 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Models Share Safety Representations? Cross-Model Steering for Safe Visual Generation
Jun 03, 2026Recent progress in generative modeling has made safety control a central challenge, yet existing approaches remain largely model-specific, requiring retraining or tailored interventions for each new architecture. In this work, we ask whether safety can be represented as a portable latent direction, learned once and reused across heterogeneous generators. We introduce the first framework for cross-model safety steering, in which a safety direction is estimated in a source LLM from paired safe-unsafe prompts, transported to a target generator through a lightweight alignment fitted on benign data alone, and applied at inference time. Crucially, our pipeline never accesses unsafe data on the target side, isolating whether safety can be transferred through shared representation geometry. Beyond a single global direction, we also identify a multi-vector extension that captures category-specific safety behaviors, enabling more selective control. We evaluate our approach in text-to-image and text-to-video generation across diverse source-target model pairs. Across models, transferred safety directions achieve ASR reduction and CLIP-Score/FID trade-offs comparable to directions learned natively on the target model using unsafe data, while requiring no target-side unsafe data. This indicates that safety improvements do not come at the expense of generation quality. Our results point to a modular view of safety: safety-relevant behavior is not purely model-local, but can be controlled through latent directions that persist across models. This suggests a new path toward lightweight, reusable safety mechanisms that do not require target-side unsafe data.
Few Channels Draw The Whole Picture: Revealing Massive Activations in Diffusion Transformers
May 13, 2026Diffusion Transformers (DiTs) and related flow-based architectures are now among the strongest text-to-image generators, yet the internal mechanisms through which prompts shape image semantics remain poorly understood. In this work, we study massive activations: a small subset of hidden-state channels whose responses are consistently much larger than the rest. We show that, despite their sparsity, these few channels effectively draw the whole picture, in three complementary senses. First, they are functionally critical: a controlled disruption probe that zeroes the massive channels causes a sharp collapse in generation quality, while disrupting an equally-sized set of low-statistic channels has marginal effect. Second, they are spatially organized: restricting image-stream tokens to massive channels and clustering them yields coherent partitions that closely align with the main subject and salient regions, exposing a structured spatial code hidden inside an apparently outlier-like subspace. Third, they are transferable: transporting massive activations from one prompt-conditioned trajectory into another, shifts the final image toward the source prompt while preserving substantial content from the target, producing localized semantic interpolation rather than unstructured pixel blending. We exploit this property in two use cases: text-conditioned and image-conditioned semantic transport, where massive activations transport enables prompt interpolation and subject-driven generation without any additional training. Together, these results recast massive activations not as activation anomalies, but as a sparse prompt-conditioned carrier subspace that organizes and controls semantic information in modern DiT models.
RaTA-Tool: Retrieval-based Tool Selection with Multimodal Large Language Models
Apr 16, 2026Tool learning with foundation models aims to endow AI systems with the ability to invoke external resources -- such as APIs, computational utilities, and specialized models -- to solve complex tasks beyond the reach of standalone language generation. While recent advances in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have expanded their reasoning and perception capabilities, existing tool-use methods are predominantly limited to text-only inputs and closed-world settings. Consequently, they struggle to interpret multimodal user instructions and cannot generalize to tools unseen during training. In this work, we introduce RaTA-Tool, a novel framework for open-world multimodal tool selection. Rather than learning direct mappings from user queries to fixed tool identifiers, our approach enables an MLLM to convert a multimodal query into a structured task description and subsequently retrieve the most appropriate tool by matching this representation against semantically rich, machine-readable tool descriptions. This retrieval-based formulation naturally supports extensibility to new tools without retraining. To further improve alignment between task descriptions and tool selection, we incorporate a preference-based optimization stage using Direct Preference Optimization (DPO). To support research in this setting, we also introduce the first dataset for open-world multimodal tool use, featuring standardized tool descriptions derived from Hugging Face model cards. Extensive experiments demonstrate that our approach significantly improves tool-selection performance, particularly in open-world, multimodal scenarios.
