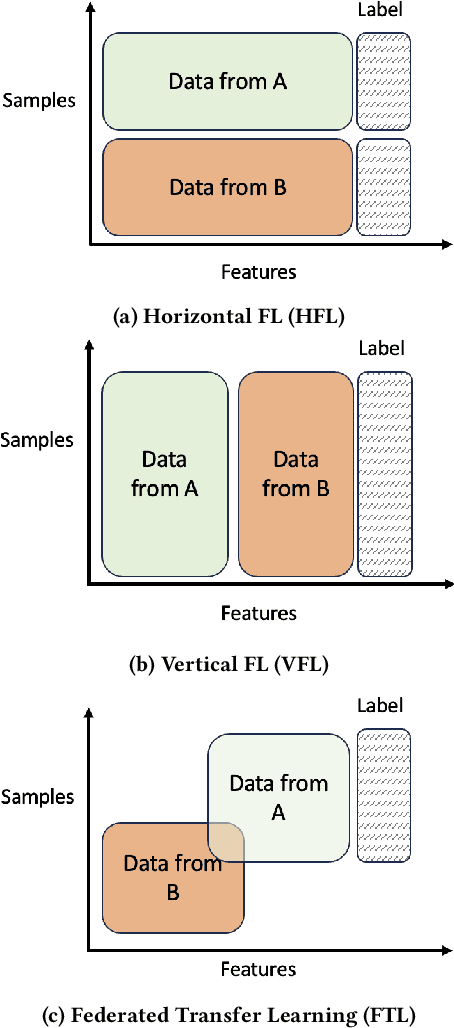
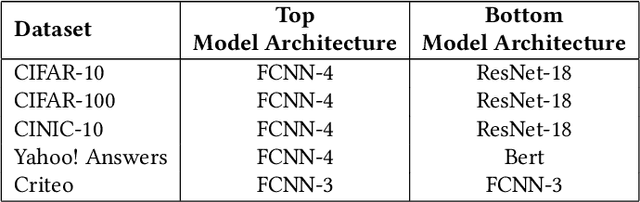
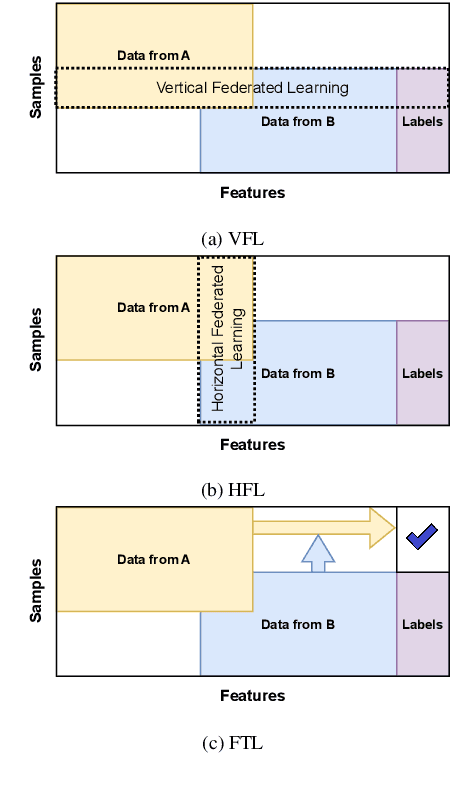
Vertical Federated Learning (VFL) is a category of Federated Learning in which models are trained collaboratively among parties with vertically partitioned data. Typically, in a VFL scenario, the labels of the samples are kept private from all the parties except for the aggregating server, that is the label owner. Nevertheless, recent works discovered that by exploiting gradient information returned by the server to bottom models, with the knowledge of only a small set of auxiliary labels on a very limited subset of training data points, an adversary can infer the private labels. These attacks are known as label inference attacks in VFL. In our work, we propose a novel framework called KDk, that combines Knowledge Distillation and k-anonymity to provide a defense mechanism against potential label inference attacks in a VFL scenario. Through an exhaustive experimental campaign we demonstrate that by applying our approach, the performance of the analyzed label inference attacks decreases consistently, even by more than 60%, maintaining the accuracy of the whole VFL almost unaltered.
