 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Mar 19, 2025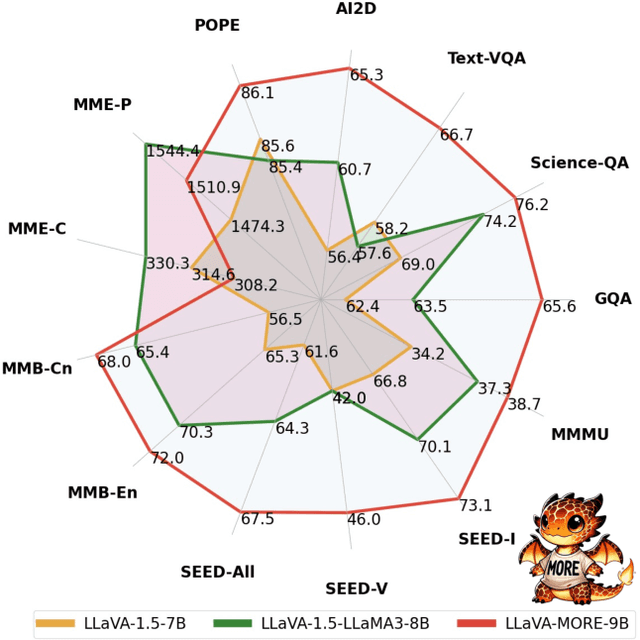
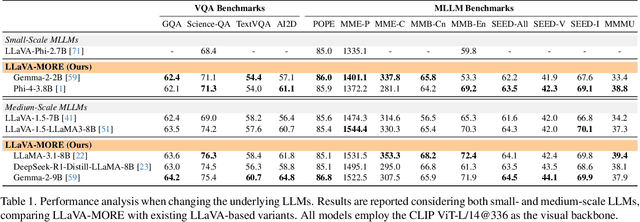
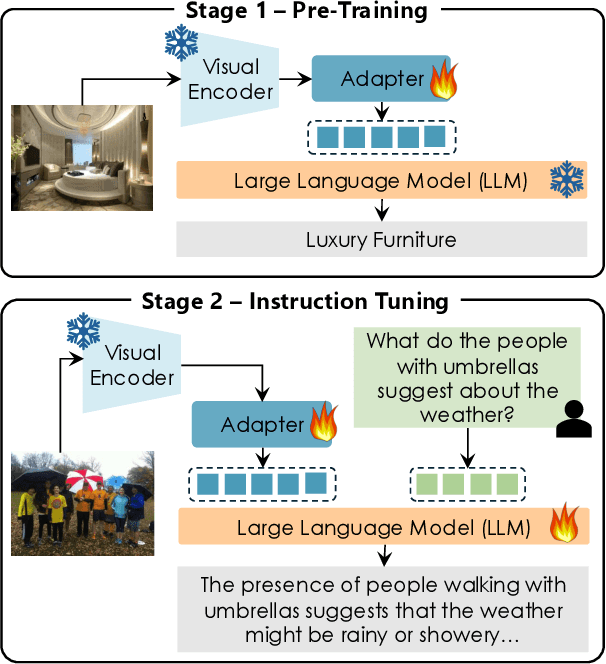
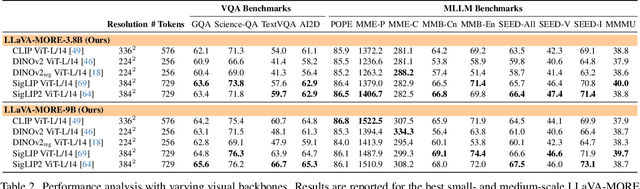
Recent progress in Multimodal Large Language Models (MLLMs) has highlighted the critical roles of both the visual backbone and the underlying language model. While prior work has primarily focused on scaling these components to billions of parameters, the trade-offs between model size, architecture, and performance remain underexplored. Additionally, inconsistencies in training data and evaluation protocols have hindered direct comparisons, making it difficult to derive optimal design choices. In this paper, we introduce LLaVA-MORE, a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. Our analysis systematically explores both small- and medium-scale LLMs -- including Phi-4, LLaMA-3.1, and Gemma-2 -- to evaluate multimodal reasoning, generation, and instruction following, while examining the relationship between model size and performance. Beyond evaluating the LLM impact on final results, we conduct a comprehensive study of various visual encoders, ranging from CLIP-based architectures to alternatives such as DINOv2, SigLIP, and SigLIP2. Additional experiments investigate the effects of increased image resolution and variations in pre-training datasets. Overall, our results provide insights into the design of more effective MLLMs, offering a reproducible evaluation framework that facilitates direct comparisons and can guide future model development. Our source code and trained models are publicly available at: https://github.com/aimagelab/LLaVA-MORE.
Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering
Nov 25, 2024



Multimodal LLMs (MLLMs) are the natural extension of large language models to handle multimodal inputs, combining text and image data. They have recently garnered attention due to their capability to address complex tasks involving both modalities. However, their effectiveness is limited to the knowledge acquired during training, which restricts their practical utility. In this work, we introduce a novel method to enhance the adaptability of MLLMs by integrating external knowledge sources. Our proposed model, Reflective LLaVA (ReflectiVA), utilizes reflective tokens to dynamically determine the need for external knowledge and predict the relevance of information retrieved from an external database. Tokens are trained following a two-stage two-model training recipe. This ultimately enables the MLLM to manage external knowledge while preserving fluency and performance on tasks where external knowledge is not needed. Through our experiments, we demonstrate the efficacy of ReflectiVA for knowledge-based visual question answering, highlighting its superior performance compared to existing methods. Source code and trained models are publicly available at https://github.com/aimagelab/ReflectiVA.
Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities
Jul 29, 2024Discerning between authentic content and that generated by advanced AI methods has become increasingly challenging. While previous research primarily addresses the detection of fake faces, the identification of generated natural images has only recently surfaced. This prompted the recent exploration of solutions that employ foundation vision-and-language models, like CLIP. However, the CLIP embedding space is optimized for global image-to-text alignment and is not inherently designed for deepfake detection, neglecting the potential benefits of tailored training and local image features. In this study, we propose CoDE (Contrastive Deepfake Embeddings), a novel embedding space specifically designed for deepfake detection. CoDE is trained via contrastive learning by additionally enforcing global-local similarities. To sustain the training of our model, we generate a comprehensive dataset that focuses on images generated by diffusion models and encompasses a collection of 9.2 million images produced by using four different generators. Experimental results demonstrate that CoDE achieves state-of-the-art accuracy on the newly collected dataset, while also showing excellent generalization capabilities to unseen image generators. Our source code, trained models, and collected dataset are publicly available at: https://github.com/aimagelab/CoDE.
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Apr 23, 2024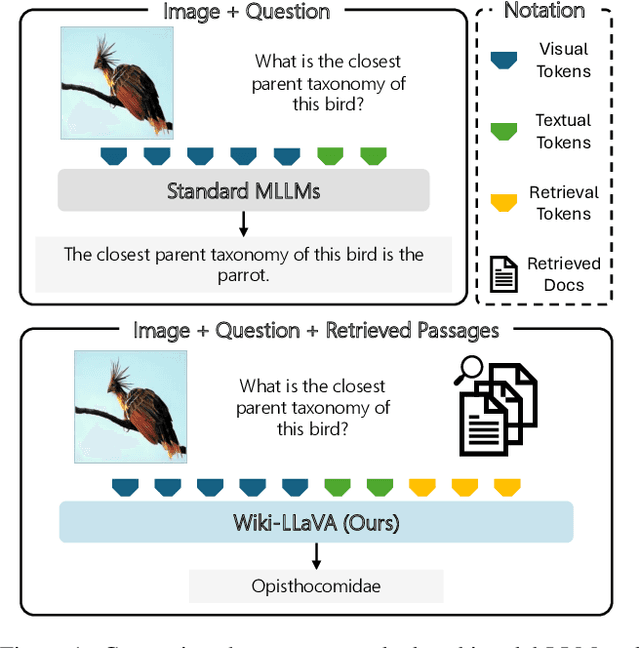
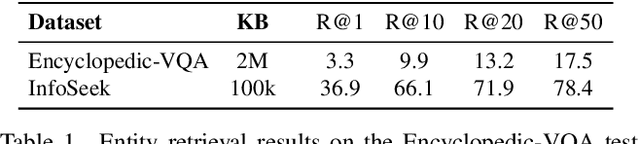


Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
The (R)Evolution of Multimodal Large Language Models: A Survey
Feb 19, 2024Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, both as input and output, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Removing NSFW Concepts from Vision-and-Language Models for Text-to-Image Retrieval and Generation
Nov 27, 2023Vision-and-Language models such as CLIP have demonstrated remarkable effectiveness across a wide range of tasks. However, these models are typically trained on web-scale data, which can introduce inappropriate content and lead to the development of unsafe and biased behavior. This, in turn, hampers their applicability in sensitive and trustworthy contexts and could raise significant concern in their adoption. To overcome these limitations, we introduce a methodology to make Vision-and-Language models safer by removing their sensitivity to not-safe-for-work concepts. We show how this can be done by distilling from a large language model which converts between safe and unsafe sentences and which is fine-tuned starting from just 100 manually-curated pairs. We conduct extensive experiments on the resulting embedding space for both retrieval and text-to-image generation, where we show that our model can also be properly employed with pre-trained image generators. Our source code and trained models are available at: https://github.com/aimagelab/safe-clip.