Look Twice: Training-Free Evidence Highlighting in Multimodal Large Language Models
Apr 01, 2026Answering questions about images often requires combining visual understanding with external knowledge. Multimodal Large Language Models (MLLMs) provide a natural framework for this setting, but they often struggle to identify the most relevant visual and textual evidence when answering knowledge-intensive queries. In such scenarios, models must integrate visual cues with retrieved textual evidence that is often noisy or only partially relevant, while also localizing fine-grained visual information in the image. In this work, we introduce Look Twice (LoT), a training-free inference-time framework that improves how pretrained MLLMs utilize multimodal evidence. Specifically, we exploit the model attention patterns to estimate which visual regions and retrieved textual elements are relevant to a query, and then generate the answer conditioned on this highlighted evidence. The selected cues are highlighted through lightweight prompt-level markers that encourage the model to re-attend to the relevant evidence during generation. Experiments across multiple knowledge-based VQA benchmarks show consistent improvements over zero-shot MLLMs. Additional evaluations on vision-centric and hallucination-oriented benchmarks further demonstrate that visual evidence highlighting alone improves model performance in settings without textual context, all without additional training or architectural modifications. Source code will be publicly released.
Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
Recurrence Meets Transformers for Universal Multimodal Retrieval
Sep 10, 2025


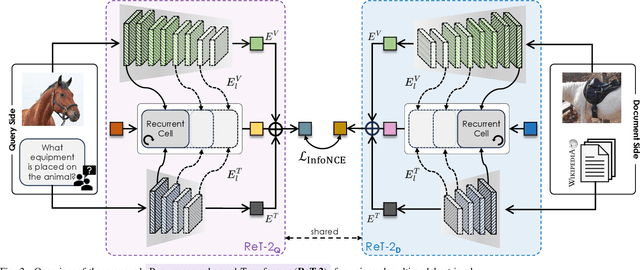
With the rapid advancement of multimodal retrieval and its application in LLMs and multimodal LLMs, increasingly complex retrieval tasks have emerged. Existing methods predominantly rely on task-specific fine-tuning of vision-language models and are limited to single-modality queries or documents. In this paper, we propose ReT-2, a unified retrieval model that supports multimodal queries, composed of both images and text, and searches across multimodal document collections where text and images coexist. ReT-2 leverages multi-layer representations and a recurrent Transformer architecture with LSTM-inspired gating mechanisms to