A Deep Reinforcement Learning Approach for Security-Aware Service Acquisition in IoT
Apr 04, 2024The novel Internet of Things (IoT) paradigm is composed of a growing number of heterogeneous smart objects and services that are transforming architectures and applications, increasing systems' complexity, and the need for reliability and autonomy. In this context, both smart objects and services are often provided by third parties which do not give full transparency regarding the security and privacy of the features offered. Although machine-based Service Level Agreements (SLA) have been recently leveraged to establish and share policies in Cloud-based scenarios, and also in the IoT context, the issue of making end users aware of the overall system security levels and the fulfillment of their privacy requirements through the provision of the requested service remains a challenging task. To tackle this problem, we propose a complete framework that defines suitable levels of privacy and security requirements in the acquisition of services in IoT, according to the user needs. Through the use of a Reinforcement Learning based solution, a user agent, inside the environment, is trained to choose the best smart objects granting access to the target services. Moreover, the solution is designed to guarantee deadline requirements and user security and privacy needs. Finally, to evaluate the correctness and the performance of the proposed approach we illustrate an extensive experimental analysis.
Privacy-Preserving in Blockchain-based Federated Learning Systems
Jan 07, 2024
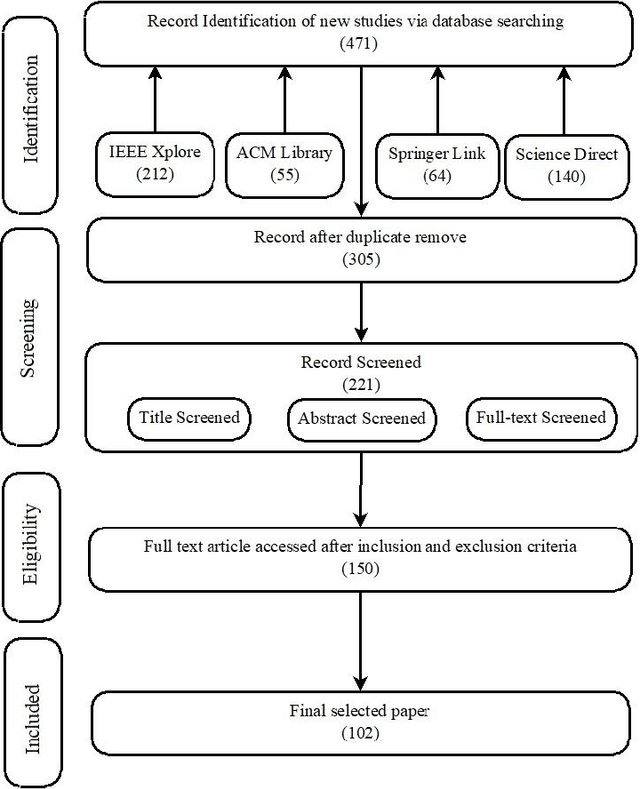

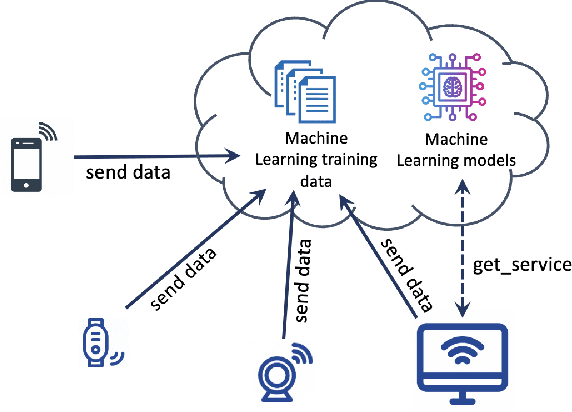
Federated Learning (FL) has recently arisen as a revolutionary approach to collaborative training Machine Learning models. According to this novel framework, multiple participants train a global model collaboratively, coordinating with a central aggregator without sharing their local data. As FL gains popularity in diverse domains, security, and privacy concerns arise due to the distributed nature of this solution. Therefore, integrating this strategy with Blockchain technology has been consolidated as a preferred choice to ensure the privacy and security of participants. This paper explores the research efforts carried out by the scientific community to define privacy solutions in scenarios adopting Blockchain-Enabled FL. It comprehensively summarizes the background related to FL and Blockchain, evaluates existing architectures for their integration, and the primary attacks and possible countermeasures to guarantee privacy in this setting. Finally, it reviews the main application scenarios where Blockchain-Enabled FL approaches have been proficiently applied. This survey can help academia and industry practitioners understand which theories and techniques exist to improve the performance of FL through Blockchain to preserve privacy and which are the main challenges and future directions in this novel and still under-explored context. We believe this work provides a novel contribution respect to the previous surveys and is a valuable tool to explore the current landscape, understand perspectives, and pave the way for advancements or improvements in this amalgamation of Blockchain and Federated Learning.