dynamically integrate information across layers and modalities, capturing fine-grained visual and textual details. We evaluate ReT-2 on the challenging M2KR and M-BEIR benchmarks across different retrieval configurations. Results demonstrate that ReT-2 consistently achieves state-of-the-art performance across diverse settings, while offering faster inference and reduced memory usage compared to prior approaches. When integrated into retrieval-augmented generation pipelines, ReT-2 also improves downstream performance on Encyclopedic-VQA and InfoSeek datasets. Our source code and trained models are publicly available at: https://github.com/aimagelab/ReT-2
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Mar 19, 2025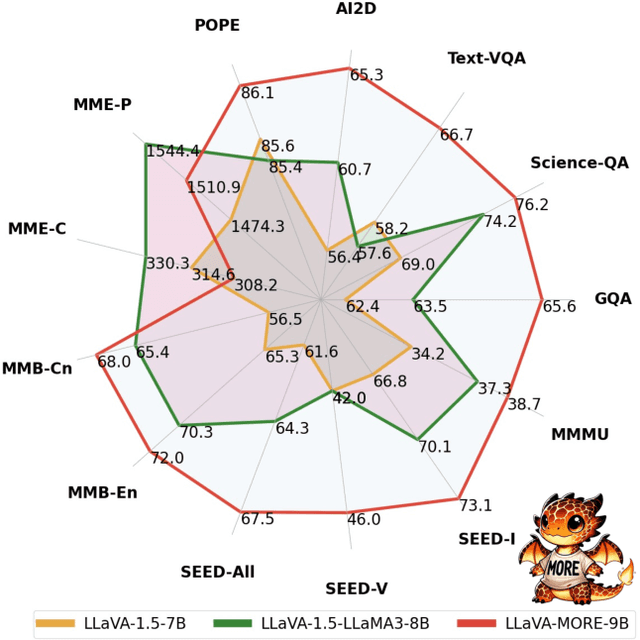
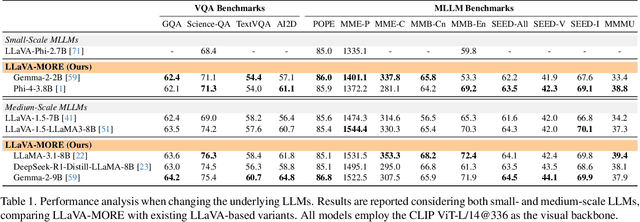
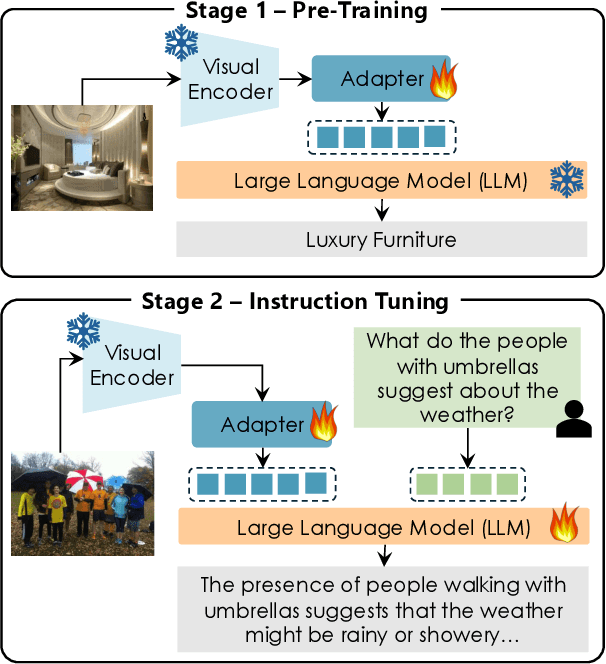
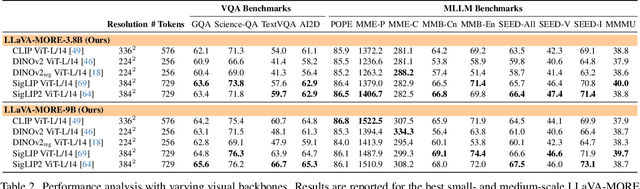
Recent progress in Multimodal Large Language Models (MLLMs) has highlighted the critical roles of both the visual backbone and the underlying language model. While prior work has primarily focused on scaling these components to billions of parameters, the trade-offs between model size, architecture, and performance remain underexplored. Additionally, inconsistencies in training data and evaluation protocols have hindered direct comparisons, making it difficult to derive optimal design choices. In this paper, we introduce LLaVA-MORE, a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. Our analysis systematically explores both small- and medium-scale LLMs -- including Phi-4, LLaMA-3.1, and Gemma-2 -- to evaluate multimodal reasoning, generation, and instruction following, while examining the relationship between model size and performance. Beyond evaluating the LLM impact on final results, we conduct a comprehensive study of various visual encoders, ranging from CLIP-based architectures to alternatives such as DINOv2, SigLIP, and SigLIP2. Additional experiments investigate the effects of increased image resolution and variations in pre-training datasets. Overall, our results provide insights into the design of more effective MLLMs, offering a reproducible evaluation framework that facilitates direct comparisons and can guide future model development. Our source code and trained models are publicly available at: https://github.com/aimagelab/LLaVA-MORE.
Image Captioning Evaluation in the Age of Multimodal LLMs: Challenges and Future Perspectives
Mar 18, 2025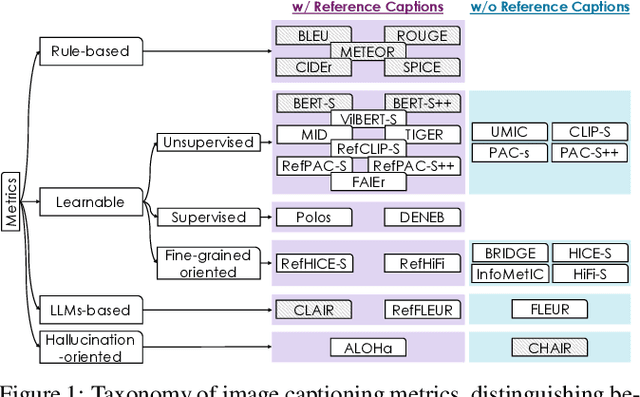
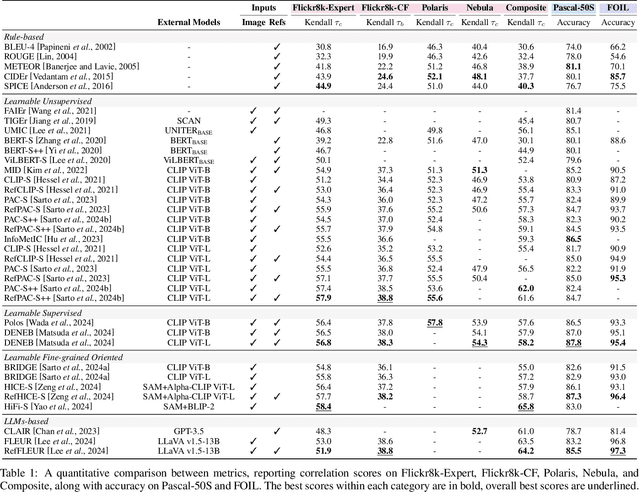
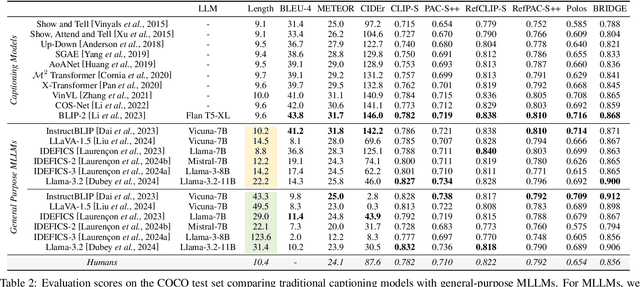
The evaluation of machine-generated image captions is a complex and evolving challenge. With the advent of Multimodal Large Language Models (MLLMs), image captioning has become a core task, increasing the need for robust and reliable evaluation metrics. This survey provides a comprehensive overview of advancements in image captioning evaluation, analyzing the evolution, strengths, and limitations of existing metrics. We assess these metrics across multiple dimensions, including correlation with human judgment, ranking accuracy, and sensitivity to hallucinations. Additionally, we explore the challenges posed by the longer and more detailed captions generated by MLLMs and examine the adaptability of current metrics to these stylistic variations. Our analysis highlights some limitations of standard evaluation approaches and suggests promising directions for future research in image captioning assessment.
Recurrence-Enhanced Vision-and-Language Transformers for Robust Multimodal Document Retrieval
Mar 03, 2025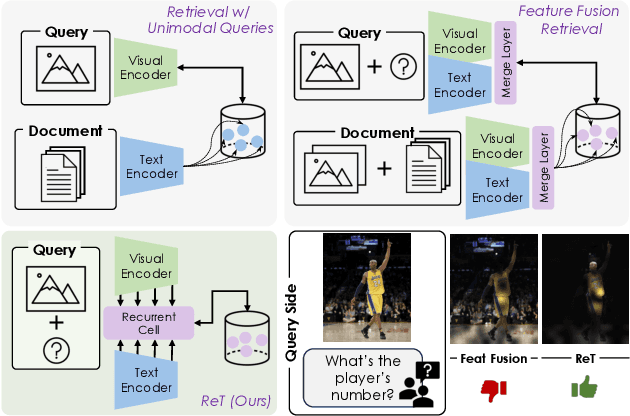
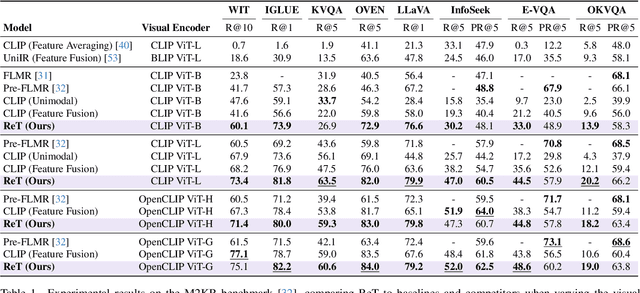
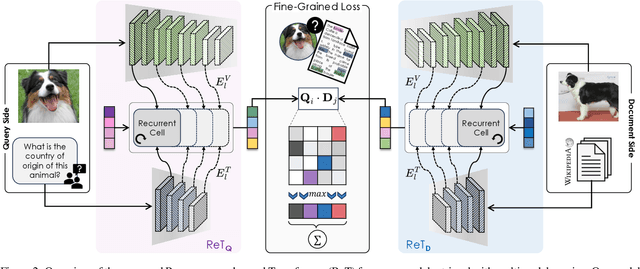