A Novel IoT Trust Model Leveraging Fully Distributed Behavioral Fingerprinting and Secure Delegation
Oct 02, 2023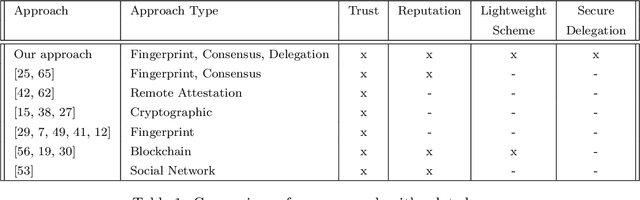
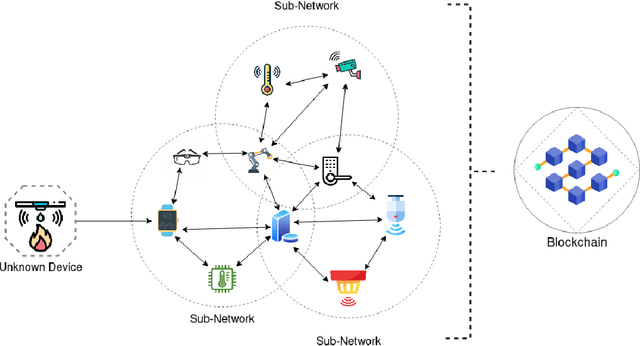

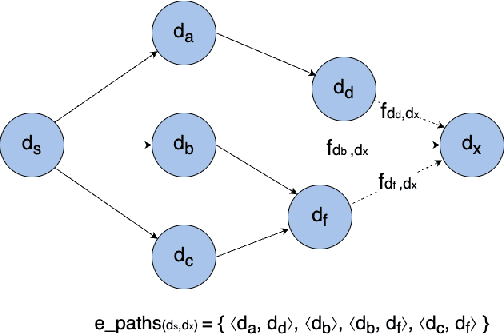
With the number of connected smart devices expected to constantly grow in the next years, Internet of Things (IoT) solutions are experimenting a booming demand to make data collection and processing easier. The ability of IoT appliances to provide pervasive and better support to everyday tasks, in most cases transparently to humans, is also achieved through the high degree of autonomy of such devices. However, the higher the number of new capabilities and services provided in an autonomous way, the wider the attack surface that exposes users to data hacking and lost. In this scenario, many critical challenges arise also because IoT devices have heterogeneous computational capabilities (i.e., in the same network there might be simple sensors/actuators as well as more complex and smart nodes). In this paper, we try to provide a contribution in this setting, tackling the non-trivial issues of equipping smart things with a strategy to evaluate, also through their neighbors, the trustworthiness of an object in the network before interacting with it. To do so, we design a novel and fully distributed trust model exploiting devices' behavioral fingerprints, a distributed consensus mechanism and the Blockchain technology. Beyond the detailed description of our framework, we also illustrate the security model associated with it and the tests carried out to evaluate its correctness and performance.