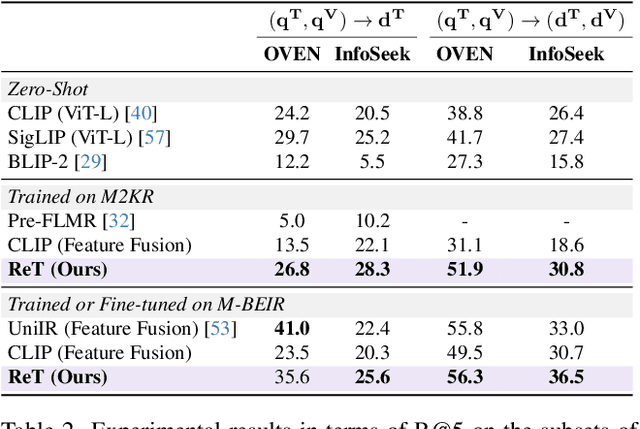
Cross-modal retrieval is gaining increasing efficacy and interest from the research community, thanks to large-scale training, novel architectural and learning designs, and its application in LLMs and multimodal LLMs. In this paper, we move a step forward and design an approach that allows for multimodal queries, composed of both an image and a text, and can search within collections of multimodal documents, where images and text are interleaved. Our model, ReT, employs multi-level representations extracted from different layers of both visual and textual backbones, both at the query and document side. To allow for multi-level and cross-modal understanding and feature extraction, ReT employs a novel Transformer-based recurrent cell that integrates both textual and visual features at different layers, and leverages sigmoidal gates inspired by the classical design of LSTMs. Extensive experiments on M2KR and M-BEIR benchmarks show that ReT achieves state-of-the-art performance across diverse settings. Our source code and trained models are publicly available at https://github.com/aimagelab/ReT.
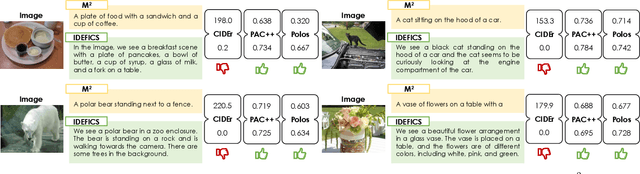
Positive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
Oct 09, 2024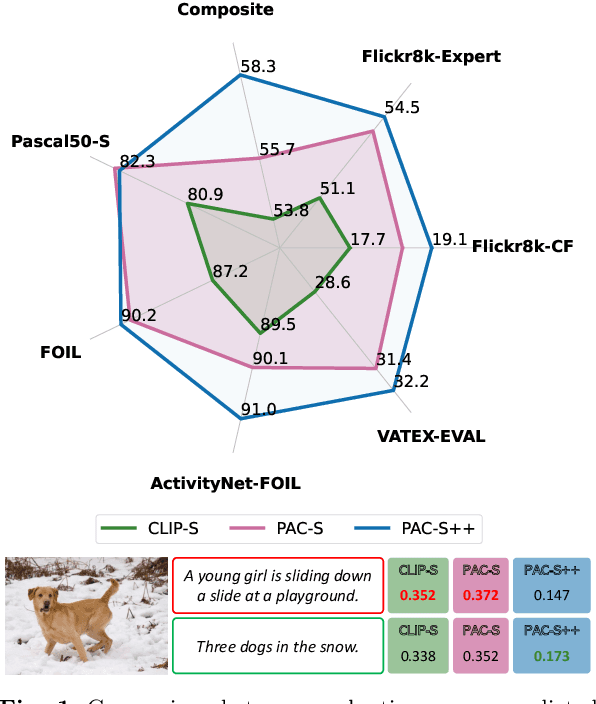
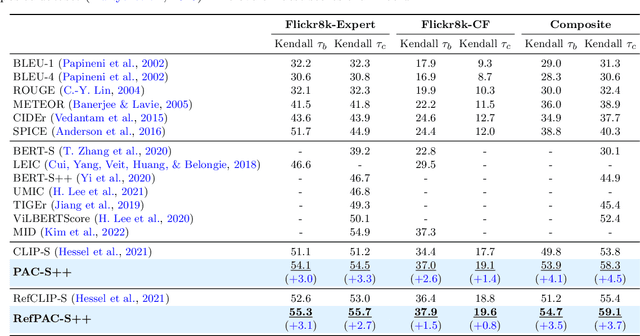
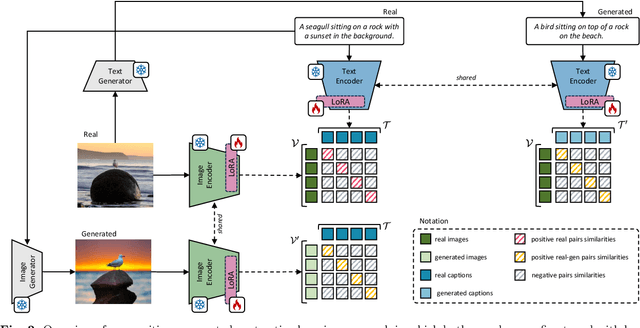
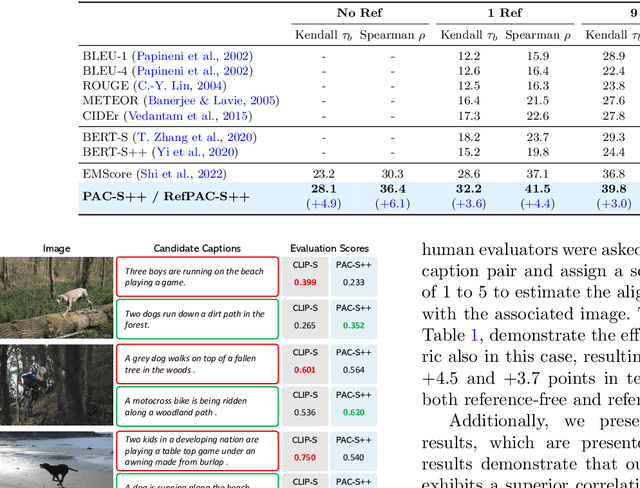
Despite significant advancements in caption generation, existing evaluation metrics often fail to capture the full quality or fine-grained details of captions. This is mainly due to their reliance on non-specific human-written references or noisy pre-training data. Still, finding an effective metric is crucial not only for captions evaluation but also for the generation phase. Metrics can indeed play a key role in the fine-tuning stage of captioning models, ultimately enhancing the quality of the generated captions. In this paper, we propose PAC-S++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we also apply PAC-S++ as a reward in the Self-Critical Sequence Training (SCST) stage typically employed to fine-tune captioning models. Extensive experiments on different image and video datasets highlight the effectiveness of PAC-S++ compared to popular metrics for the task, including its sensitivity to object hallucinations. Furthermore, we show that integrating PAC-S++ into the fine-tuning stage of a captioning model results in semantically richer captions with fewer repetitions and grammatical errors. Evaluations on out-of-domain benchmarks further demonstrate the efficacy of our fine-tuning approach in enhancing model capabilities. Source code and trained models are publicly available at: https://github.com/aimagelab/pacscore.